Running yolov5 code reports an error
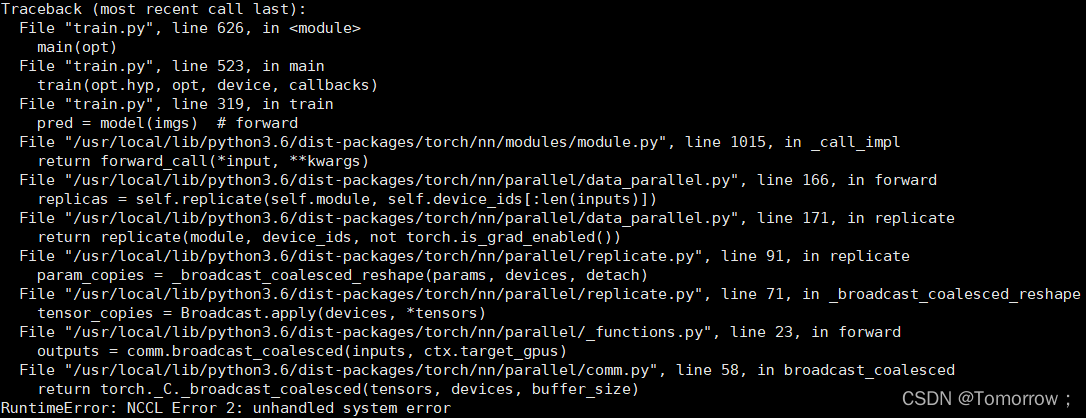
find nccl position according to the error reminder
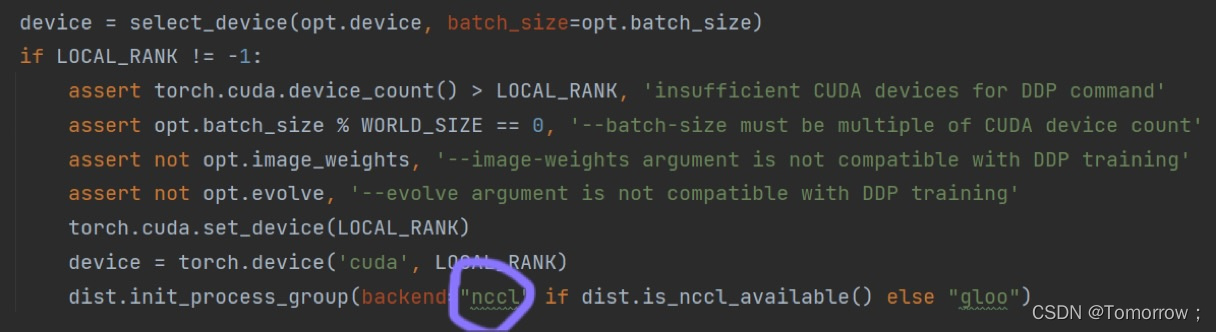
then it reacts that it is a problem of calling GPU, so it is changed to single GPU training

so it can run perfectly.
Running yolov5 code reports an error
find nccl position according to the error reminder
then it reacts that it is a problem of calling GPU, so it is changed to single GPU training
so it can run perfectly.