Question
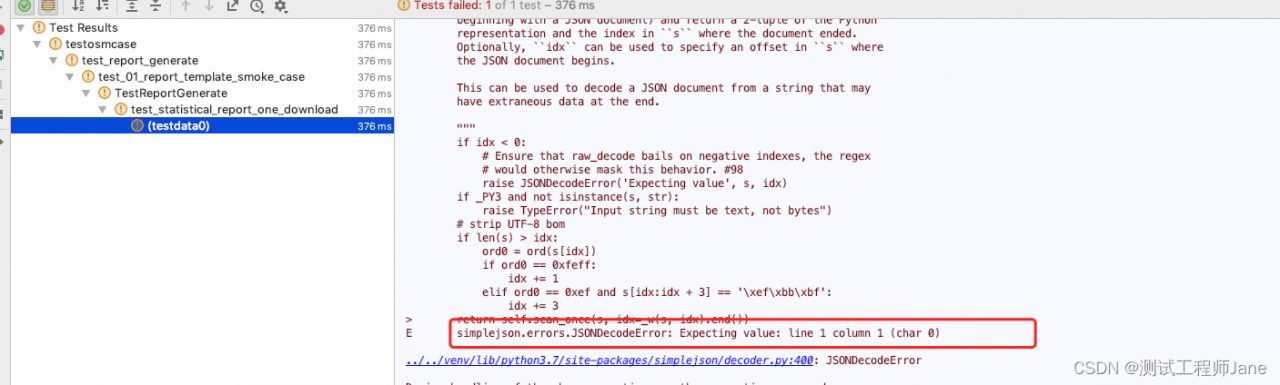
The single card training is very fast. When it comes to eval, it doesn’t move after running a batch, and there is no error.
Tried, still not moving
1, change the pin_memory of valid_loader to False. if it is True, it will automatically load the data into pin_memory, which speeds up the data
transfer speed to GPU.
2, change num_workers to 1, some people say too many workers may lead to multi-process interlock, can reduce or not
Final Solution:
valid_loader:
pin_memory = true # this is very important. Before, people on the Internet said that changing false might solve the problem. My experiment proved that if you do not work, you can run normally by changing back to true.
num_workers=4
batch_size=8
train_loader:
pin_memory=True
num_workers=4
batch_size = 8
these parameters are the same as valid_loader
In general, first of all, the pin_memory of valid_loader is kept True, which is well understood, the data is automatically loaded into pin_memory, which speeds up the data transfer to the GPU and naturally speeds up the inference process. Then, the number of workers and batch_size is reduced, and both valid_loader and train_loader are reduced. pin_memory of train_loader is also kept True.