Description:
Because many test environments are installed on this Ubuntu system, but due to the restart or power failure of the virtual server, every time the IP changes, the environment must be updated, so the ip of the environment needs to be configured as static, once and for all.
According to the previous experience of configuring Ubuntu static ip, directly vi /etc/network/interfaces configured static ip under this file, and it did not take effect after resetting the network.
So I checked the ubuntu version, it was 18.04, and Baidu found that “ubuntu has given up the fixed IP configuration in /etc/network/interfaces since 17.10. Even the configuration will not take effect. Instead, it is changed to netplan and the configuration is written In /etc/netplan/01-netcfg.yaml or a yaml file with a similar name”, so I configured according to the method found, but I encountered a lot of errors and almost vomited blood. Write down the errors I encountered here.
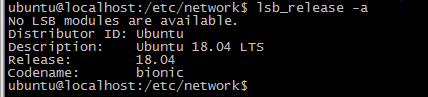
1, the beginning of the configuration is as follows: in the implementation apply netplan error message occurs Invalid YAML at //etc/netplan/01-netcfg.yaml line 11 column 11 : mapping values are not allowed in this context
Solution: yaml is a hierarchical structure and needs to be indented. A colon (:) means a dictionary, a hyphen (-) means a list, and there must be a space after the colon.
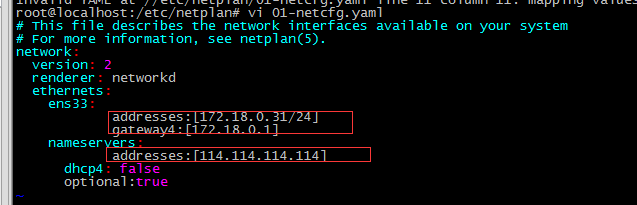
2. After adding a space after the colon (as shown below), execute netplan apply and report an error: Invalid YAML at //etc/netplan/01-netcfg.yaml line 11 column 6: did not find expected key
Solution: nameservers should be the fourth layer like gateway4, and the addresses after nameservers should be the fifth layer
The correct number of layers is as follows:
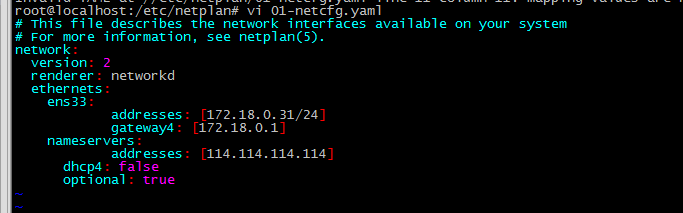
3. After solving according to the above method, execute netplan apply and report an error as shown below : Error in network definition //etc/netplan/01-netcfg.yaml line 8 column 16: expected scalar
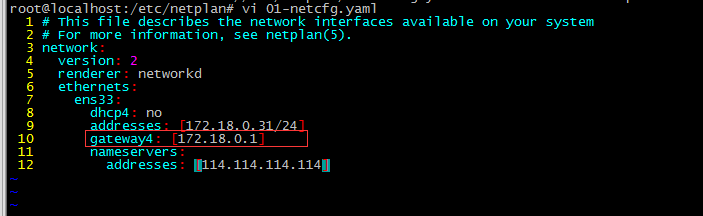
Solution: The address of gateway4 does not have square brackets. After the modification, restart the network service and it will be normal ( netplan apply )
So the correct configuration format should be as follows: In this way, the static ip is successfully configured
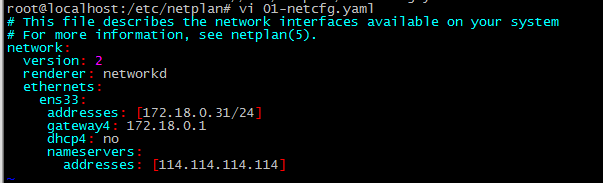
Errors that I did not encounter: