The kernel module local_clients is used to listen for DHCP packages and write the host name, IP, MAC, etc to file /proc/local_clients/local_clients_info, and the Webserver parses this question. MyPhone
/TMP # cat /proc/local_clients/local_clients_info
58-7f-57-8b-bc-0d 192.168.0.100 myPhone
now we need to improve this module by adding monitoring DNS messages to determine the IP and MAC of the host connected to AP. The result is written to /proc/local_clients/local_clients_info, and the problem is resolved in user space. If an entry with an UNKNOWN hostname is found, the hostname is obtained through the user program client_mGMT via NBNS or MDNS.
/TMP # cat /proc/local_clients/local_clients_info
14-cc-20-16-fb-da 192.168.0.110 UNKNOWN
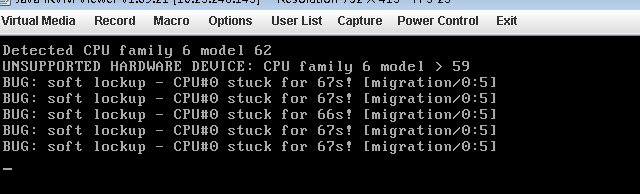
Problem: The function of resolving host name was realized, but it took more than 2 hours to run, and the serial port appeared abnormal printing as follows:
[3419.912000] BUG: scheduling while atomic:client_mgmt/1051/0x00000100
[3419.916000] Modules linked in: Umac ath_dev(P)ath_rate_atheros(P) ath_hal(P) asf(P) adf(P) athrs_gmac local_clients
[3419.928000] Cpu 0
[3419.932000]
0:00 000000000000010000000000000000 [3419.936000]
4:000041 832e4500 000000fe 23c637bb
[3419.944000]
And b9aca00129b0ea4c4ec4e0cfffffff8 [3419.948000]
12 :fffffffe 592f6656 00000004031a4
[3419.952000]
16:00 000 d5b832d0000000010000041a1a8 [3419.960000]
20 :825c3e98 000000041a1a8 00001000
[3419.964000]
00000 f800b22c8 24:00 [3419.972000]
28 :825c2000 825c3e50 825c3f10 832c42c0
[3419.976000] Hi :000fd669
[3419.980000] Lo :2c3458d0
[3419.980000] epc :832d42d8 remove_timeout_stas+0x4c/0x8c [local_clients]
[local_clients] 3419.988000] Tainted: P
[3419.992000] ra: 832 d42c0 remove_timeout_stas + 0 x34/0 x8c [local_clients]
[3420.000000] Status: 1000 ff03 KERNEL EXL IE
[3420.004000] Cause: PrId :00019374 (MIPS 24Kc)
~ #
~ # ps
PID USER VSZ STAT COMMAND
1 root 1512 S init
2 root 0 SW< [kthreadd]
3 root 0 SW< [ksoftirqd/0]
4 root 0 SW< [events/0]
5 root 0 SW< [khelper]
6 root 0 SW< [async/mgr]
7 root 0 SW< [kblockd/0]
8 root 0 SW [pdflush]
9 root 0 SW [pdflush]
10 root 0 SW< [kswapd0]
13 root 0 SW< [mtdblockd]
1059 root 1512 S sh -c cat /proc/local_clients/local_clients_info >/TMP /log.txt
1060 root 1504 D cat /proc/local_clients/local_clients_info
1071 root 3716 S /usr/bin/httpserver
1072 root 1512 S sh-c client_mgmt -s 192.168.0.101
1073 root 1196 D Client_mgmt-s 192.168.0.101
1074 root 1512 s sh-c cat /proc/local_clients/local_clients_info >/TMP /log.txt
1075 root 1504 D cat /proc/local_clients/local_clients_info
1164 root 3716 S /usr/bin/httpserver
1165 root 1512 S sh-c client_mgmt-s 192.168.0.101
1166 root 1196 D /usr/bin/httpserver
1165 root 1512 S sh-c client_mgmt-s 192.168.0.101
1166 root 1196 D Client_mgmt-s 192.168.0.101
1167 root 1512 s sh-c cat /proc/local_clients/local_clients_info >/TMP /log.txt
1168 root 1504 D cat /proc/local_clients/local_clients_info
1225 root 3716 S /usr/bin/httpserver
1226 root 1512 S sh-c client_mgmt-s 192.168.0.101
1227 root 1196 D /usr/bin/httpserver Client_mgmt-s 192.168.0.101
1228 root 1512 s sh-c cat /proc/local_clients/local_clients_info >/TMP /log.txt
1229 root 1504 D cat /proc/local_clients/local_clients_info
1441 root 3716 S /usr/bin/httpserver
1442 root 1512 S sh-c client_mgmt -s 192.168.0.101
1443 root 1196 D Client_mgmt-s 192.168.0.101
1444 root 1512 s sh-c cat /proc/local_clients/local_clients_info > /tmp/log.txt
1445 root 1504 D cat /proc/local_clients/local_clients_info
Remove_timeout_stas is an aging operation on the global variable l_clientS_info_list. The whole process is protected by a MUtex. It is suspected to be a mutex deadlock, but when I check the code, I find no place where unlock does not return. A special tip found in the logs: Scheduling Whileatomic; Search the key word, found that article: http://blog.csdn.net/cfy_phonex/article/details/12090943; When the Linux kernel prints bugs: scheduling from the idlethread “and” bad: scheduling from the idlethread “, it is usually a function called in the interrupt processing function that can sleep, such as semaphore,mutex,sleep, etc. It’s related to mutex. But the puzzle is when dealing with interrupts. Where are the interruptions?
looks at the log and finds that cat processes are all stuck. Could it be the interrupt caused by cat?Looking up the instructions for CAT, CAT prints a file to the standard output device. Since CAT produces interrupts, interrupt processing is to open the file and output it to the terminal, focusing on the processing function that reads the PROc file.
kernel module local_clients registers a method for manipulating proc files/here’s another one to explore/:
static structseq_operations clients_seq_ops = {
.start = clients_seq_start,
.next = clients_seq_next,
.stop = clients_seq_stop,
.show = clients_seq_show
}; When the cat/proc/local_clients/local_clients_info is called, clients_seq_start is executed first and clients_seq_show, clients_seq_start is executed next:
{
printk(” pos = % LLD \n “, *pos);
remove_timeout_stas();/Mutex_lock (& amp; amp) is called in this function. local_clients_mutex);/
//mutex_lock(& local_clients_mutex);
if (*pos > = MAX_WIRELESS_CLIENTS_NUM)
{
return NULL;
}
printk(” return addr: %p, pos = % LLD \n “,l_clients_info_list + *pos, *pos);
return l_clients_info_list + *pos;
}
problem caused by: two operations called mutex_lock; A cat-triggered interrupt invokes the read /proc/local_clients/local_clients_info. A cat-triggered interrupt invokes the read function clients_seq_start in the proc file system. Local_clients_mutex).
another is that when a HOST in WLAN issues a DNS message and local_clients listens to a DNS message, it also invokes mutex_lock(& amp; amp) before adding the IP, MAC, and HOST information of the HOST sending the message to the file local_clients_info. Local_clients_mutex);
means that there are two orders. One is that when the cat interrupt handler is called, local_clients adds an entry that causes the cat interrupt handler to be scheduled and reports an error. Alternatively, local_clients calls mutex_lock when adding an entry, and cat interrupts trigger calls mutex_lock, and the mutex_lock in the interrupt waits, so the interrupt handler goes to sleep, which is against the purpose of the interrupt handling mechanism.
Solution: Use spin_lock instead of mutex_lock. The difference between the two is: spin_lock, which can be checked repeatedly to see if the lock can be obtained, but will not fall asleep (busy waiting, so the spin_lock protection code should be short and dry, not consuming too much CPU time). The semaphore, while waiting for the signal to be released, goes to sleep until it is awakened; The interrupt handler cannot go to sleep (that is, cannot call sleep, or wait for a semaphore resource).
test 1)
tests mutex_lock before modification and spin_lock after modification. Shell script is used to loop cat /proc/local_clients/local_clients_info file, and a bat script is used for nslookup operation on WLAN terminal PC to make PC continuously send DNS message. The test finds that mutex_lock is used to give error prompt:
/TMP # tftp-g 192.168.0.104-r test.sh; Chmod 777 test. Sh
test. 100% sh | * * * * * * * * * * * * * * * * * * * * * | 78 ETA
/TMP 0:00:00 # 192.168.0.104 TFTP – g – r test. Sh. Chmod 777 test. Sh
test. 100% sh | * * * * * * * * * * * * * * * * * * * * * | 78 0:00:00 ETA #.
/TMP/test. The sh
[193.176000] BUG: scheduling while atomic: Cat /1835/0x00000100
[193.184000] Modules linked in: Umac ath_dev(P) ath_rate_atheros(P) ath_hal(P) asf(P) adf(P) athrs_gmac local_clients tp_domain parentCtrl
[193.196000] Cpu 0
[193.200000]
0:00 000000000000010000000100000000 [193.204000]
4:000030 832e32ac 00000080 c4653600
[193.208000]
And b9aca00364c598bc4ec4d38fffffff8 [193.216000]
12:0000002d 592f59ba 0000003f 00455924
[193.220000]
16:00 0000 c1832d0000000010007fc7fc70 [193.224000]
20:825cde98 00000000 7fc7fc70 00001000
[193.232000]
0000 a9800b22c8 24:00 [193.236000]
28:825cc000 825cde50 825cdf10 832d42c0
[193.240000] Hi: 001a99e2
[193.244000] Lo: 8f4e21b0
[193.248000] 832 d42d8 remove_timeout_stas + 0 x4c/0 x8c [local_clients]
[193.256000] Tainted: P
[193.260000] ra: 832 d42c0 remove_timeout_stas + 0 x34/0 x8c [local_clients]
[193.264000] the Status: 1000ff03 KERNEL EXL IE
[193.268000] Cause: 10800400
[193.272000] PrId: 00019374 (MIPS 24Kc)
test 2)
whether it is possible to be caused by multiple cat mutex_lock calls lead to problems
execute multiple cat call scripts in the shell, run for a long time, there is no problem; Cat is a user-mode process, so does the kernel perform two open files at the same time?
the answer is no, it involves the process scheduling, cat is the user mode process, and the punching file belongs to the kernel mode operation, from the user mode to the kernel mode operation, there are two ways, 1 is the system call, 2 is the interrupt, here is obviously the use of system call. If the system is in a core mindset and is processing system calls, then no other process in the system can steal CPU time and the scheduler must wait for the system call to complete before it can choose another process to execute, but an interrupt can terminate the system call. So the problem is probably caused by mutex_lock.
Cont:
in AP(MTK7628), when the mi 6 connection, there is a similar problem, causing other wireless devices can not connect to AP, but in the latest version of MIUI V8.2.23.0 this problem has been fixed.
[06-07 12:03:49]BUG: scheduling while atomic: RtmpMlmeTask/154/0x00000100
[06-07 12:03:49]Modules linked in: mt_wifi
[06-07 12:03:49]Cpu 0
[06-07 12:03:49]
00000000000000 c03582ec00000002 0:00 [06-0712:03:49]
4 : c0503000 c05e2728 00000000 c050a6ef
[06-07 12:03:49]
8: c050a6fc80f53d3e0000000480f53d44 [06-0712:03:49]
12 : 00044000 00000004 00000002 00000000
[06-07 12:03:49]
16:00 000002 c05e2728c0503000c0360000 [06-0712:03:49]
20 : c04844bc c03e0000 c048436c c043fdac
[06-07 12:03:49]
000000 c0358e28 24:00 [06-0712:03:49]
28 : 80f52000 80f53db8 c0484284 c03e334c
[06-07 12:03:49]Hi : 00000000
[06-07 12:03:49]Lo : 00000040
[06-07 12:03:49]epc : c03582ec RTMPCheckEntryEnableAutoRateSwitch+0x0/0x90 [mt_wifi]
[06-07 12:03:49] Not tainted
[06-07 12:03:49]ra : c03e334c APMlmeDynamicTxRateSwitching+0x130/0x9a8 [mt_wifi]
[06-07 12:03:49]Status: 1100ff03 KERNEL EXL IE
[06-07 12:03:49]Cause : 50808000
[06-07 12:03:49]PrId : 00019655 (MIPS 24Kc)