Method 1
Command: git add – U
come from
https://www.cnblogs.com/changyiqiang/p/12867839.html
(sorry for the trouble)
Method 1
Command: git add – U
come from
https://www.cnblogs.com/changyiqiang/p/12867839.html
(sorry for the trouble)
Ambiguous reference to member ‘dataTask(with:completionHandler:)’
let request = NSMutableURLRequest(url: URL(string: “Your API URL here” ,param: param))!,
cachePolicy: .useProtocolCachePolicy,
timeoutInterval:”Your request timeout time in Seconds”)
request.httpMethod = “POST”
request.allHTTPHeaderFields = headers as? [String : String]
let dataTask = URLSession.shared.dataTask(with: request ) {data,response,error in
let httpResponse = response as? HTTPURLResponse
if (error != nil) {
print(error)
} else {
print(httpResponse)
}
DispatchQueue.main.async {
//Update UI here
}
}
dataTask.resume()
Solution: just make request as URLRequest
let dataTask = URLSession.shared.dataTask(with: request as URLRequest)
Using textstudio, we encountered a small error
Source code:
\begin{thebibliography}{}
\bibliographystyle{aaa} % template
\bibliography{references} % references
%
% and use \bibitem to create references. Consult the Instructions
% for authors for reference list style.
%
\item{a}
% Format for Journal Reference
Author, Article title, Journal, Volume, page numbers (year)
% Format for books
%\bibitem{b}
Author, Book title, page numbers. Publisher, place (year)
% etc
\end{thebibliography}
report errors:
Something’s wrong–perhaps a missing \item. \begin{thebibliography}{1}
After checking for a long time, I didn’t find the reason, and the online method was also wrong. Later, I found that I made a low-level mistake: the template file and the bib file were misplaced.
Solution: will
\bibliographystyle{spbasic} % template
\bibliography{references} % references
Put in
\begin{thebibliography}{}
\End {the bibliography}
just ahead of this interval.
Error type
When writing the crawler program, the following prompt appears:
Must have equal len keys and value when setting with an iterableThe types of data read are as follows:

Error code:
df.loc[m,'geo']=s['geo']reason
The reason is that the object crawled is a list, and the key values on the left and right sides are not equal, so an error message appears!
modify
if s['geo']!=None:
df.loc[m,'geo']=str(s['geo']['coordinates'][1])+','+str(s['geo']['coordinates'][0])
else:
df.loc[m,'geo']=''The problem was solved successfully after modification
About java.lang.IllegalArgumentException Error in simplecursoradapter ‘column’_ ID ‘does not exist problem:
Simplecursoradapter inherits from the cursoradapter. This class has an implicit rule that there must be a_ The ID field.
The way to solve this problem is:
1. Double name the database table, and name the self growing primary key as_ id
2. When using database query language, use db.rawQuery (select * from Biao, null) —- there are_ ID field
3. Use db.rawQuery (select id as _ ID, name from Biao)_ ID.
That is to say, you must find it when querying_ ID column.
Dumps is to convert dict to STR format, loads is to convert STR to dict format. Dump and load are similar functions, but they are combined with file operation.
Code example:
import json
dic_a = {'name': 'wang', 'age': 29}
str_b = json.dumps(dic_a)
print(type(str_b),str_b) #<class 'str'> {"name": "wang", "age": 29}
dic_c = json.loads(str_b)
print(type(dic_c),dic_c) #<class 'dict'> {'name': 'wang', 'age': 29}
Then we will see the difference between dump and dumps. See the code:
import json
dic_a = {'name': 'wang', 'age': 29}
str_b = json.dumps(dic_a)
print(type(str_b),str_b) #<class 'str'> {"name": "wang", "age": 29}
#c = json.dump(dic_a)
# TypeError: dump() missing 1 required positional argument: 'fp'
c = json.dump(dic_a)
Dump needs a parameter similar to a file pointer (not a real pointer, it can be called a file like object), which can be combined with file operation, that is, you can convert dict into STR and then store it in a file; dumps directly gives STR, that is, you can convert dictionary into str.
See the code for an example (pay attention to some small details of file operation)
import json
dic_a = {'name': 'wang', 'age': 29}
str_b = json.dumps(dic_a)
print(type(str_b),str_b) #<class 'str'> {"name": "wang", "age": 29}
#c = json.dump(dic_a)
# TypeError: dump() missing 1 required positional argument: 'fp'
c = json.dump(dic_a,open('str_b.txt','w'))
Note: dump is rarely used in practice.
Reproduced in: https://my.oschina.net/u/3486061/blog/3065779
Error statement:
import pandas as pd
AttributeError: module ‘matplotlib’ has no attribute ‘artist’
Reason:
Matplotlib is not installed, just re install it.
conda uninstall matplotlib
conda install matplotlib
Reference
https://github.com/matplotlib/matplotlib/issues/12626’35;
Errors such as problems
solutions:
from pyspark.sql.session Import sparksession
spark = sparksession (your sparkcontext object in brackets)
use
conda create -f environment.ymlAfter creating a new environment, you can see all the installation packages by using CONDA list in the new environment, but you will report an error when opening Python import
according to
https://stackoverflow.com/questions/51712693/packagenotinstallederror-package-is-not-installed-in-prefix
I tried the suggestions in it
conda update --name base condaInvalid, no attempt
conda update --allBecause all installed packages will be upgraded
Then try
conda install anacondaA lot of new bags, but still invalid, finally
conda activate base
conda update --allsolve the problem
Linux environment, the following figure 1 operation error, change to figure 2 form, in windows will not report an error, running well, the reason remains to be explored!
ValueError: Mixing iteration and read methods would lose data
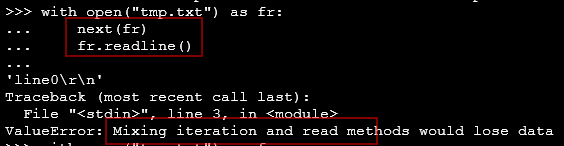
lines = fr.readline ()
for line in lines[1:]
For large documents, read them line by line to extract the desired part to prevent too much memory and insufficient memory;
1. Error description
>>> int(67,8);
Traceback (most recent call last):
File "<pyshell#172>", line 1, in <module>
int(67,8);
TypeError: int() can't convert non-string with explicit base2. Cause of error
The int() function is used to convert a string or number type to an integer. If there is only one parameter value, the value can be string or number. However, two parameters are passed in, the first parameter is string, and the second parameter is hexadecimal (binary, octal, decimal or hexadecimal). Now in the above example, the first parameter is a number, and the second parameter is octal, so an error will be reported
3. Solutions
If you want to convert an octal number to decimal, you can do this:
>>> int('67',8);
55
>>>
After searching, it is found that the way to write when importing the package is wrong.
That’s what I wrote
import matplotlib as pltThat’s OK
import matplotlib.pyplot as plt