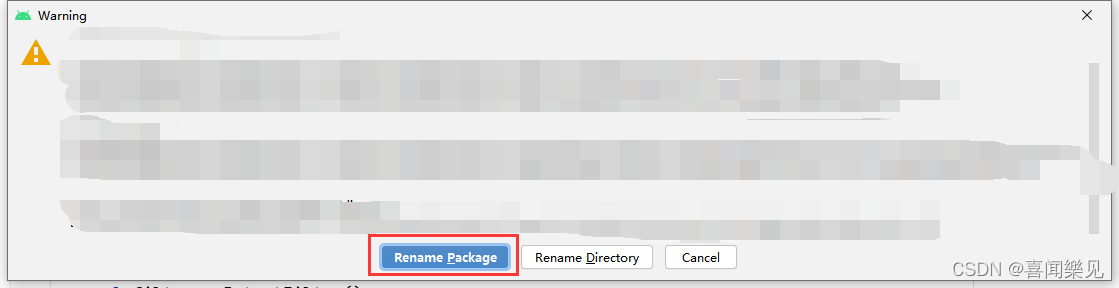
Just follow the steps in the image. 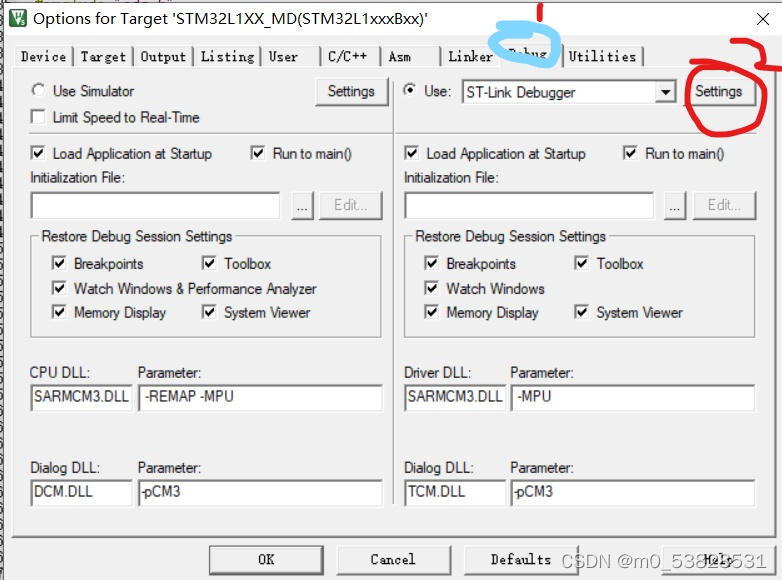
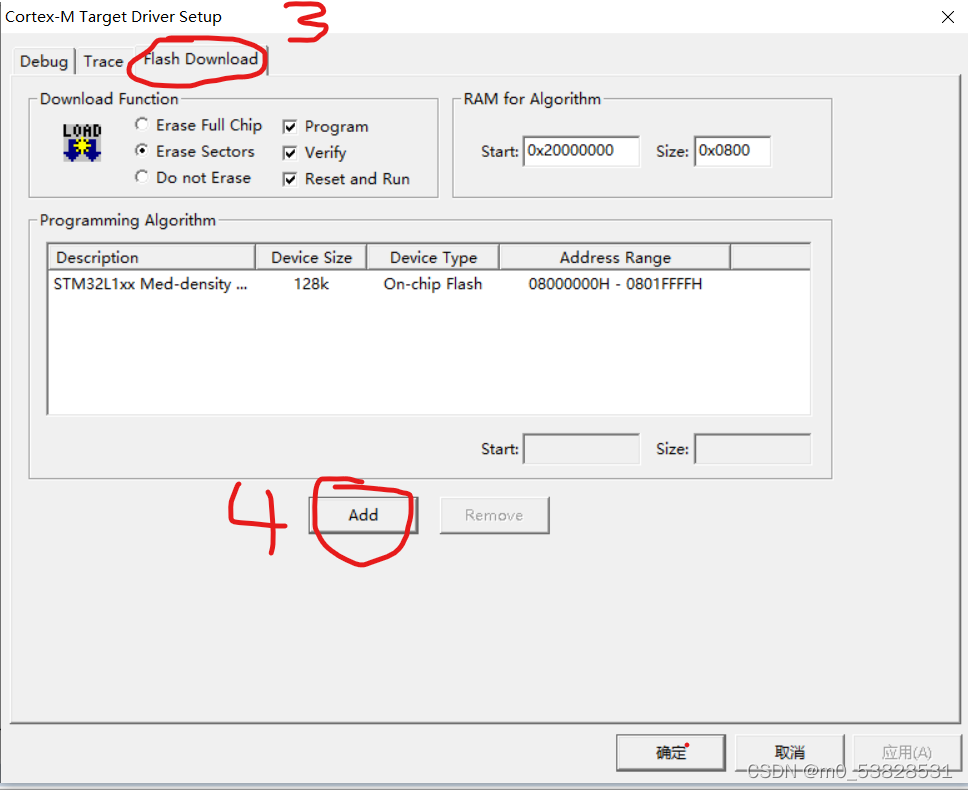
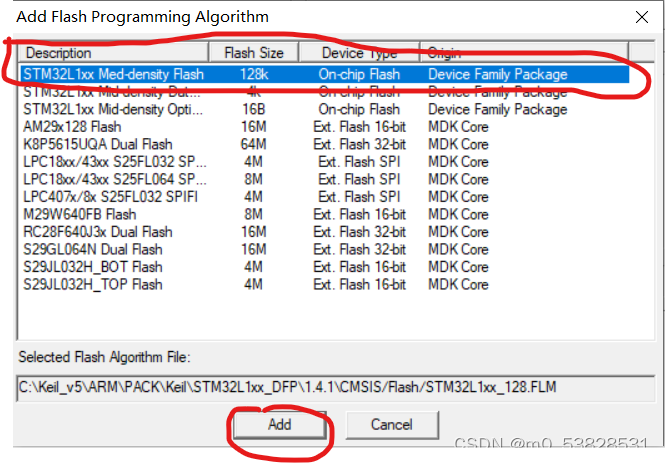
Just follow the steps in the image.
Error reporting information
[WARN ][o.e.x.m.e.l.LocalExporter] [es03.kpt.rongtime.aliapse5.id] unexpected error while indexing monitoring documentorg.elasticsearch.xpack.monitoring.exporter.ExportException: RemoteTransportException[[es01.kpt.rongtime.aliapse5.id][10.107.0.247:29300][indices:admin/create]]; nested: IllegalArgumentException[Validation Failed: 1: this action would add [6] total shards, but this cluster currently has [2998]/[3000] maximum shards open;];
at org.elasticsearch.xpack.monitoring.exporter.local.LocalBulk.lambda$throwExportException$2(LocalBulk.java:125) ~[x-pack-monitoring-7.4.2.jar:7.4.2] at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:195) ~[?:?] at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:177) ~[?:?]
at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948) ~[?:?]
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:484) ~[?:?]
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:474) ~[?:?]
at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:150) ~[?:?]
at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:173) ~[?:?]
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) ~[?:?]
at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:497) ~[?:?]
at org.elasticsearch.xpack.monitoring.exporter.local.LocalBulk.throwExportException(LocalBulk.java:126) [x-pack-monitoring-7.4.2.jar:7.4.2]
at org.elasticsearch.xpack.monitoring.exporter.local.LocalBulk.lambda$doFlush$0(LocalBulk.java:108) [x-pack-monitoring-7.4.2.jar:7.4.2]
at org.elasticsearch.action.ActionListener$1.onResponse(ActionListener.java:62) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.support.ContextPreservingActionListener.onResponse(ContextPreservingActionListener.java:43) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.support.TransportAction$1.onResponse(TransportAction.java:70) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.support.TransportAction$1.onResponse(TransportAction.java:64) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.support.ContextPreservingActionListener.onResponse(ContextPreservingActionListener.java:43) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.ActionListener.lambda$map$2(ActionListener.java:145) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.ActionListener$1.onResponse(ActionListener.java:62) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.ActionListener$1.onResponse(ActionListener.java:62) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.bulk.TransportBulkAction$BulkOperation.doRun(TransportBulkAction.java:421) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.bulk.TransportBulkAction.executeBulk(TransportBulkAction.java:551) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.bulk.TransportBulkAction$1.onFailure(TransportBulkAction.java:287) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.support.TransportAction$1.onFailure(TransportAction.java:79) [elasticsearch-7.4.2.jar:7.4.2]
at org.elasticsearch.action.support.ContextPreservingActionListener.onFailure(ContextPreservingActionListener.java:50) [elasticsearch-7.4.2.jar:7.4.2]
Cause of problem
[indices:admin/create]]; nested: IllegalArgumentException[Validation Failed: 1: this action would add [6] total shards, but this cluster currently has [2998]/[3000] maximum shards open;];
For elasticsearch7 and above, only 3000 shards are allowed by default, which is caused by the insufficient number of available shards in the cluster.
Solution:
PUT /_cluster/settings
{
"transient": {
"cluster": {
"max_shards_per_node":10000
}
}
}
Application installation failure: the installation failure is due to the conflict of Providers (generally speaking, the same program has been installed before, with conflict)
Four places need to be modified
(There may be some places that do not have to be modified, but it is still recommended to modify together)
1. There are three places to modify in AndroidManifest.xml
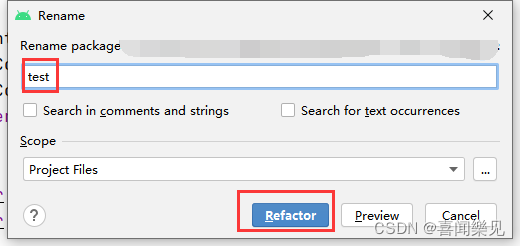
Modify package name

After modifying the package name, you should also modify it
to the same as above
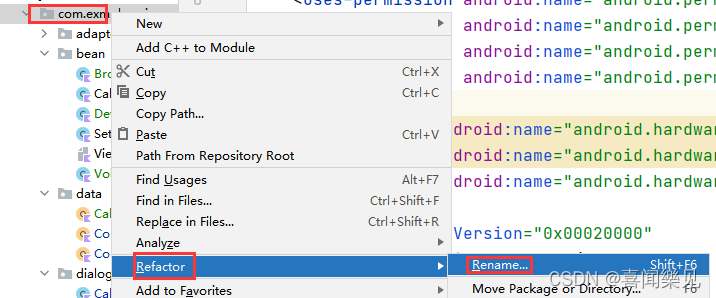
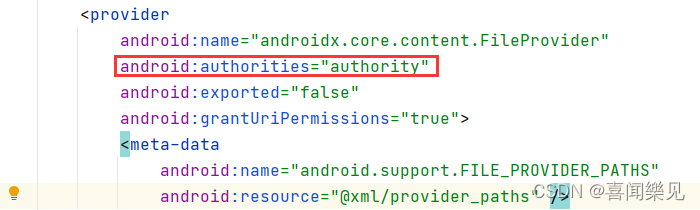
There is a modification of the word: authorities

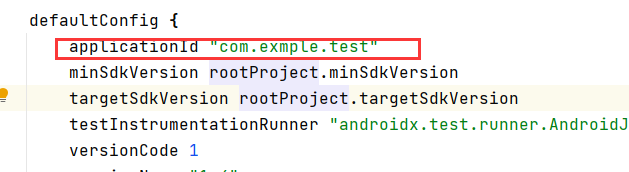
2. In build.gradle(:app)
Applicationid modify the same
as the package name, and then Sync Now
Error:

In fact, the IDE has given the reason and solution
just change “Java 1.8” to “Java 11” (please see how to operate it) 👇)
Solution:
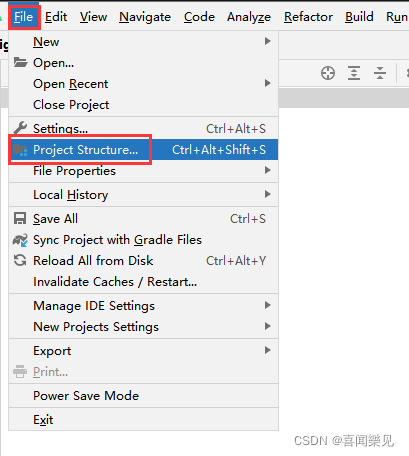
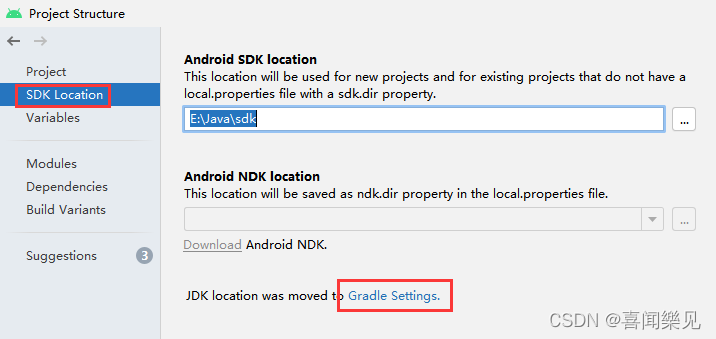
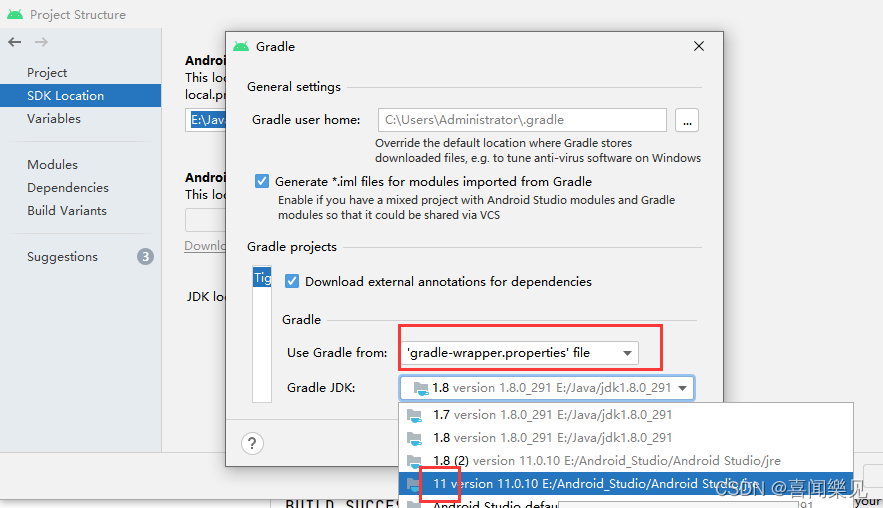
Background
Recently, when running sparksql, I frequently print logs and report errors in the middle of execution:
WARN TaskMemoryManager: Failed to allocate a page (104876 bytes), try again.
WARN TaskMemoryManager: Failed to allocate a page (104876 bytes), try again.
…
reason
There is not enough memory to perform tasks, and resources need to be recycled frequently
Solution:
1. Optimize SQL scripts. (preferred, that’s how I solved it at that time)
2. Increase driver memory, — driver memory 6g
My SQL at that time was simplified as follows:
select name
from stu
where id in (select id from in_stu);
Stu data volume is 800W, in_stu data volume is 1.2kW
Optimized as:
select name
from stu
where id in (select distinct id from in_stu);
after optimization, The data volume of In_stu ID is reduced to 11 W, and the problem is solved.
Error Messages:
failed call to cuInit: CUDA_ERROR_NO_Device: no CUDA capable device is detected
this is also what I encountered when running a CNN SVM classifier program of tensorflow GPU today. It’s not the problem of the program. It’s our graphics card.
Solution:
import tensorflow as tf
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.InteractiveSession(config=config)
Just add these lines of code to the head of the code, and you don’t need to write this code belowos.environ['CUDA_VISIBLE_DEVICES'] = '/gpu:0'
1. Version
cocos3.4
2. Defects of stringify
Customized a fragment shader, mimicking the official method, using STRINGIFY to convert the code to strings. Run it and report an error
cocos2d: ERROR: Failed to compile shader: uniform mat4 CC_PMatrix;
uniform mat4 CC_MVMatrix; uniform mat4 CC_MVPMatrix; uniform mat3
CC_NormalMatrix; uniform vec4 CC_Time; uniform vec4 CC_SinTime;
uniform vec4 CC_CosTime; uniform vec4 CC_Random01; uniform sampler2D
CC_Texture0; uniform sampler2D CC_Texture1; uniform sampler2D
CC_Texture2; uniform sampler2D CC_Texture3; //CC INCLUDES ENDvarying vec4 v_fragmentColor; varying vec2 v_texCoord; uniform float
outlineSize; uniform vec3 outlineColor; uniform vec2 textureSize;
uniform vec3 foregroundColor; const float cosArray[12] = { 1 cocos2d:
ERROR: 0:? : ‘pre-mature EOF’ : syntax error syntax error
The following is the reason for my guess error:
the problem lies in the initialization statement of floating-point array. Stringify is a macro definition function, which is defined as:
#define STRINGIFY(A) #A
Here a # syntax of macro definition is used to convert A into a string. When A contains a ‘,’ character, A is truncated and incomplete. For example, STRINGIFY (int a,b) expects the string to be “int a,b”, but in fact it will be “int a”. In fact, STRINGIFY is expanded with two arguments, the first being int a and the second being b.
3. Solutions
3.1. Add ()
Call STRINGIFY with brackets in the argument: STRINGIFY((AB)). However, the string obtained this way will also be bracketed and needs to be unbracketed, which is more troublesome
3.2. Write directly as a string
For example:
GLchar my_vert[] = "\
attribute vec4 a_position;\n\
attribute vec2 a_texCoord;\n\
attribute vec4 a_color;\n\
\n\
#ifdef GL_ES \n\
varying lowp vec4 v_fragmentColor; \n\
varying mediump vec2 v_texCoord; \n\
#else \n\
varying vec4 v_fragmentColor;\n\
varying vec2 v_texCoord; \n\
#endif \n\
\n\
void main() \n\
{ \n\
gl_Position = CC_PMatrix * a_position; \n\
v_fragmentColor = a_color; \n\
v_texCoord = a_texCoord; \n\
}";
It’s also troublesome. You need to add \n\ to each line.
3.3. Write the code into a file
For example:
#ifdef GL_ES
precision lowp float;
#endif
varying vec4 v_fragmentColor;
varying vec2 v_texCoord;
void main()
{
float ff=1;
gl_FragColor = texture2D(CC_Texture0, v_texCoord);
float f=(gl_FragColor.r+gl_FragColor.g+gl_FragColor.b)/3.0f;
gl_FragColor=vec4(f,f,f,gl_FragColor.a);
}
Save the above code as ccShader_PositionTextureColor_noMVP_Gray.fsh file. Then use
std::string fragmentSource=FileUtils::getInstance()->getStringFromFile(FileUtils::getInstance()->fullPathForFilename("shaders/ccShader_PositionTextureColor_noMVP_Gray.fsh"));
Direct reading.
Recently in business development need to update the UI in the QThread, if the UI handle through the direct update will make the program reported an error, because the update of the UI in the thread will not be captured by the original thread of the EXEC event, will lead to message event blockage generated ERROR, so the use of the signal and slot mechanism, and then I declared a signals signal in the QThread, the compilation reported this error.
The "QtRunWork" task returned false but did not log an errorNo detailed warning was given, and I later checked the relevant QT instructions to solve the problem.
Solution: Add a line of macro definition to the class where you use signals and slots.
Q_OBJECTThis will work, the signal and slotted based on Q_OBJECT, we need to declare it module to our class so that the QT compiler can instantiate it, otherwise it will be exception ERROR.
docker-machine Create Certificate Stuck
docker-machine –debug create -d hyperv –hyperv-virtual-switch “Default Switch” docker-machine
Hint
https://github.com/minishift/minishift/issues/2722
Hi, the only way for me to get around this was to disable the Windows 10 built-in OpenSSH Client, via Windows Features. After that minishift used its internal ssh client and proceeded. Unfortunately i am running into another issue after that, where the control-plane pods are not starting and the minishift deployment fails, since the API access times out. Would be inteeresting to see if you get the same once you deal with the SSH stuff Am Fr., 30. Nov. 2018 um 12:15 Uhr schrieb denisjc7 < [email protected]>: … Hi, @LW81 https://github.com/LW81 I am experiencing the same issue on basically the same configurations as yours. Did you find a solution?Thank you — You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub <#2722 (comment)>, or mute the thread https://github.com/notifications/unsubscribe-auth/ATAFNHdE_fyUXANlW2bT8vzeFZ8Un2Erks5u0RNggaJpZM4WHLXu
Solution:
Through [Settings] => [Applications] => [Optional Applications
Uninstall Windows 10 built-in OpenSSH Client
After using the built-in ssh, it runs successfully
There is no latest after the electronic updater is packaged YML file
Solution:
Add the following code to the build of package.json
"build": {
...
"publish": {
"provider": "generic",
"url": "http://127.0.0.1:8080" ,
"channel": "latest"
}
},
You can see the file after packaging
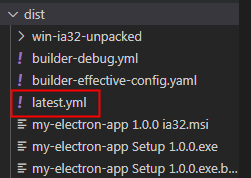
Scenario:
Push files from server a to server B
Error message
@ERROR: Unknown module ‘xxx’
rsync error: error starting client-server protocol (code 5) at main. c(1649) [sender=3.1.6]
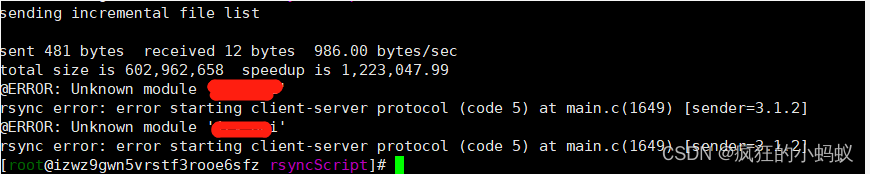
Finally, it is found that the default configuration file of Rsync is rsyncd.com under/etc.conf instead of the file rsyncd. In the/etc/rsyncd/folder.conf
Solution 1: directly configure /etc/rsyncd.conf file, the operation steps are omitted.
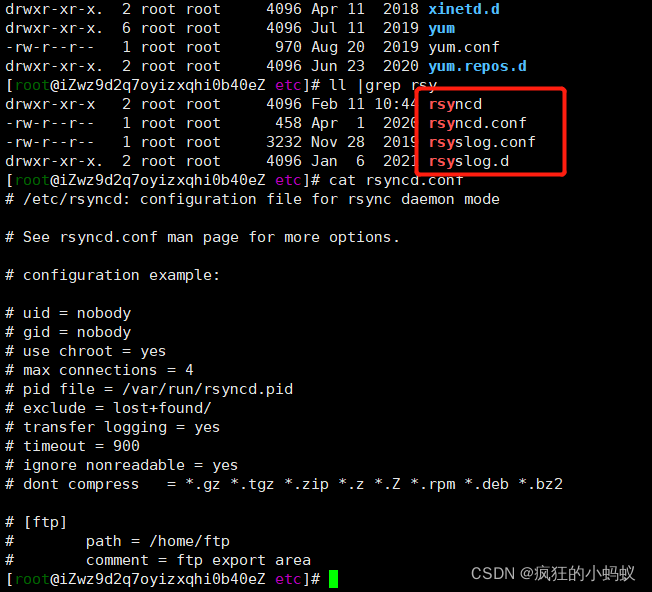
Solution 2:
(1) Modify VIM /lib/SYSTEMd/system/rsyncd.service,
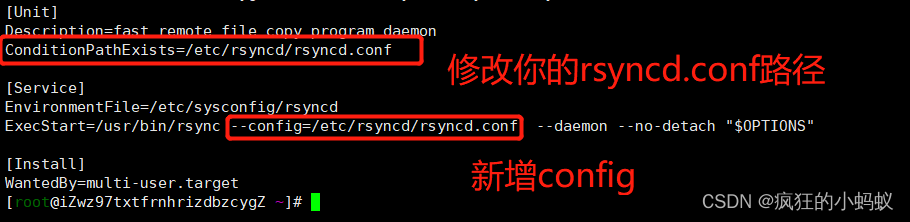
The following is the configuration content
[Unit]
Description=fast remote file copy program daemon
ConditionPathExists=/etc/rsyncd/rsyncd.conf
[Service]
EnvironmentFile=/etc/sysconfig/rsyncd
ExecStart=/usr/bin/rsync --config=/etc/rsyncd/rsyncd.conf --daemon --no-detach "$OPTIONS"
[Install]
WantedBy=multi-user.target
(2) Reload the background process and restart the Rsync service to synchronize.
systemctl daemon-reload
systemctl restart rsyncd
Related commands:
Systemctl daemon reload daemon
Systemctl restart rsyncd restart synchronization service
Systemctl start rsyncd# start
Systemctl stop rsyncd stop
systemctl status rsyncd. Service view Rsync status
PS aux | grep Rsync | viewing process
Cause: the container running on the slave machine tried to use too much memory and was killed by the nodemanager.
Solution: add memory
Set the memory configuration for map and reduce tasks in the configuration file mapred-site.xml of hadoop as follows: (The actual memory configured in the value needs to be modified according to the memory size of your machine and the application)
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>