Environmental description
The harbor repository I built requires a domain name and https access
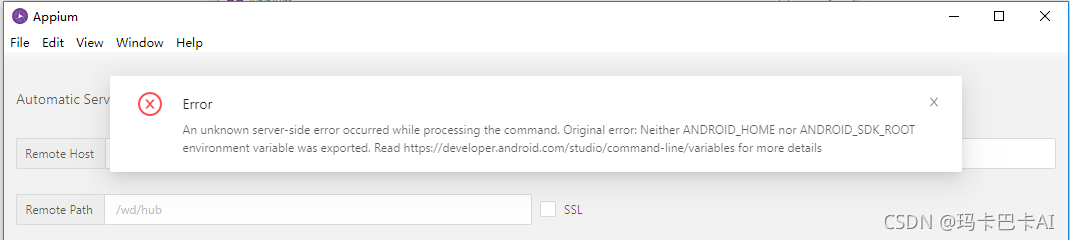
Error 1 is reported. When other docker environments log in to harbor
[root@k8s0001 ~]# docker login www.harbor.wuhan.cn
Username: admin
Password:
Error response from daemon: Get "https://www.harbor.wuhan.cn/v2/": x509: certificate signed by unknown authority
Error 2: when other docker environments pull self built harbor warehouse images
[root@k8s0001 ~]# docker pull www.harbor.wuhan.cn/22202/helloworld@sha256:0d9ce49958ea82a48c40a397ccc785674ec3ce1dfd4f749c3c7c7a63790a54cd
Error response from daemon: Get "https://www.harbor.wuhan.cn/v2/": x509: certificate signed by unknown authority
For these two errors, you need to transfer the generated key CP to the configuration file directory of the corresponding machine docker. The operations are as follows:
Configure HTTPS links
##harbor
[root@harbor opt]# cd /etc/docker/
[root@harbor docker]# ls
certs.d key.json
[root@harbor docker]# cd certs.d/
[root@harbor certs.d]# ls
www.harbor.wuhan.cn
[root@harbor certs.d]# cd www.harbor.wuhan.cn/
[root@harbor www.harbor.wuhan.cn]# ls
ca.crt www.harbor.wuhan.cn.cert www.harbor.wuhan.cn.key
[root@harbor certs.d]# cd ..
[root@harbor certs.d]# scp -r www.harbor.wuhan.cn [email protected]:/etc/docker/certs.d/
[email protected]'s password:
www.harbor.wuhan.cn.cert 100% 2126 914.9KB/s 00:00
www.harbor.wuhan.cn.key 100% 3243 1.5MB/s 00:00
ca.crt 100% 2033 839.2KB/s 00:00
[root@harbor certs.d]#
[root@harbor certs.d]# scp -r www.harbor.wuhan.cn [email protected]:/etc/docker/certs.d/
[email protected]'s password:
www.harbor.wuhan.cn.cert 100% 2126 845.3KB/s 00:00
www.harbor.wuhan.cn.key 100% 3243 1.9MB/s 00:00
ca.crt 100% 2033 1.8MB/s 00:00
[root@harbor certs.d]#
[root@harbor certs.d]#
[root@harbor certs.d]# scp -r www.harbor.wuhan.cn [email protected]:/etc/docker/certs.d/
[email protected]'s password:
www.harbor.wuhan.cn.cert 100% 2126 227.8KB/s 00:00
www.harbor.wuhan.cn.key 100% 3243 2.5MB/s 00:00
ca.crt 100% 2033 1.2MB/s 00:00
Then restart the docker
[root@k8s0001 opt]# systemctl restart docker
[root@k8s0002 opt]# systemctl restart docker
[root@k8s0003 opt]# systemctl restart docker