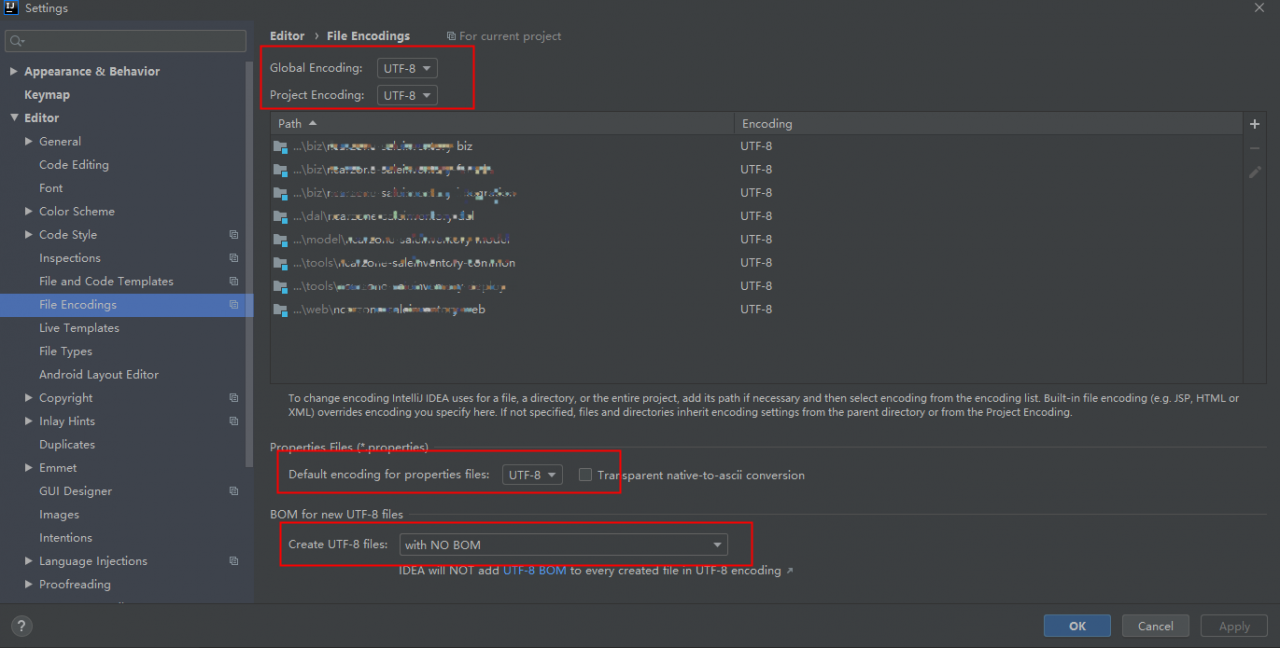
When running pytorch code, “modulenotfoundererror: no module named” is reported_ Bz2 ‘”error, the complete error message is as follows:
Traceback (most recent call last):
File "stat_model.py", line 1, in <module>
from torchstat import stat
File "/usr/local/lib/python3.7/site-packages/torchstat/__init__.py", line 11, in <module>
from torchstat.reporter import report_format
File "/usr/local/lib/python3.7/site-packages/torchstat/reporter.py", line 1, in <module>
import pandas as pd
File "/usr/local/lib/python3.7/site-packages/pandas/__init__.py", line 55, in <module>
from pandas.core.api import (
File "/usr/local/lib/python3.7/site-packages/pandas/core/api.py", line 24, in <module>
from pandas.core.groupby import Grouper, NamedAgg
File "/usr/local/lib/python3.7/site-packages/pandas/core/groupby/__init__.py", line 1, in <module>
from pandas.core.groupby.generic import ( # noqa: F401
File "/usr/local/lib/python3.7/site-packages/pandas/core/groupby/generic.py", line 44, in <module>
from pandas.core.frame import DataFrame
File "/usr/local/lib/python3.7/site-packages/pandas/core/frame.py", line 88, in <module>
from pandas.core.generic import NDFrame, _shared_docs
File "/usr/local/lib/python3.7/site-packages/pandas/core/generic.py", line 70, in <module>
from pandas.io.formats.format import DataFrameFormatter, format_percentiles
File "/usr/local/lib/python3.7/site-packages/pandas/io/formats/format.py", line 48, in <module>
from pandas.io.common import _expand_user, _stringify_path
File "/usr/local/lib/python3.7/site-packages/pandas/io/common.py", line 3, in <module>
import bz2
File "/usr/local/lib/python3.7/bz2.py", line 19, in <module>
from _bz2 import BZ2Compressor, BZ2Decompressor
ModuleNotFoundError: No module named '_bz2'
The reason for this error is that I use Python 3.7, but bz2 is installed in Python 3.6, so I can’t find it. In order to solve this problem, we need to copy the BZ Library in Python 3.6 to Python 3.7. The specific process is as follows:
1. Find the BZ library file in the path of python3.6, that is, the_ bz2.cpython-36m-x86_ 64-linux- gnu.so ”。
ls /usr/lib/python3.6/lib-dynload/

You can see that “- 36m” in the file name corresponds to Python 3.6.
2. Switch to the path corresponding to python3.7 and copy the file to the directory
cd /usr/local/lib/python3.7/lib-dynload
sudo cp /usr/lib/python3.6/lib-dynload/_bz2.cpython-36m-x86_64-linux-gnu.so ./
3. Modify the file name and change “- 36m” to “- 37m”
sudo mv _bz2.cpython-36m-x86_64-linux-gnu.so _bz2.cpython-37m-x86_64-linux-gnu.so
So far, the problem has been solved.
It should be noted that there is also a path/usr/lib/python3.7/lib-dynload. It is useless to copy the file to this directory. I need to copy it to the/usr/local/lib/python3.7/lib-dynload directory here.