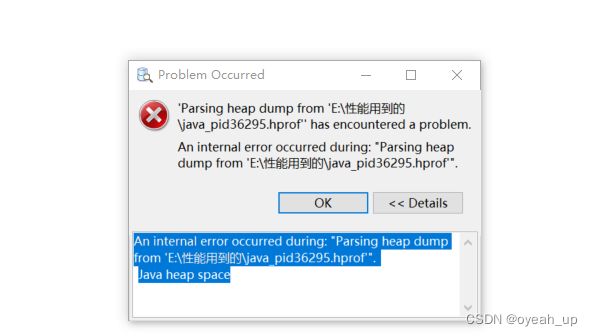
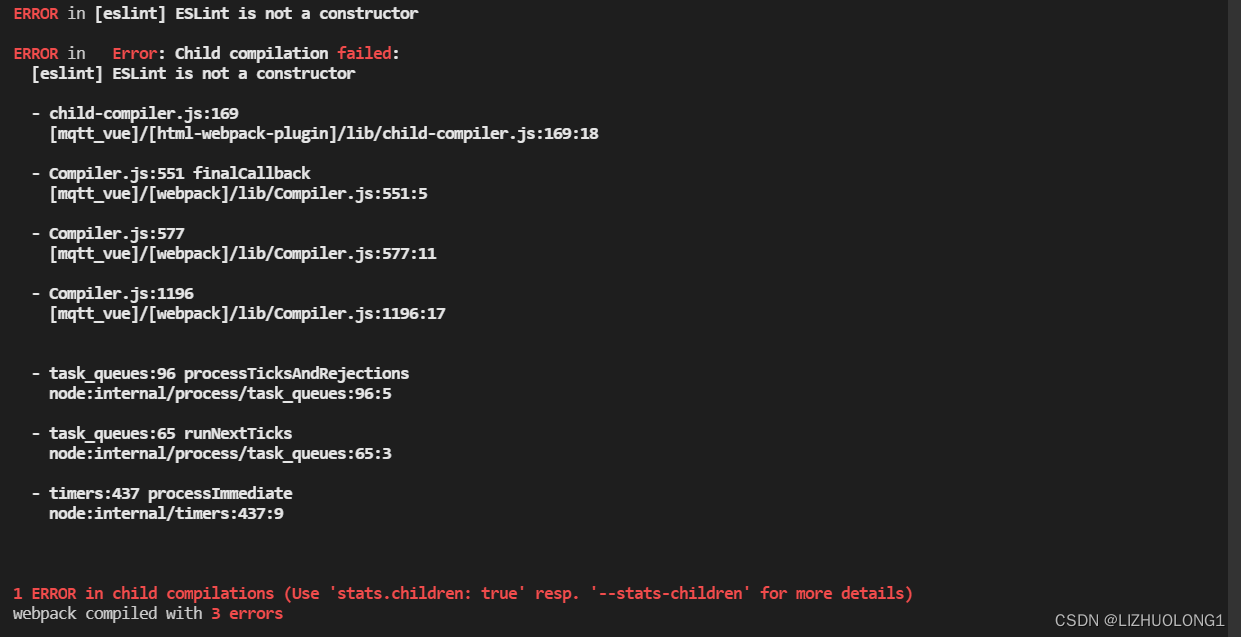
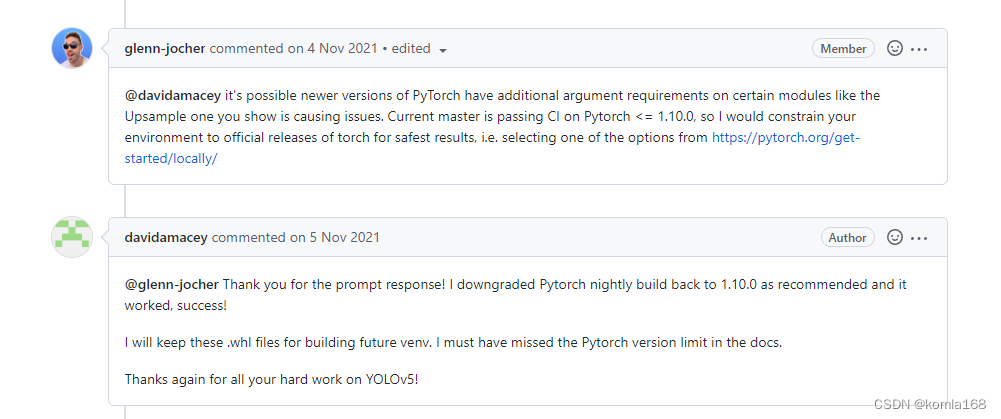
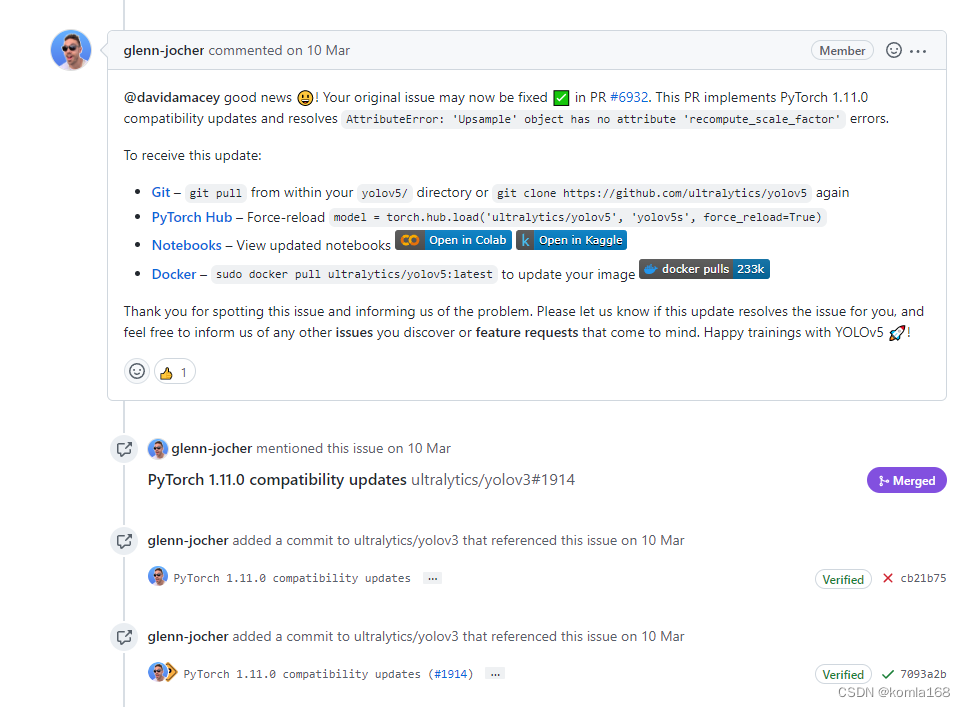
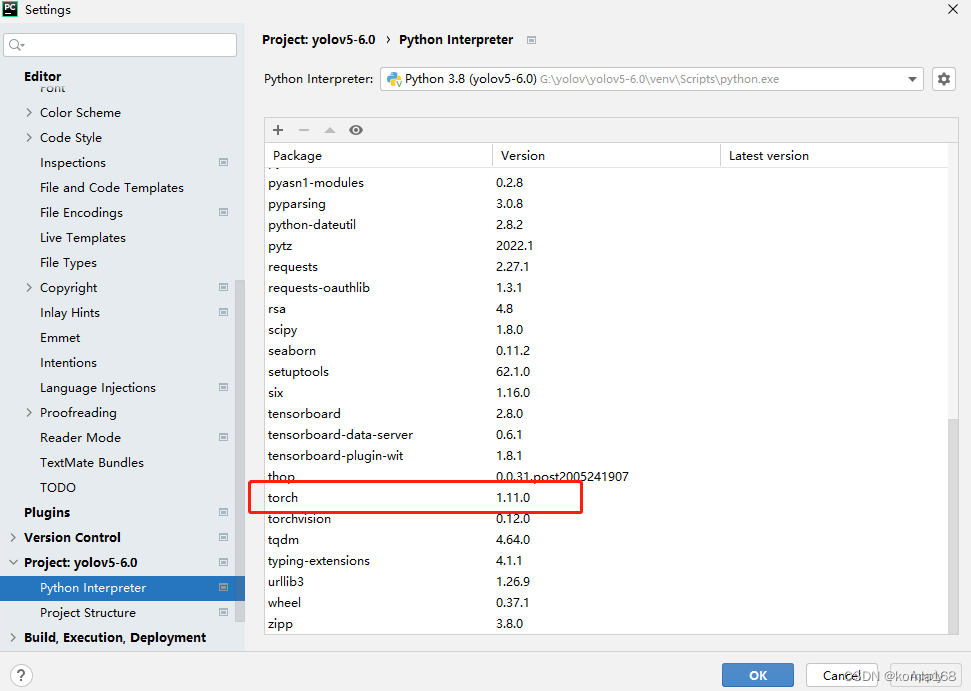
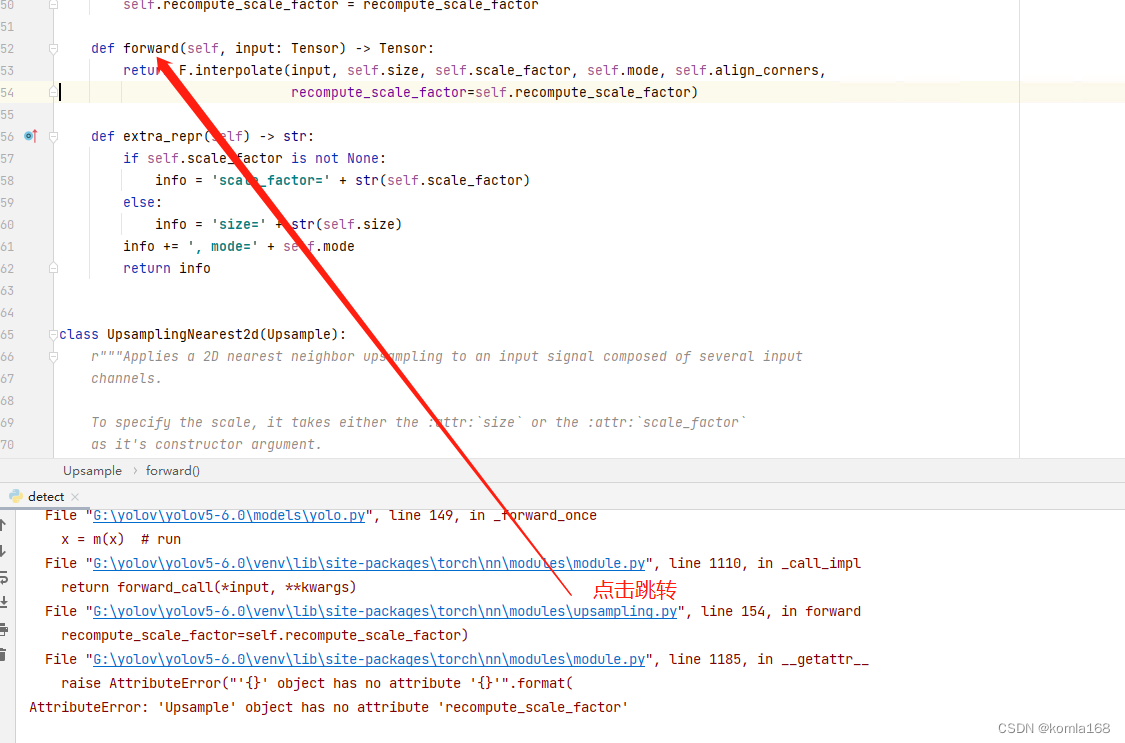
The old program needs to be upgraded. The previous CUDA is 10.2
Problem Description:
environment
CUDA 11.2 (previously 10.2)
onnxruntime-gpu 1.10
python 3.9.7
When starting the program
Traceback (most recent call last):
File "/home/aiuser/cover/liheng-foggun/app.py", line 15, in <module>
model = DetectMultiBackend(weights=config.paddle.model_file)
File "/home/aiuser/miniconda3/envs/cover/lib/python3.9/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/aiuser/cover/liheng-foggun/models/yolo.py", line 37, in __init__
self.session = onnxruntime.InferenceSession(weights, providers=['CUDAExecutionProvider'])
File "/home/aiuser/miniconda3/envs/cover/lib/python3.9/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 335, in __init__
self._create_inference_session(providers, provider_options, disabled_optimizers)
File "/home/aiuser/miniconda3/envs/cover/lib/python3.9/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 379, in _create_inference_session
sess.initialize_session(providers, provider_options, disabled_optimizers)
RuntimeError: /onnxruntime_src/onnxruntime/core/providers/cuda/cuda_call.cc:122 bool onnxruntime::CudaCall(ERRTYPE, const char*, const char*, ERRTYPE, const char*) [with ERRTYPE =
cudaError; bool THRW = true] /onnxruntime_src/onnxruntime/core/providers/cuda/cuda_call.cc:116 bool onnxruntime::CudaCall(ERRTYPE, const char*, const char*
, ERRTYPE, const char*) [with ERRTYPE = cudaError; bool THRW = true] CUDA failure 999: unknown error ; GPU=24 ; hostname=aiserver-sl-01 ; expr=cudaSetDevice(info_.device_id);
Cause analysis:
1. At first, I thought it was the onnxruntime GPU version problem, upgraded to 1.12 it still reports an error.
2. It is said that it is incompatible.
3. Try to reinstall the driver. When 11.2 is uninstalled, nvidia-smi finds that the previous 10.2 driver still exists.
4. The reason is that the previous drive was not unloaded completely
Solution:
1. Uninstall 10.2
sudo /usr/local/cuda-10.2/bin/cuda-uninstaller
2. Install a new drive
#install 515.57 offline
sudo ./NVIDIA-Linux-x86_64-515.57.run -no-x-check -no-nouveau-check
VIDIA-Linux-x86_64-515.57.run -no-x-check -no-nouveau-check