Reason: Pytorch and CUDA versions are not right
(It is also possible that there is not enough memory space, you can change the virtual space size)
Uninstall Pytorch: Conda Uninstall Pytorch, and if you install CUDA, it will automatically override the CUDA version.
Open CMD and type from the command line
import torch
print(torch.__version__)
print(torch.version.cuda) 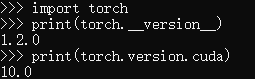
Similar errors occur if the cudA version is not installed with the torch version.

Here’s how to install CUDA:
1. Open the NVIDIA control panel to view the CUDA version supported by the current video card driver:
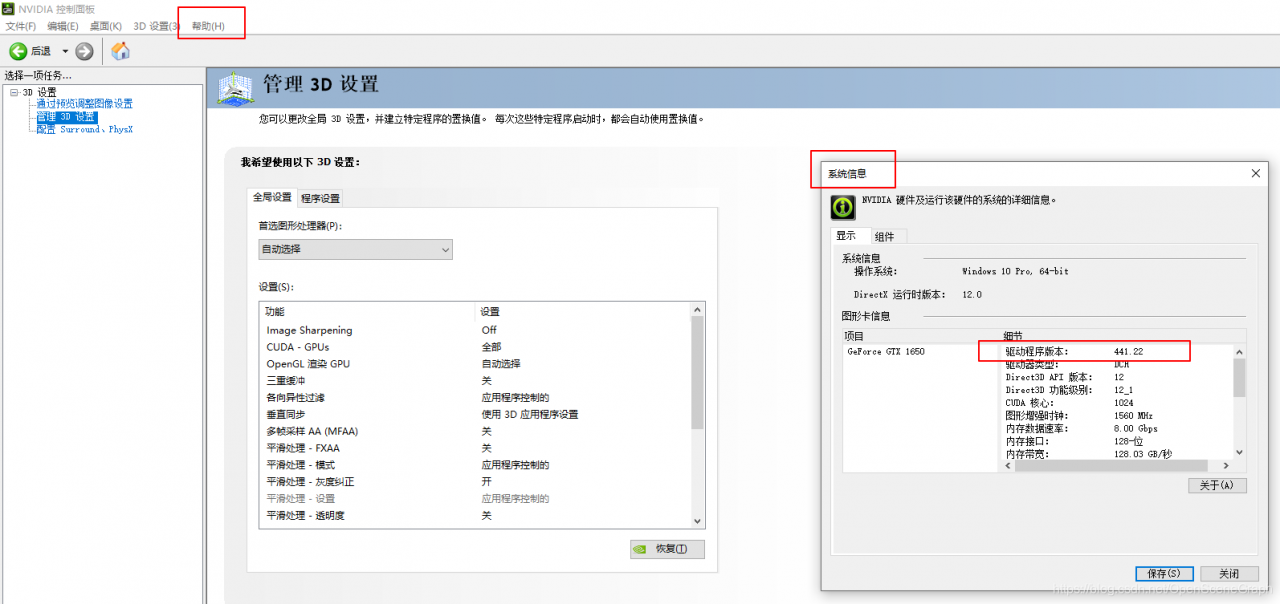
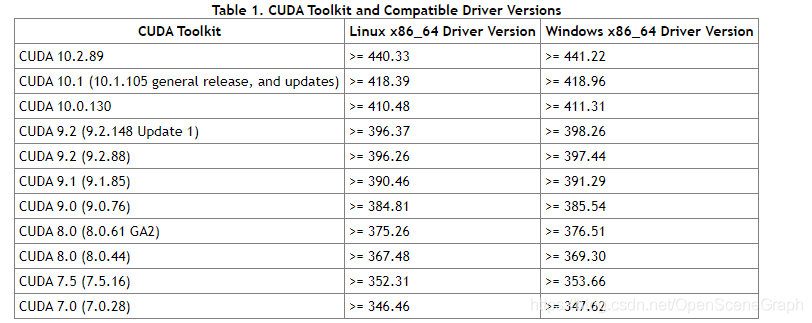
2. Download CUDA address
https://developer.nvidia.com/cuda-toolkit-archive
Or offline installation package download required in https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/. Tar..bz2
Background Conda Install XXXX.. tar.bz2
Install after installation is complete
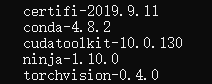
First anaconda Conda switches to the domestic source
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --set show_channel_urls yesConda Install Pytorch Torchvision Cudatoolkit =10.0
Install other packages
Pytorch official website: Pytorch official website
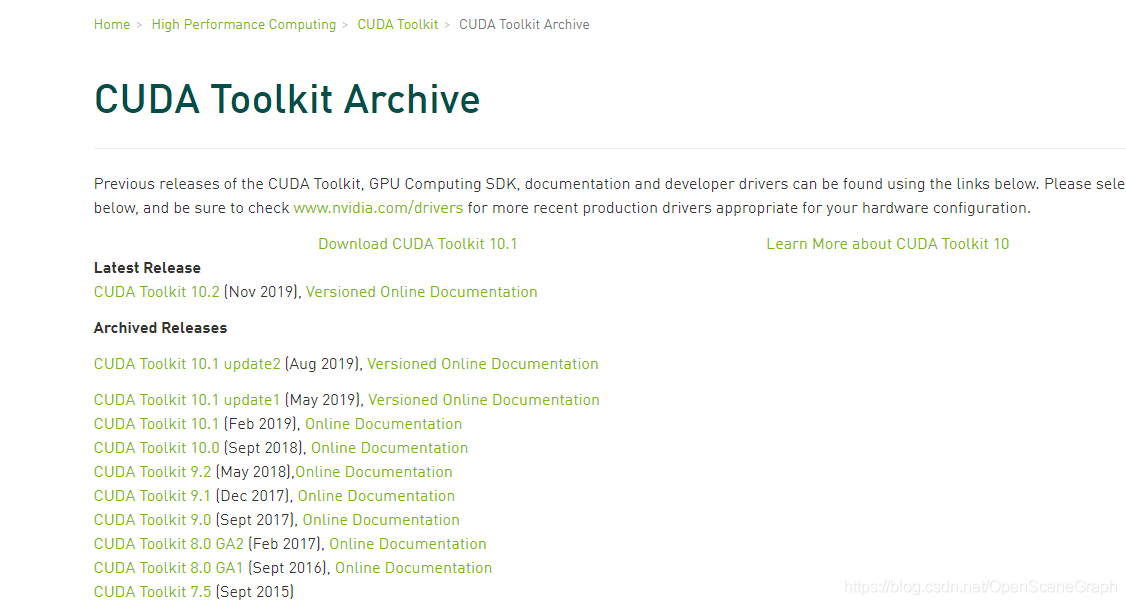
Download according to the actual situation:
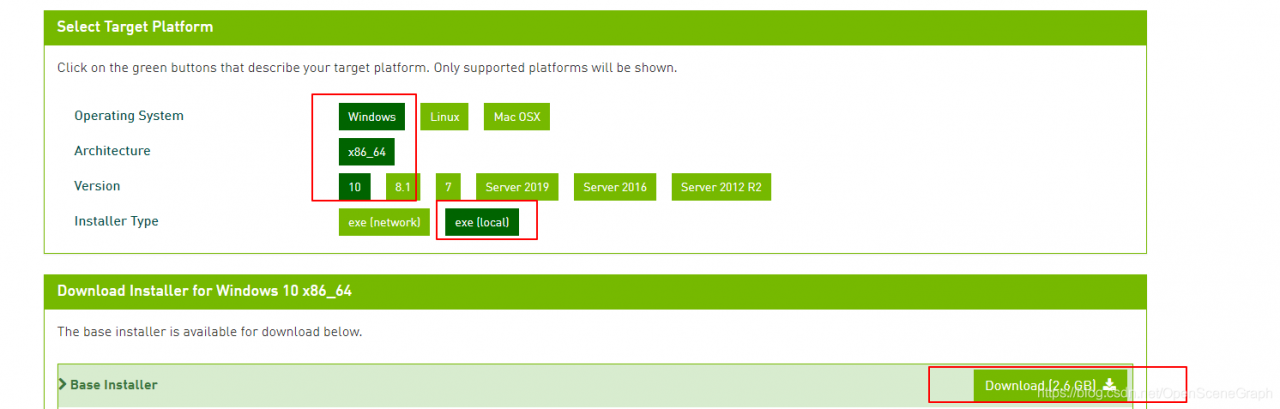
3. After successful download, double-click the exe file to install.
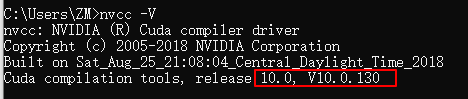
The verification method for successful installation is to enter nvcc-v under CMD
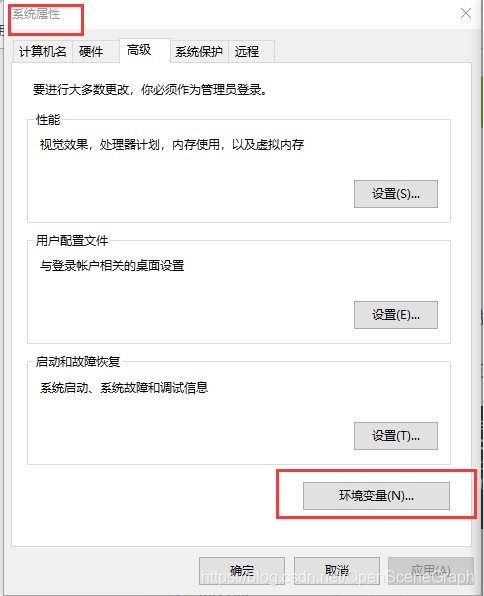
The installation was successful. You can see in system variables:

Or you can see nvCC.exe under the installation path
Read More:
- RuntimeError: cuDNN error: CUDNN_ STATUS_ EXECUTION_ Failed solutions
- Pytorch RuntimeError CuDNN error CUDNN_STATUS_SUCCESS (How to Fix)
- RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
- tensorflow2.1 Error:Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
- Tensorflow training could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR error
- check CUDA and CUDNN version
- RuntimeError: cudnn RNN backward can only be called in training mode
- PyTorch Error: RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE when calling cublasSgemm()
- RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
- [MMCV]RuntimeError: CUDA error: no kernel image is available for execution on the device
- Successfully solved runtimeerror: CUDA runtime error (30)
- RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
- [Solved] RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
- RuntimeError:cuda runtime error (11) : invalid argument at /pytorch/aten/src/THC/generic
- Error: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version
- Could NOT find CUDNN: Found unsuitable version “..“, but required is at least “6“
- FCOS No CUDA runtime is found, using CUDA_HOME=’/usr/local/cuda-10.0′
- RuntimeError: cuda runtime error (100) : no CUDA-capable device is detected at /opt/conda/conda-bld/
- (29)RuntimeError: cuda runtime error (999)
- PyTorch CUDA error: an illegal memory access was encountered