when running pytorch gpu, reported this error
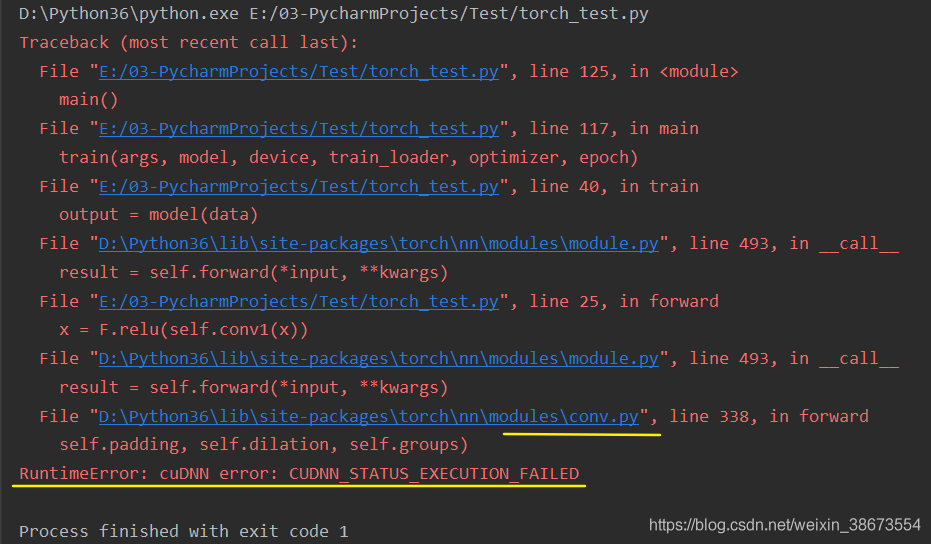
many people on the Internet also encountered this problem, some said that CUDA and cudnn version matching problem, some said that need to reinstall pytorch, CUDA, cudnn. I have checked the official website, the version is the match, trying to reinstall does not work, and I according to the version of another system can not install.
you can see that every time the error is in the file conv.py, which is the error made when doing the CNN operation.
The
solution is to introduce the following statement
import torch
torch.backends.cudnn.enabled = False
means you don’t need cudnn acceleration anymore.
GPU, CUDA, cudnn relationship is:
- CUDA is a parallel computing framework launched by NVIDIA for its own GPU. CUDA can only run on NVIDIA gpus, and can only play the role of CUDA when the computing problem to be solved can be massively parallel computing.
- cuDNN is an acceleration library for deep neural networks built by NVIDIA, and is a GPU acceleration library for deep neural networks. CuDNN isn’t a must if you’re going to use GPU to train models, but it’s usually used with this accelerator library.
reference: GPU, CUDA, cuDNN understanding
cudnn will be used by default. Since the matching problem cannot be solved at present, it is not used for now. The GPU will still work, but probably not as fast as cudNN.
if any friends know how to solve possible version problems, welcome to exchange ~
add:
- version: win10, python 3.6, pytorch 1.1.0, CUDA 9.0, cudnn 7.1.4
- test case: pytorch github Example Basic MNIST
Read More:
- RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
- (Solved) pytorch error: RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED (install cuda)
- Pytorch RuntimeError CuDNN error CUDNN_STATUS_SUCCESS (How to Fix)
- tensorflow2.1 Error:Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
- Tensorflow training could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR error
- RuntimeError: cudnn RNN backward can only be called in training mode
- RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
- check CUDA and CUDNN version
- Could NOT find CUDNN: Found unsuitable version “..“, but required is at least “6“
- [MMCV]RuntimeError: CUDA error: no kernel image is available for execution on the device
- [Solved] RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
- RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
- Solutions to the problem of collect2: error: LD returned 1 exit status
- Pytorch RuntimeError: Error(s) in loading state_ dict for Dat aParallel:.. function submit.py Solutions for reporting errors
- Solutions to the problem of “collect2.exe: error: LD returned 1” exit “status when writing C + + with vscode
- PyTorch Error: RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE when calling cublasSgemm()
- ’nvcc.exe‘ failed with exit status 1
- CUBLAS_STATUS_ALLOC_FAILED
- failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
- Solve runtimeerror: reduce failed to synchronize: device side assert triggered problem