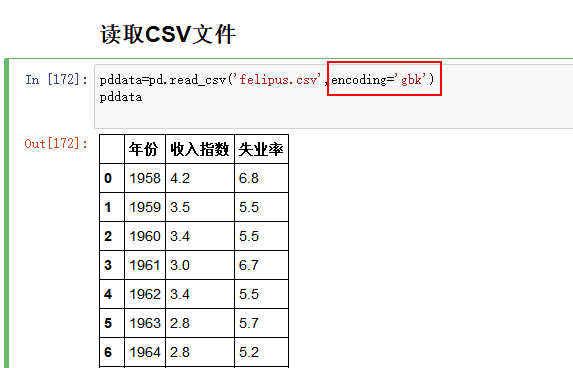
When using crypto JS to decrypt, an error may be reported:
Malformed UTF-8 data
Error: Malformed UTF-8 data
at Object.stringify (d:\StudeyCode\myStudy\encryptDemo\routes\encrypt\crypto-js.js:478:27)
at WordArray.init.toString (d:\StudeyCode\myStudy\encryptDemo\routes\encrypt\crypto-js.js:215:41)
at decryptByDESModeCBC (d:\StudeyCode\myStudy\encryptDemo\routes\encrypt\crypto.js:90:22)
at testSign (d:\StudeyCode\myStudy\encryptDemo\routes\test.js:34:18)
at Layer.handle [as handle_request] (d:\StudeyCode\myStudy\encryptDemo\node_modules\express\lib\router\layer.js:95:5)
at next (d:\StudeyCode\myStudy\encryptDemo\node_modules\express\lib\router\route.js:137:13)
at Route.dispatch (d:\StudeyCode\myStudy\encryptDemo\node_modules\express\lib\router\route.js:112:3)
at Layer.handle [as handle_request] (d:\StudeyCode\myStudy\encryptDemo\node_modules\express\lib\router\layer.js:95:5)
at d:\StudeyCode\myStudy\encryptDemo\node_modules\express\lib\router\index.js:281:22
at Function.process_params (d:\StudeyCode\myStudy\encryptDemo\node_modules\express\lib\router\index.js:335:12)The reason for the error is: when des decrypts, if the encrypted data is not an integral multiple of 8, the above error will be reported,
solution: encrypt the data, and then encrypt it with Base64. When decrypting, first decrypt it with Base64, and then decrypt it with DES. The above problems can be solved.

 !
!