When using Python to crawl a web crawler, it is common to assume that the target site has 403 Forbidden crawlers
Question: why are the 403 Forbidden errors
answer: urllib2.httperror: HTTPError 403: Forbidden errors occur mainly because the target website prohibits the crawler. The request header can be added to the request.
Q: So how do you solve it?
answer: just add a headers
req = urllib.request.Request(url="http://en.wikipedia.org"+pageUrl)
HTML = urlopen(req)
to add a headers to make it become
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = urllib.request.Request(url="http://en.wikipedia.org"+pageUrl, headers=headers)
# req = urllib.request.Request(url="http://en.wikipedia.org"+pageUrl)
html = urlopen(req)Q: How does Headers look?Answer: you can use the Internet in browser developer tools, such as 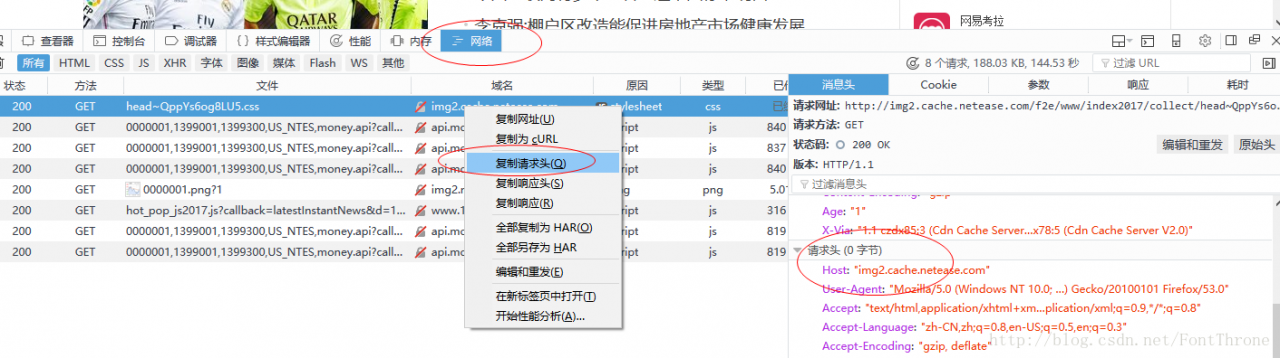 in firefox
in firefox
Q: Is there any other problem with pretending to be a browser?
answer: yes, for example, the target site will block the query too many times IP address
Reproduced in: https://www.cnblogs.com/fonttian/p/7294845.html
Read More:
- urllib2.HTTPError: HTTP Error 403: Forbidden
- raise HTTPError(req.full_url, code, msg, hdrs, fp)urllib.error.HTTPError: HTTP Error 404: Not Found
- Python crawler: urllib.error.HTTPError : HTTP Error 404: Not Found
- Python crawler urllib.error.HTTPError : HTTP Error 418:
- HTTPError HTTP Error 500 INTERNAL SERVER ERROR
- Attributeerror: the solution of module ‘urllib’ has no attribute ‘quote’
- python:urllib2.URLError urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed
- Solving attributeerror: module ‘urllib’ has no attribute ‘request’
- HTTP error 401 and 403 detailed explanation and solution
- urlopen error unknown url type:httpë/HTTP Error 400:Bad Request
- Error 403 Forbidden when using WGet or curl
- python: HTTP Error 505: HTTP Version Not Supported
- Forbidden (403) CSRF verification failed. Request aborted. – Django
- IOS development NSURLSession/NSURLConnection HTTP load failed solution
- urllib.error.URLError: <urlopen error [WinError 10060] problem solving
- The solution that ioni cannot use HTTP request after packaging apk
- GitHub push ErrorThe requested URL returned error: 403 Forbidden while accessing
- UFIDA’s common package download failed with error forbidden
- Solve GitHub push error 403 Forbidden while accessing
- Error in Git operation: http basic: access denied solution