Reason: list cannot be empty, and the content extracted by XPath may be empty, so I need to make a blank judgment
I use len to judge, and then do other processing
Tag Archives: reptile
This version of chromedriver only supports chrome version 92 crawler simulates the problem of Google plug-in version when the browser clicks and reports an error
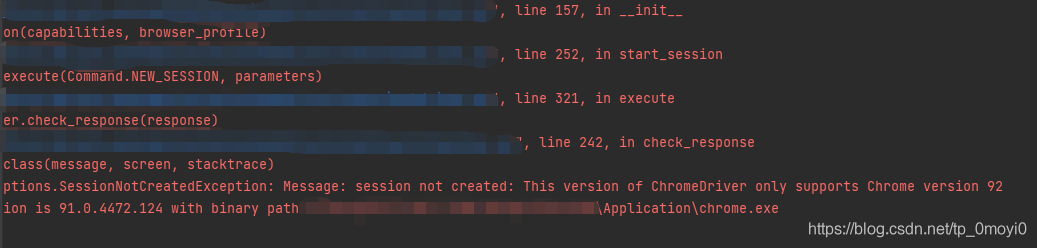
When the crawler simulates the browser’s click, an error is reported in the version of the Google plug-in. In this case, the driver of the Google browser stored locally is incorrect and needs to be updated. The specific solutions are as follows:
resolvent:
Open the following website and download the corresponding version of chromedriver. If you can’t find the exact version number, just find 91
http://chromedriver.storage.googleapis.com/index.htmlBe sure to download the driver according to your browser version
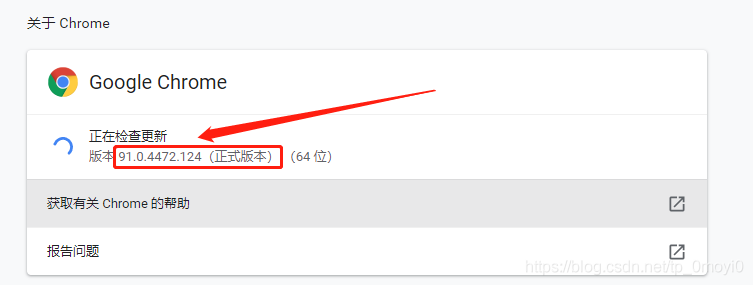
My version number is 91.0.4472.124, so I should download the driver corresponding to this version number. The website of download driver is the one above http://chromedriver.storage.googleapis.com/index.html
After clicking in, the interface is as follows
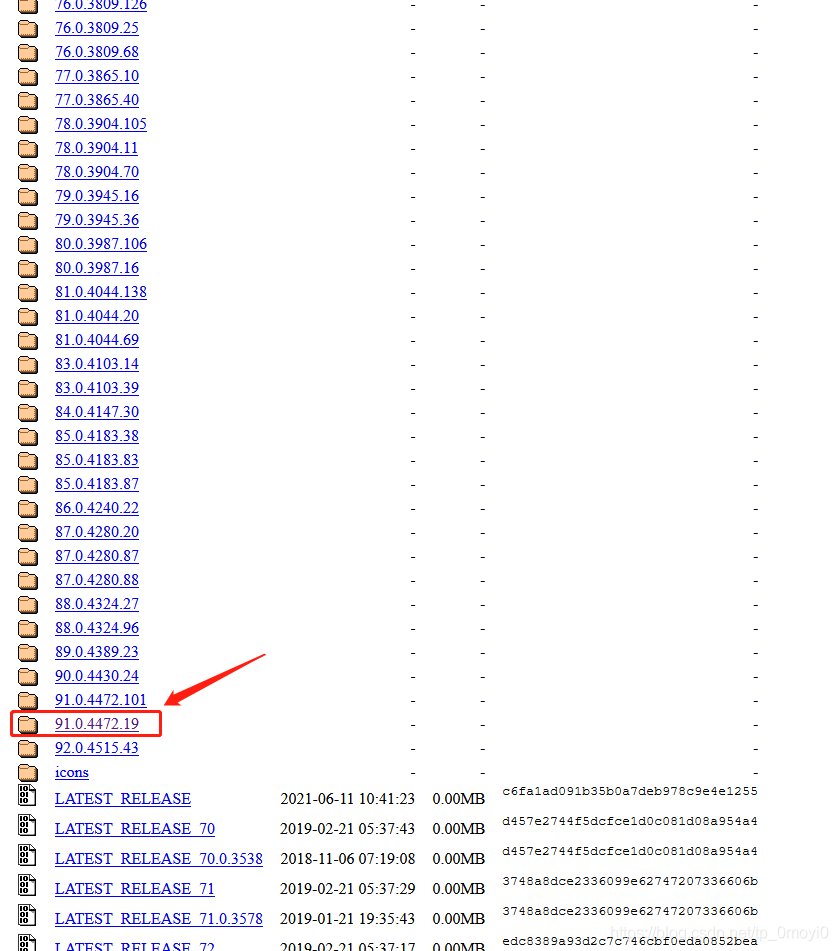
Then find the corresponding version file, download it, unzip it, and copy and paste it into the

In the program error report, you need to delete or cover the previous version in the path where you installed Google before
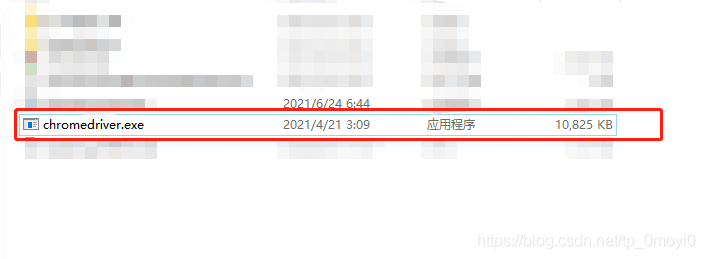
Leave this new version of the driver. In addition to that, I need to make a copy to the IDE environment where you are running. I use the code written in Python language here, so I need to make a copy of the driver file to the local installation path of Python
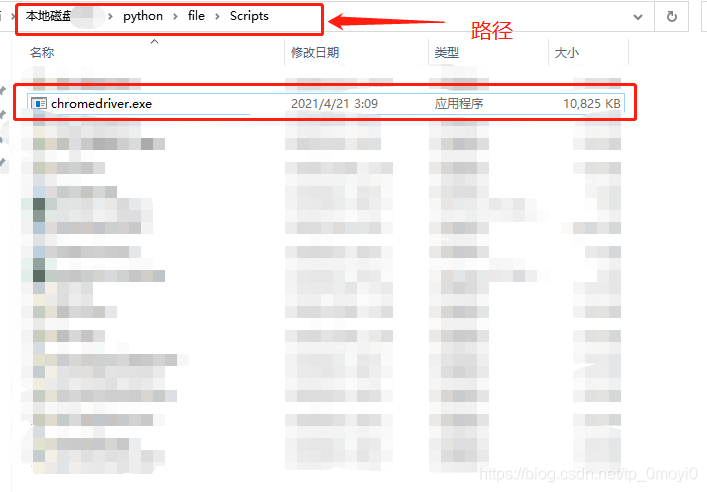
At last, it ran successfully

Use xx [‘xx ‘] = XX to set field value or does not support field: XXX
Demand:
After the tiem object is created, modify the written table of the original item_ Name value
My item:
class People(scrapy.Item):
table_name = 'people'
id = scrapy.Field()
url_token = scrapy.Field()
name = scrapy.Field()Solution:
people = People()
people.__class__.table_name='people_20216'Source code analysis:
If this is what the item says
table_name= scrapy.Field()
After creation, you can directly assign values in this way, which is normal operation
people = People()
people['table_name'] = 'people_20216'Situation 1:
But if you write like me:
class People(scrapy.Item):
table_name = 'people'In addition, it can be modified as follows:
people[‘table_ name’] = ‘people_ 20216’
You will report an error:
Traceback (most recent call last):
File "C:\Program Files\Python39\lib\site-packages\twisted\internet\defer.py", line 662, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "C:\Program Files\Python39\lib\site-packages\scrapy\utils\defer.py", line 150, in f
return deferred_from_coro(coro_f(*coro_args, **coro_kwargs))
File "E:\codedata\gitee\pySpace\study\npoms\npoms\pipelines.py", line 62, in process_item
item['table_name'] = item.table_name + "_" + mysql_split_util.current_year_month
File "C:\Program Files\Python39\lib\site-packages\scrapy\item.py", line 100, in __setitem__
raise KeyError(f"{self.__class__.__name__} does not support field: {key}")Corresponding to this section of the original code, the source code covers this:

Case 2:
If you write like this
people.table_ name’= ‘people_ 20216’
You will report an error:
Traceback (most recent call last):
File "C:\Program Files\Python39\lib\site-packages\twisted\internet\defer.py", line 662, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "C:\Program Files\Python39\lib\site-packages\scrapy\utils\defer.py", line 150, in f
return deferred_from_coro(coro_f(*coro_args, **coro_kwargs))
File "E:\codedata\gitee\pySpace\study\npoms\npoms\pipelines.py", line 63, in process_item
item.set_table_name(table_name)
File "E:\codedata\gitee\pySpace\study\npoms\npoms\items.py", line 66, in set_table_name
self.table_name = table_name
File "C:\Program Files\Python39\lib\site-packages\scrapy\item.py", line 112, in __setattr__
raise AttributeError(f"Use item[{name!r}] = {value!r} to set field value")
AttributeError: Use item['table_name'] = 'people_202106' to set field valueCorresponding to this section of the original code, the source code also has corresponding interception:

At this time, we need to look at the creation phase of the source code object
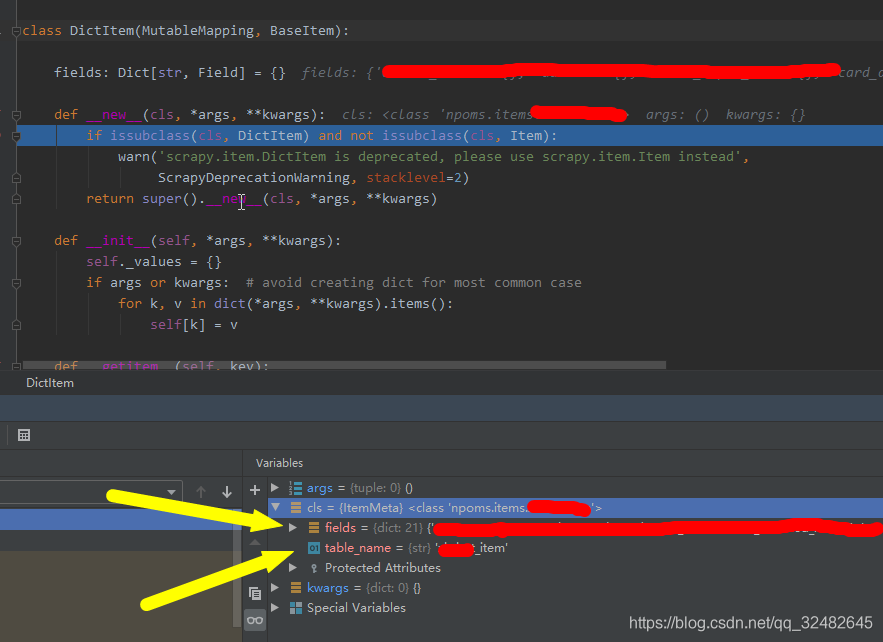
The object creation phase is divided into fields and classes, which we can use above__ setitem__ Method to modify the object in fields. So we need to get the class object and modify the values of the properties in the class.
Solution to Error 400. The request has an invalid header name
I encountered this problem today, and then Searched baidu, Bing and Google. I saw many blogs that wrote about this problem. To be honest, it was not helpful at all, so I spent 2 hours to find the reason by myself. The reason for this error is very simple. The reason for this error is that the header part is wrong. 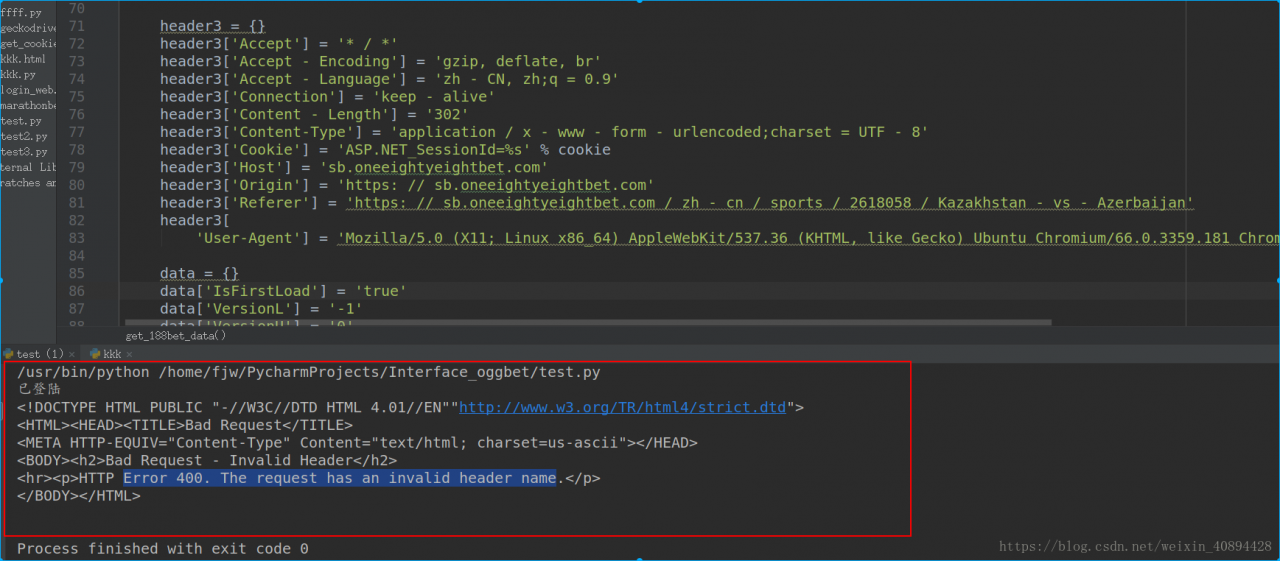 may be the direct cause of the error, as some browsers have different formats, which may lead to extra white space in the header information when you paste it into the code
may be the direct cause of the error, as some browsers have different formats, which may lead to extra white space in the header information when you paste it into the code
I’m copying and pasting this piece of code when I add header information, is that okay?But if you look closely at the content-type part, isn’t there a lot of space?Just delete the Spaces and you’re done.
I modified
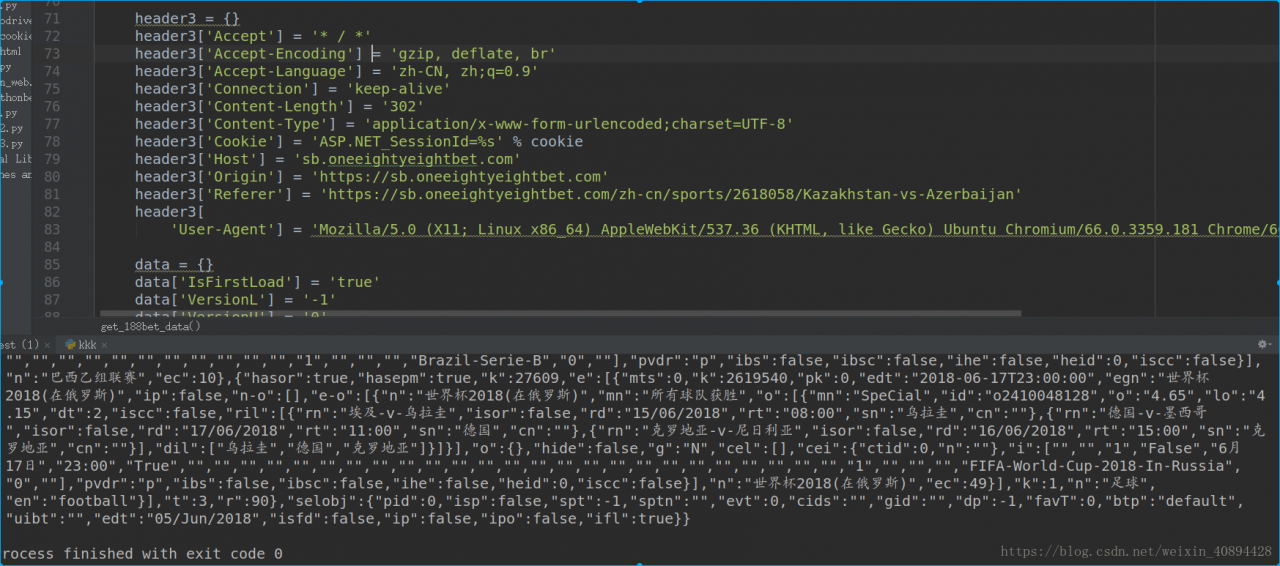
Crawl out of the data perfectly.
The first blog in my life, I hope you will pay more attention to me, I will continue to publish the blog about crawler in the future!!
may be the direct cause of the error, as some browsers have different formats, which may lead to extra white space in the header information when you paste it into the codeI’m copying and pasting this piece of code when I add header information, is that okay?But if you look closely at the content-type part, isn’t there a lot of space?Just delete the Spaces and you’re done.
I modified
Crawl out of the data perfectly.
The first blog in my life, I hope you will pay more attention to me, I will continue to publish the blog about crawler in the future!!
ImportError: ‘DLL load failed: %1 is not a valid Win32 application.
Problem description
Windows: 64-bit win7 system
python: download from the official website is python 2.7.2 64-bit. The actual folder would look like this:

Then install scrapy and try scrapy. CMD: open the command prompt, enter scrapy shell http://cn.bing.com/
and output a heap. The last line: ImportError: No module named win32api.
Go to http://sourceforge.net/projects/pywin32/files/pywin32/ to download win32api
select version for pywin32-219. The win – amd64 – py2.7. Exe, (because the system is 64, so choose amd64)
Install the win32api.
and then enter the command prompt: scrapy shell http://cn.bing.com/
. The last line: ‘scrapy shell: DLL load failed: %1 is not an valid Win32 application.’
An attempt to solve a problem
View the information on the Internet, pywin32-219. Win-amd64-py2.7. exe to reinstall, but the problem is still in, in python IDE input Import Win32API, or the above problems, that is to say, this problem as to Win32API, has nothing to do with the package installed.
Since I installed other Python versions yesterday (the file is integrated), the Python file is confused, so I uninstall Python again, delete the Python path in the system environment variable path and the python file in the registry, find python methods in the registry, and enter: HKEY_CURRENT_USER – > The software.
Reinstall Python, follow the previous steps again, and you get the same error.
looked at the messy material on the Internet.
then try it:
Message: failed to decode response from marionette
is thrown because of an error in the title:
Message: Tried to run command without establishing a connection
interprets:
to start with my crawler architecture, I use firefox+selenium. The error above is caused by the fact that after the browser exits, the crawler needs the browser to execute some commands, so the error appears. The second problem comes:
Why does the
browser crash automatically?Generally speaking, it is because it is running out of resources. What resources?Memory resources, the browser is very occupied memory, and some crawlers in order to speed up the crawler will let the browser do cache,
this results in the browser taking up more memory
solution:
1. According to the resource occupied by the crawler, increase the memory
appropriately
2. Slow down the crawler speed and make the browser a little idle, especially in the crawler that starts multiple browsers
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — the 2019-04-24 update — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
the above statement is not wrong, but some is not taken into account, the browser will actually the main reason for the collapse because the browser memory leaks, that is to say, because the default browser is open caching function,
as the crawler runs, the cache of the browser will become larger and larger, which will eventually lead to the memory leak of the browser ( premise is that the browser does not restart the crawler, if the browser restarts after a period of time, there will be no problem ),
as for how to disable browser cache in crawlers, this is mentioned in my other blog, but not
reproduced in: https://www.cnblogs.com/gunduzi/p/10600152.html
When we crawl to the HTTPS website, the SSL certificate error is solved
SSL certificate error occurs when we crawl HTTPS sites
HTTPS in plain English is our HTTP + SSL (certificate), some small companies make their own SSL, so sometimes when we visit the website of some small companies it will remind us to download some SSL certificates, and the website that we don’t have to download has been CA certified
we are going to crawl an SSL certificate that is not a CA certified web address to verify.
when we climb to find the problem of error. 