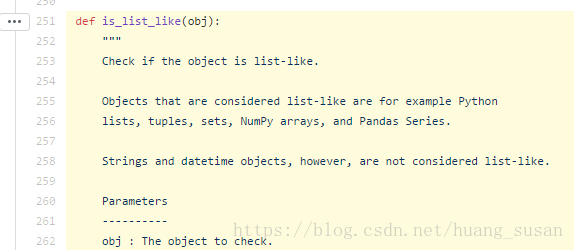
In text processing, we are interested in words or phrases that will help us differentiate the given text from the other text in the corpus. Let’s call these words or phrases as
key
phrases. Every text mining application needs a way to find out the key phrases. An information retrieval application needs key phrases for the easy retrieval and ranking of search results. A text classification system needs key phrases as its features that are to be fed to a classifier. This is where stop words come into the picture. “
Sometimes, some extremely common words which would appear to be of little value in helping select documents matching a user need are excluded from the vocabulary entirely. These words are called
stop words. ” Introduction to Information Retrieval By Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze.
Tip Remember that stop word removal is contextual and based on the application. If you are working on a sentiment analysis application on mobile or chat room text, emoticons are highly useful. You don’t remove them as they form a very good feature set for the downstream machine learning application. Typically, in a document, the frequency of stop words is very high. However, there may be other words in your corpus that may have a very high frequency. Based on your context, you can add them to your stop word list.
The Python NLTK library provides us with a default stop word corpus that we can leverage, as follows:
>>> from nltk.corpus import stopwords
>>> stopwords.words('english')
[u'i', u'me', u'my', u'myself', u'we', u'our', u'ours', u'ourselves',
u'you', u'your', u'yours', u'yourself', u'yourselves', u'he', u'him',
u'his', u'himself', u'she', u'her', u'hers', u'herself', u'it', u'its',
u'itself', u'they', u'them', u'their', u'theirs', u'themselves', u'what',
u'which', u'who', u'whom', u'this', u'that', u'these', u'those', u'am',
u'is', u'are', u'was', u'were', u'be', u'been', u'being', u'have', u'has',
u'had', u'having', u'do', u'does', u'did', u'doing', u'a', u'an', u'the',
u'and', u'but', u'if', u'or', u'because', u'as', u'until', u'while', u'of',
u'at', u'by', u'for', u'with', u'about', u'against', u'between', u'into',
u'through', u'during', u'before', u'after', u'above', u'below', u'to',
u'from', u'up', u'down', u'in', u'out', u'on', u'off', u'over', u'under',
u'again', u'further', u'then', u'once', u'here', u'there', u'when',
u'where', u'why', u'how', u'all', u'any', u'both', u'each', u'few',
u'more', u'most', u'other', u'some', u'such', u'no', u'nor', u'not',
u'only', u'own', u'same', u'so', u'than', u'too', u'very', u's', u't',
u'can', u'will', u'just', u'don', u'should', u'now']
example:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
@author: snaildove
"""
# Load libraries
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import string
text = "Text mining, also referred to as text data mining, roughly equivalent to text analytics,refers to the process of deriving high-quality information from text. Highquality information is typically derived through the devising of patterns and trends through means such as statistical pattern learning. Text mining usually involves the process of structuring the input text (usually parsing, along with the addition of some derived linguistic features and the removal of others, and subsequent insertion into a database), deriving patterns within the structured data, and finally evaluation and interpretation of the output. 'High quality' in text mining usually refers to some combination of relevance, novelty, and interestingness.Typical text mining tasks include text categorization, text clustering, concept/entity extraction, production of granular taxonomies, sentiment analysis, document summarization, and entity relation modeling (i.e., learning relations between named entities).Text analysis involves information retrieval, lexical analysis to study word frequency distributions, pattern recognition, tagging/annotation,information extraction, data mining techniques including link and association analysis, visualization, and predictive analytics. The overarching goal is,essentially, to turn text into data for analysis, via application of natural language processing (NLP) and analytical methods.A typical application is to scan a set of documents written in a natural language and either model the document set for predictive classification purposes or populate a database or search index with the information extracted."
#Let’s now demonstrate the stop words removal process:
#we will tokenize the input text into words using the word_tokenize function. The words is now a list of all the words tokenized from the input.
words = word_tokenize(text)
# 2.Let us get the list of stopwords from nltk stopwords english corpus.
stop_words = stopwords.words('english')
print "Number of words = %d"%(len(words))
# 3. Filter out the stop words.
words = [w for w in words if w not in stop_words]
print "Number of words,without stop words = %d"%(len(words))
#Here, we will run another list comprehension in order to remove punctuations from our words.
words = [w for w in words if w not in string.punctuation]
print "Number of words,without stop words and punctuations = %d"%(len(words))
output :
Number of words = 257
Number of words,without stop words = 193
Number of words,without stop words and punctuations = 155
Tip Remember that
stop word removal is contextual and based on the application. If you are working on a sentiment analysis application on mobile or chat room text, emoticons are highly useful. You don’t remove them as they form a very good feature set for the downstream machine learning application. Typically, in a document, the frequency of stop words is very high. However, there may be other words in your corpus that may have a very high frequency. Based on your context, you can add them to your stop word list.
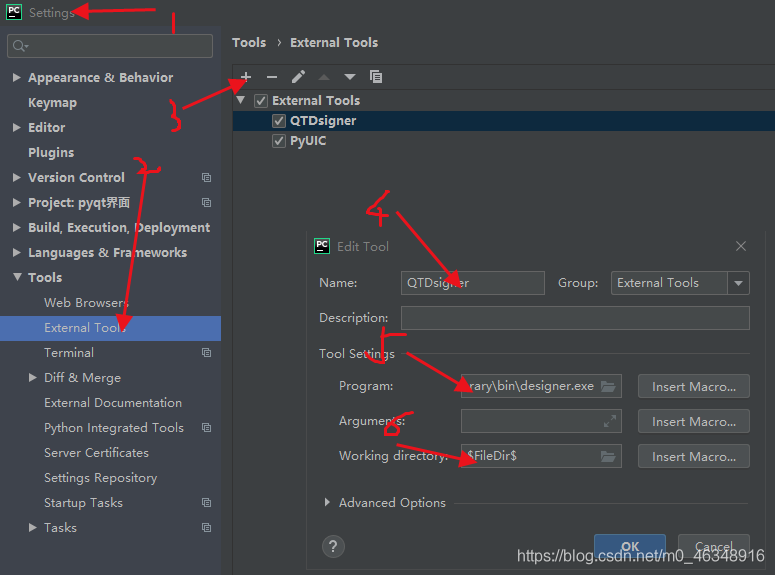

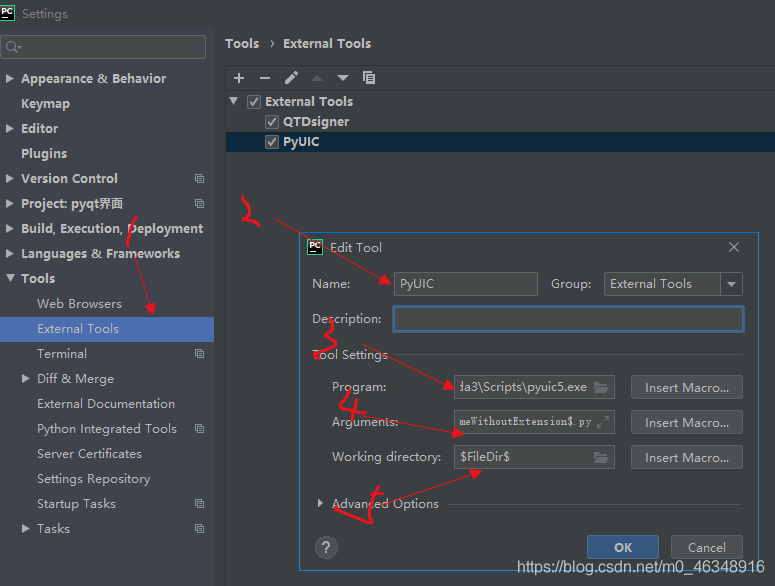
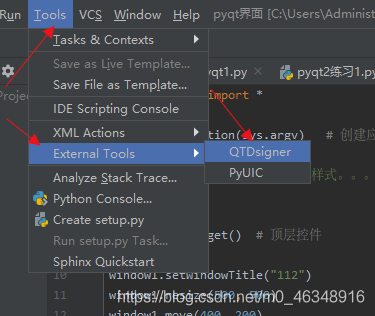
 in the following path
in the following path