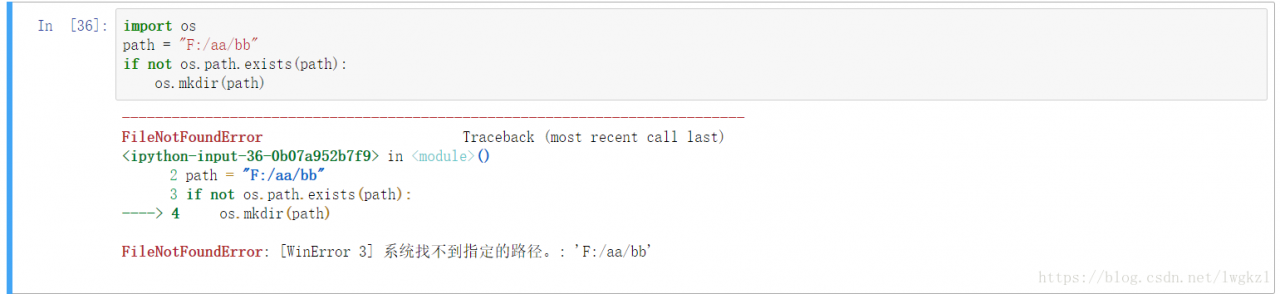
Today’s implementation B= webdriver.Firefox () is an error report. My version is 19.0 for Firefox and 2.37 for selenium.
In the following two cases: A, B,
All of them are caused by the incompatibility between the firebox version and selenium version http://docs.seleniumhq.org/about/platforms.jsp Page to view the version information of Microsoft supported by selenium
(it is found that selenium does not support firebox version 19.0)
A.
Traceback (most recent call last):
File “C:\Users\tomet\Desktop\a.py”, line 10, in <module>
b = webdriver.Firefox ()
File “C:\Python27\lib\site-packages\selenium\webdriver\firefox\ webdriver.py “, line 59, in __ init__
self.binary , timeout),
File “C:\Python27\lib\site-packages\selenium\webdriver\firefox\extension_ connection.py “, line 47, in __ init__
self.binary.launch_ browser( self.profile )
File “C:\Python27\lib\site-packages\selenium\webdriver\firefox\firefox_ binary.py “, line 61, in launch_ browser
self._ wait_ until_ connectable()
File “C:\Python27\lib\site-packages\selenium\webdriver\firefox\firefox_ binary.py “, line 105, in _ wait_ until_ connectable
self.profile.path , self._ get_ firefox_ output()))
WebDriverException: Message: “Can’t load the profile. Profile Dir: c:\\users\\chengh~1.qun\\appdata\\local\\temp\\tmpqdnfky Firefox output: *** LOG addons.xpi : startup\r\n*** LOG addons.xpi : Skipping unavailable install location app-system-local\r\n*** LOG addons.xpi : Skipping unavailable install location app-system-sha re\r\n*** LOG addons.xpi : checkForChanges\r\n”
B.
startupinfo() error 87
Copyright notice: This article is the original article of the blogger and cannot be reproduced without the permission of the blogger.
Reproduced in: https://www.cnblogs.com/think1988/p/4627912.html