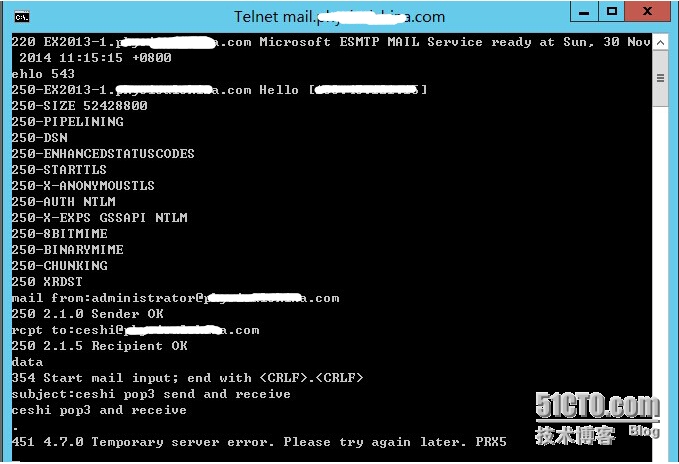
4.7.0 Temporary Server Error. Please try again later. PRX5 solves the instance
It’s sunny and beautiful this morning! Suddenly, I received a call from a customer, saying that all outlook POP3 of their Company’s Exchange 2013 could not be used normally. The user and password verification box popped up, and it was of no use to enter the password repeatedly or confirm directly.
After communication, I was informed that there was a similar fault before, that was when the service of POP stopped and started, and no modification was made recently. After learning the situation, I logged in to the server remotely and checked that the Exchange service was started normally without any problems.
So I quickly configured a POP mode on my computer, and I got an error when Verifying the user name and password. It didn’t matter if I entered the password repeatedly or confirmed it directly, as described by the customer, as shown in the figure below
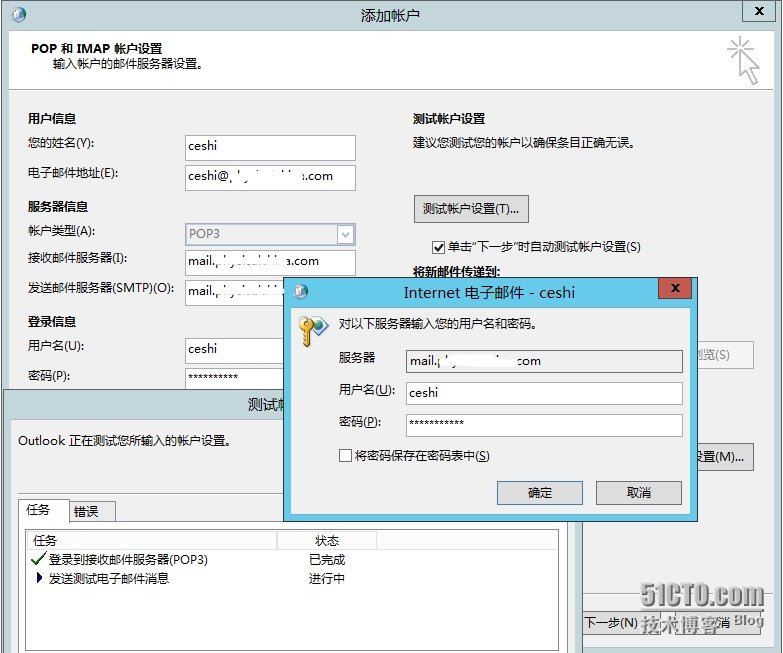
What do you do next?Restart the server?This is the next best thing. Maybe a restart can solve your problem temporarily, but the reason is not found, and the problem recurs later. How to deal with it?
451 4.7.0 Temporary Server Error. Please try again later. PRX5
The Telnet test format is as follows:
telnet mail.xxx.com 25
Ehlo XXX or HELo, [ESMTP ehlo XXX, SMTP HELo, I’ll fill ehlo XXX, XXX whatever]
Mail from:[email protected][administrator address]
RCPT to:[email protected][recipient address]
Data [Start writing email]
From :XXX[sender address]
To :XXX[Recipient address]
Subject: CEShi pop3 Send and Receive [subject]
Ceshi pop3 send and receive[Note: The body of the email should be blank, otherwise it will be automatically determined as the subject. If you want to send Chinese, you need to download Telnet client separately, see attachment]
.[End of message identifier]
Normally it will prompt you that the message has been queued for sending
Quit [After sending the email]
Step 1. Google the cause of the error and find the solution to the problem.
Reference 1.
https://social.technet.microsoft.com/Forums/exchange/en-US/fc26dac5-d4e2-49da-903d-361ea8b85388/451-470-temporary-server-error-please-try-again-later-prx5
I talked to a MS support rep today and they confirmed the same problem, except to resolve it we had to add the local server’s IP to our hosts file:
192.168.1.5 server
192.168.1.5 server. The domain. The local
Restart “Microsoft Frontend Transport” and “Microsoft Exchange Transport” services
The support agent stated that he’s seen this in a few cases now. All of which are when the Exchange server front and back-ends reside on the same box. Sounds like an Exchange bug to me.
Reference 2,
http://blog.5dmail.net/user1/1/2014414174021.html
Exchange Server 2013 cannot receive emails sent from outside. Remote Host said: 451 4.7.0 Temporary Server Error. Please try again later. PRX2
[Reason analysis]
The Exchange Server 2013 in question was installed with multiple roles. Including the mailbox and client access roles of DOMAIN control and Exchange 2013, and because the client server is hosted in the computer room, it is equipped with two network CARDS, which are configured with an Intranet IP and a public network IP respectively, the fault is mainly caused by the two network CARDS using different DNS.
Step 2: Modify the local C:\Windows\System32\drivers\etc\ hosts file, add and save the local records of Exchange 2013 server.
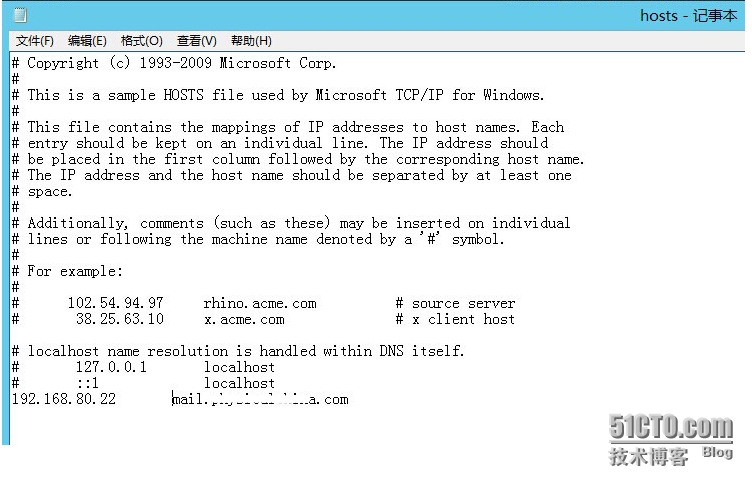
Step 3. Check the Exchange server and THE AD domain server, and check that the DNS is pointing to the inside and there is no record pointing to the outside.
Step 4. Restart the “Microsoft Frontend Transport” and the “Microsoft Exchange Transport” services
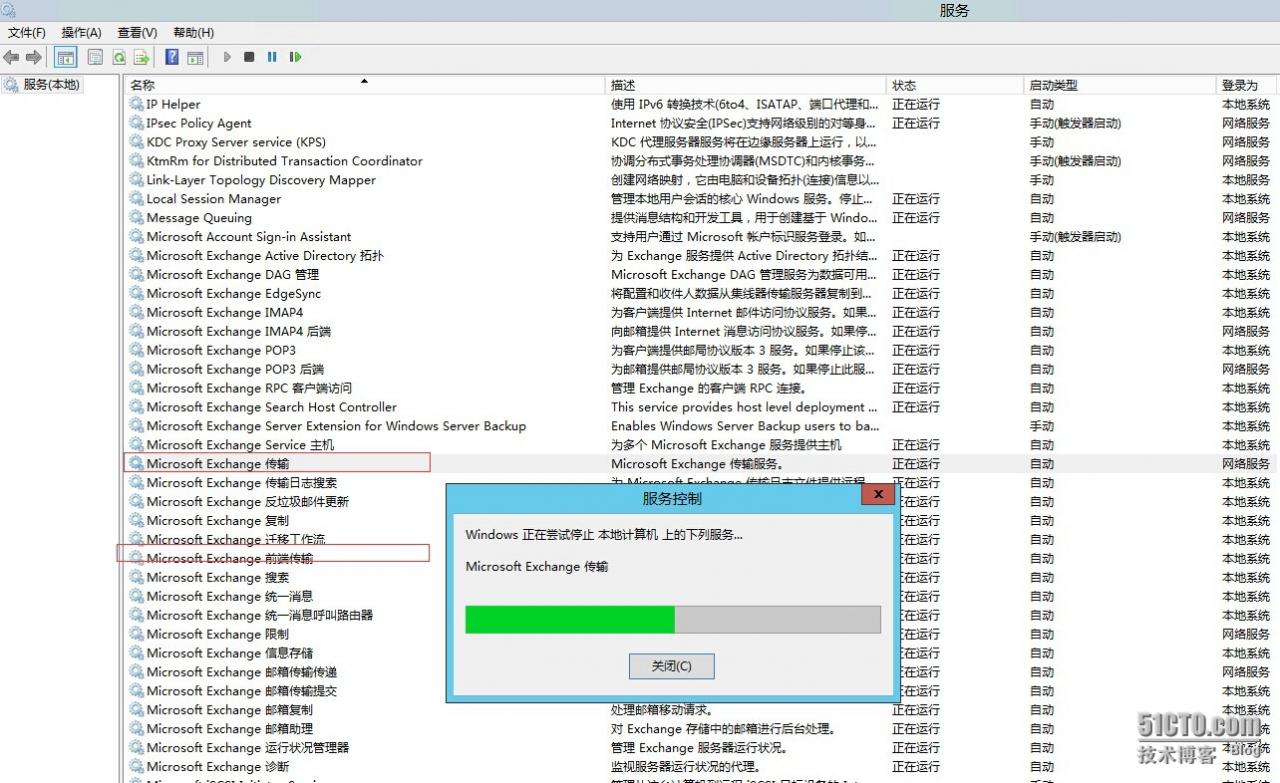
Step 5: If you restart the “Microsoft Frontend Transport”, the Transport service has stopped and cannot get up, restart the server?No, we open the task manager, find Msexchangetransport.exe finish the task and restart the Transport service.
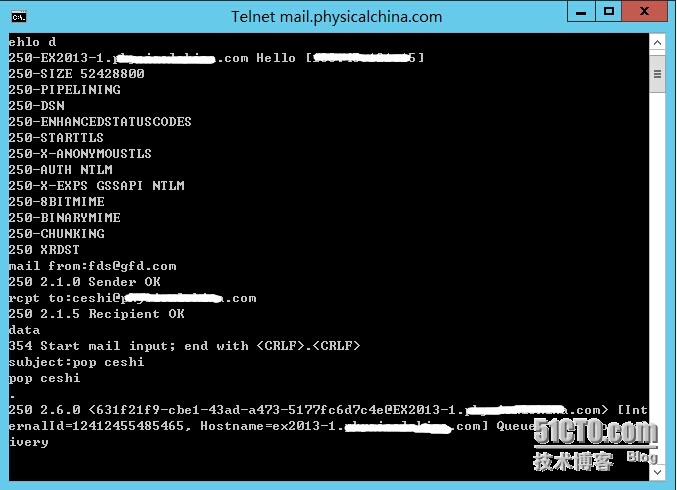
Step 6. After the processing, we tested a Telnet test. The specific method referred to the description in the previous part of the article, and the email was successfully sent.
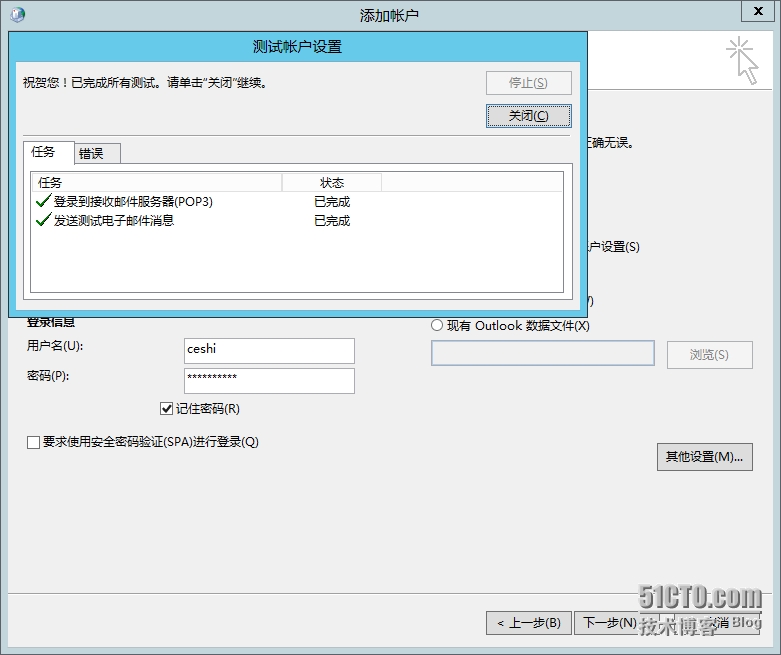
Step 7. When opening Outlook, the test has been successfully tested, the receiving and sending is normal, and there is no password box prompt, and the fault is solved. Thank you for your patience to watch, thank you!
Reproduced in: https://blog.51cto.com/yuntcloud/1584670