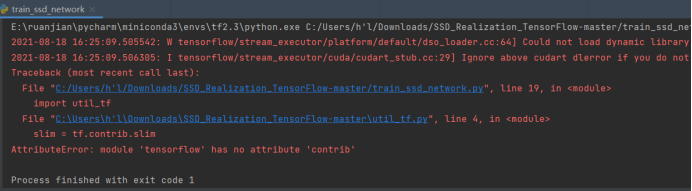
There is a line of code c = np.fromfile(“b.dat”, dtype=np.int, sep=”,”) when running Error,The content is as follows:
DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20 .0-notes.html#deprecations
c = np.fromfile(“b.dat”, dtype=np.int, sep=”,”)
Reason: numpy1.20 has deprecated np.int, checked my version
![]()
The numpy version has reached 1.23.2
Solution: Change to np.int16/np.int32 directly to specific bytes or change to np.int_
Run again, problem-solved!