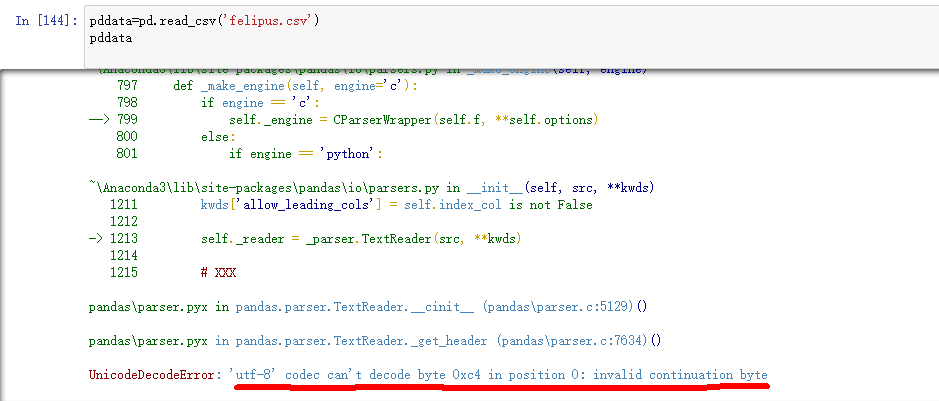
Reading CSV document with Pandas is an error that cannot be read because there is Chinese in the document. The error is due to the failure of the 'utf-8' codec to decode the 0 bit byte 0xc4
Solutions:
After reading the file, add encoding=’ GBK ‘,
such as: pddata=pd. Read_csv (' felipe.csv ',encoding=' GBK ')
Interested to continue to see the reason!
As you know, the default encoding we use in Python is UTF-8. For an introduction to coding, I recommend taking a look at Liao Da’s Python tutorial, “Strings and Coding.” Since UTF-8 format cannot correctly read CSV files with Chinese characters, it would be a good idea to select a format that can read Chinese characters.
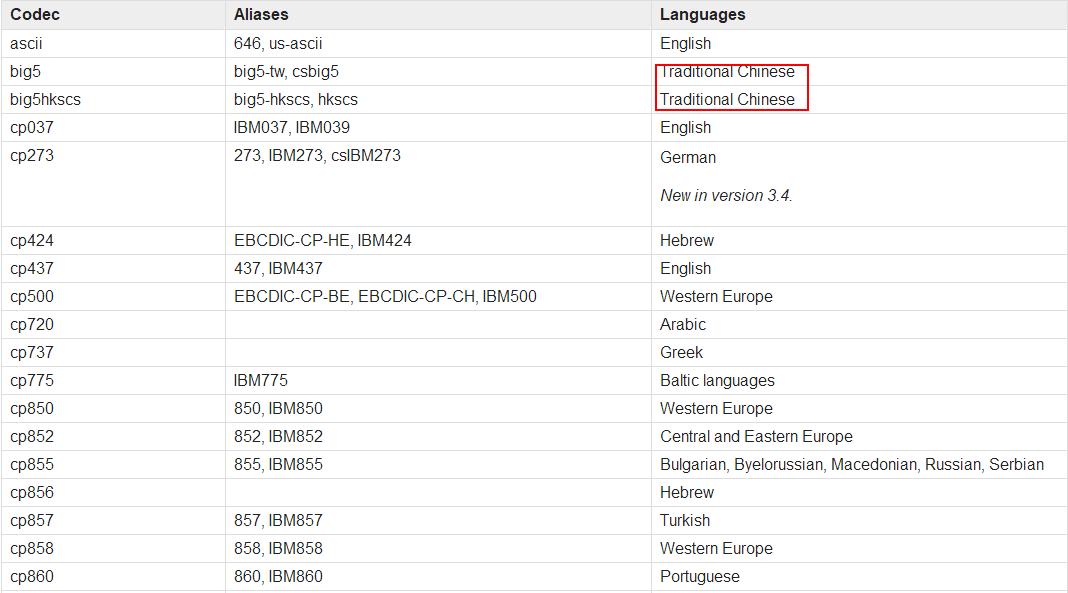
So what format can read Chinese characters?We open the Python3 official website: find the section on standard characters. The diagram below:

So what format do you want to change?You can see that the third column of the table, Language, represents what Language the encoding supports. So let’s find out.
 !
!
I’m not going to show you the table here, but if you’re interested, go to the website. Anyway, under my careful search, there is big5; Big5hkscs; Gb2312; GBK; Gb18030. Hz; The five formats iso2022_jp_2 may support Chinese. After my test, I found gb2312; GBK; Gb18030 can read CSV files with Chinese smoothly. (Since all three are ok, let’s have a good GBK.)
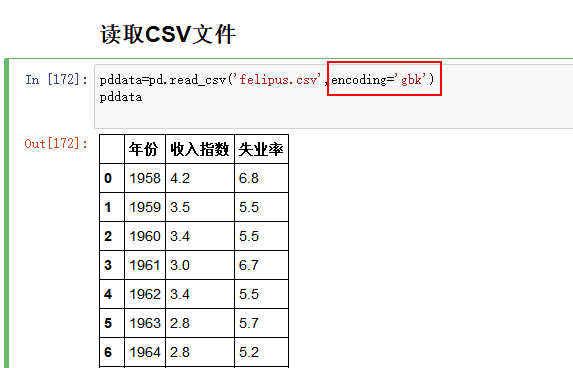
It works!