RuntimeError: CUDA error: CUBLAS_ STATUS_ ALLOC_ FAILED when calling cublasCreate(handle)
Exception raised from createCublasHandle at … \aten\src\ATen\cuda\ CublasHandlePool.cpp : 8 (most recent call first):
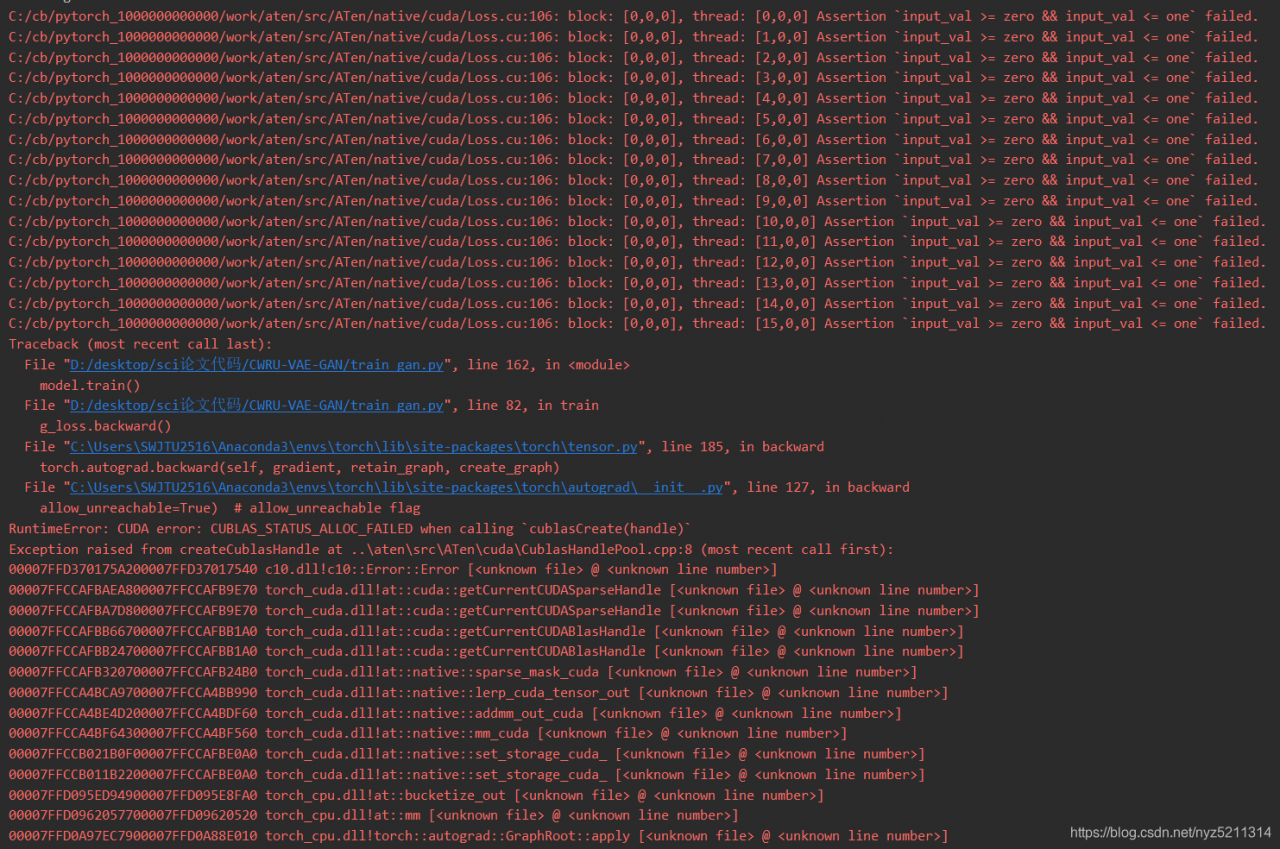
record the bug of dcgan in Python training..
It took a long time to find out that the last line of the discriminator did not add sigmoid, which caused the tag to go beyond the range [0,1], so an error was reported.