Read and write BMP image with pure C language
For the students who have just come into contact with digital images, there should be a question about how to read a BMP image in pure C language. I believe this is also the first step of digital image processing. If I am lucky to see this document, I will be the first light on your digital image processing road!
Understanding the composition of BMP
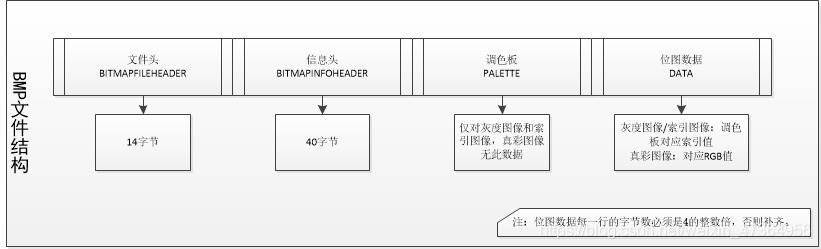
Don’t talk too much nonsense, just load the dry goods.
code
Define the header file as “BMP. H”, and define read_ BMP function is read function, write function_ BMP function is write function
read BMP diagram
#include <stdlib.h>
#include <math.h>
#include <Windows.h>
#include "bmp.h"
/* store the pixel width height and bitmap depth of the original image */
FILE* fpbmp;
FILE* fpout;
unsigned char* fpBmpHeader; //bitmap header
unsigned char* fpFileHeader; //bitmap information
RGBQUAD* pColorTable; //BMP palette
int read_bmp(const char* path, unsigned char *pBmpBuf,int *Width,int *Height,int * bitCount)
{
fpbmp = fopen(path, "rb");//path is the image path
unsigned short s;
fread(&s, 1, 2, fpbmp);
//judge whether the read image is a BMP image string"BM"=19778
if (s == 19778)
{
printf("Open bmp success!!!\n");
}
else
{
printf("Open bmp fail!!!\n");
return -1;
}
fseek(fpbmp, 0, SEEK_SET);
BITMAPFILEHEADER fileHead;
fread(&fileHead, sizeof(BITMAPFILEHEADER), 1, fpbmp);
BITMAPINFOHEADER infoHead;
fread(&infoHead, sizeof(BITMAPINFOHEADER), 1, fpbmp);
*Width = infoHead.biWidth;
*Height = infoHead.biHeight;
*bitCount = infoHead.biBitCount;
int lineByte = (*Width * *bitCount/8 + 3)/4 * 4;
fseek(fpbmp, sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER) + sizeof(RGBQUAD),SEEK_SET);
fread(pBmpBuf, lineByte * *Height, 1, fpbmp);//pBmpBuf is the RGB data of the image, which is also the data we will process
return 0;
}
Write BMP map
int write_bmp(unsigned char* img, int* Width, int* Height, int* bitCount)
{
fpout = fopen("out.bmp", "wb+");
if (fpbmp == NULL)
{
printf("read bmp failed!!!\n");
return -1;
}
int lineByte = (*Width * *bitCount/8 + 3)/4 * 4;
if (lineByte == 0)
{
printf("err");
return -1;
}
fpFileHeader = new unsigned char[(sizeof(BITMAPFILEHEADER))];
fseek(fpbmp, 0, SEEK_SET); //Position the original image Offset position
fseek(fpout, 0, SEEK_SET); //position the new map Offset position
fread(fpFileHeader, 1, sizeof(BITMAPFILEHEADER), fpbmp);
fwrite(fpFileHeader, 1, sizeof(BITMAPFILEHEADER), fpout);
fpBmpHeader = new unsigned char[(sizeof(BITMAPINFOHEADER))];
fseek(fpbmp, sizeof(BITMAPFILEHEADER), SEEK_SET);
fseek(fpout, sizeof(BITMAPFILEHEADER), SEEK_SET);
fread(fpBmpHeader, 1, sizeof(BITMAPINFOHEADER), fpbmp);
fwrite(fpBmpHeader, 1, sizeof(BITMAPINFOHEADER), fpout);
pColorTable = new RGBQUAD[256];
fseek(fpbmp, sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER), SEEK_SET);
fseek(fpout, sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER), SEEK_SET);
fread(pColorTable, sizeof(RGBQUAD), 256, fpbmp);
fwrite(pColorTable, sizeof(RGBQUAD), 256, fpout);
fseek(fpout, sizeof(BITMAPFILEHEADER) + sizeof(BITMAPINFOHEADER) + sizeof(RGBQUAD), SEEK_SET);
fwrite(img, lineByte * *Height, sizeof(char), fpout);
fclose(fpout);
fclose(fpbmp);
return 0;
}
Main function call
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <Windows.h>
#include "bmp.h"
int main()
{
int width, height, bitCount = 0;
unsigned char* pBmpBuf = (unsigned char*)malloc(1000 * 1000 * 3);
const char* path = "D:\\test\\read_bmp_image\\1-B.bmp";
read_bmp(path, pBmpBuf, &width, &height, &bitCount);
write_bmp(pBmpBuf, &width, &height, &bitCount);
}
Summarize, read_ The pbmpbuf parameter returned by BMP function is assigned to write_ The IMG parameter of BMP function realizes the whole process of BMP graph from reading to writing. If you are interested in it, you will get unexpected results.
Note: the website of online conversion BMP map can convert any format photos to BMP format. It’s easy to use. Link to BMP image conversion website

 appears, the installation is successful and the problem is solved.
appears, the installation is successful and the problem is solved.