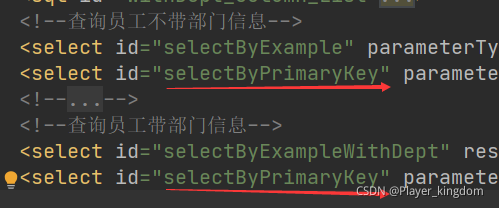
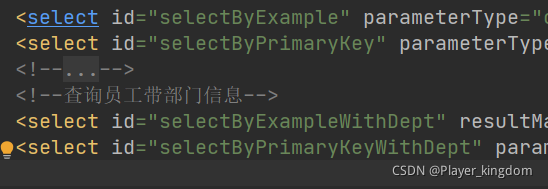
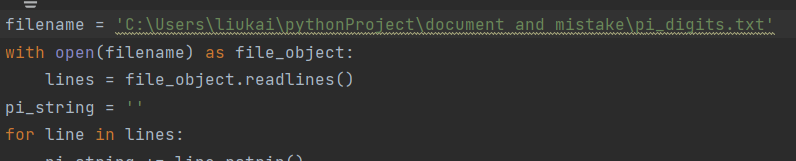
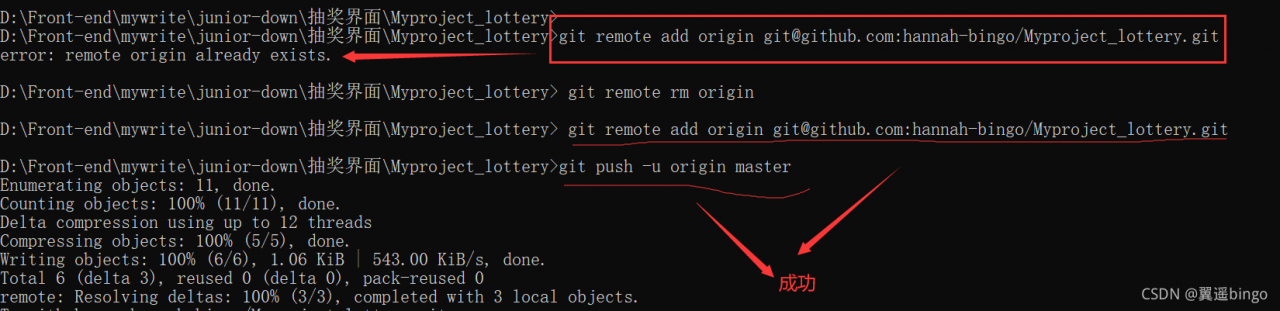
Solution
add the following code to the PY header of the operation picture:
from PIL import JpegImagePlugin
JpegImagePlugin._getmp = lambda x:None
mime = mimetypes.types_ Map [true] [ext]
keyerror: ‘. MPO’
the above error occurs when using openpyxl to operate the pictures in Excel. Baidu has not. After a visit to Google, it is found that there is an image MIME type of. MPO, and the pictures in my excel are clearly in. PNG format
examples are as follows:
>>> import PIL.Image
>>> img = PIL.Image.open('bob a.jpg')
>>> img.format
'MPO'
>>> PIL.PILLOW_VERSION
'2.7.0'
First of all, you should know that openpyxl uses pilot to identify images. After Google found that this PNG image is recognized as an. MPO file by pilot, Openpyxl does not support
while images in MPO format are very similar to JPEG images
it may be that an additional flag is added when the pilot recognition format is JPEG or PNG and marked as MPO
so we can add the above two lines of code before importing any image and before the pilot recognition image (I don’t know what he means. The jpeimageplugin is used by the pilot to process images. It should not add any suffix to the source image).
Reference link
using openpyxl: keyerror: ‘. MPO’ while saving excel workbook
k
JPEG image being identified as MPO