This article is from Huawei cloud community “your parquet should be upgraded: IOException: totalvaluecount = = 0 problem positioning Tour”, original author: wzhfy.
1. Problem description
When using spark SQL to perform ETL task, an error is reported when reading a table: “IOException: totalvaluecount = = 0”, but there is no exception when writing the table.
2. Preliminary analysis
The result of this table is generated after two tables join. After analysis, the result of join produces data skew, and the skew key is null. After join, each task writes a file, so the task whose partition key is null writes a large number of null values to a file, and the number of null values reaches 2.2 billion.
The figure of 2.2 billion is sensitive, just exceeding the maximum value of int 2147483647 (more than 2.1 billion). Therefore, it is suspected that parquet is writing more than int.max There’s a problem with a value.
[note] this paper only focuses on the problem that a large number of null values are written to the same file, resulting in an error when reading. As for whether it is reasonable to generate such a large number of nulls in this column, it is beyond the scope of this paper.
3. Deep dive into parquet (version 1.8.3, some contents may need to be understood in combination with parquet source code)
Entry: Spark (spark 2.3) – & gt; parquet
The parquet call entry is in spark, so the call stack is mined from spark.
InsertIntoHad oopFsRelationCommand.run ()/ SaveAsHiveFile.saveAsHiveFile () -> FileFormatWriter.write ()
There are several steps
- before starting a job, create an outputwriterfactory: ParquetFileFormat.prepareWrite ()。 A series of configuration information related to parquet writing files will be set here. The main one is to set the writesupport class ParquetOutputFormat.setWriteSupportClass (job, classof [parquetwritesupport]), parquetwritesupport is a class defined by spark itself. In executetask () – & gt; writeTask.execute In (), first create the outputwriter (parquetoutputwriter) through the outputwriterfactory: outputWriterFactory.newInstance ()。 For each row of records, use ParquetOutputWriter.write The (internalrow) method writes the parquet file in turn. Before the task ends, call ParquetOutputWriter.close () shut down resources.
3.1 write process

In parquetoutputwriter, through the ParquetOutputFormat.getRecordWriter Construct a recordwriter (parquet recordwriter), which includes:
Writesupport set when
- preparewrite(): responsible for converting spark record and writing to parquet structure parquetfilewriter: responsible for writing to file
In parquetrecordwriter, the write operation is actually delegated to an internalwriter (internal parquetrecordwriter, constructed with writesupport and parquetfilewriter).
Now let’s sort out the general process so far:
single directory writetask/dynam icPartitionWriteTask.execute
-> ParquetOutputWriter.write -> ParquetRecordWriter.write -> Interna lParquetRecordWriter.write
Next, interna lParquetRecordWriter.write There are three things in it

(1) writeSupport.write , i.e ParquetWriteSupport.write There are three steps
- MessageColumnIO.MessageColumnIORecordConsumer .startMessage; ParquetWriteSupport.writeFields : write the value of each column in a row, except null value; MessageColumnIO.MessageColumnIORecordConsumer . endmessage: write null value for missing fields in the second step.
Columnwriterv1. Writenull – & gt; accountforvaluewritten:
1) increase the counter valuecount (int type)
2) to check whether the space is full, writepage – checkpoint 1 is required
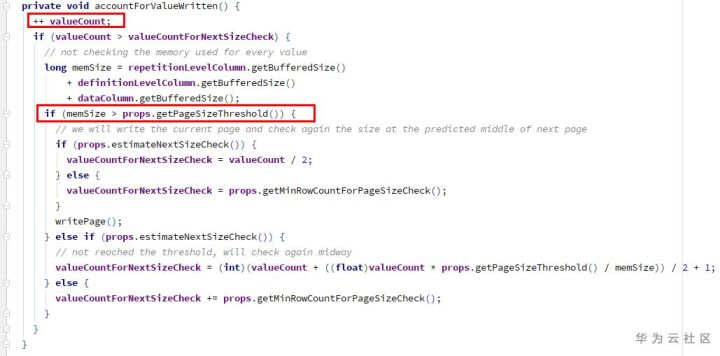
(2) Increase counter RecordCount (long type)
(3) Check the block size to see if flushrowgrouptostore – checkpoint 2 is required
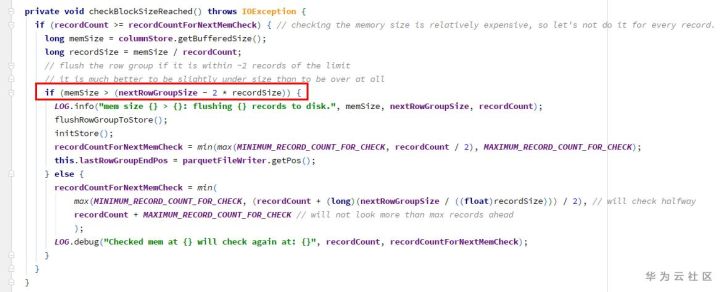
Since all the written values are null and the memsize of 1 and 2 checkpoints is 0, page and row group will not be refreshed. As a result, null values are always added to the same page. The counter valuecount of columnwriterv1 is of type int, when it exceeds int.max The overflow becomes a negative number.
Therefore, flushrowgrouptostore is executed only when the close() method is called (at the end of the task):
the ParquetOutputWriter.close -> ParquetRecordWriter.close
-> Interna lParquetRecordWriter.close -> flushRowGroupToStore
-> ColumnWriteStoreV1.flush -> for each column ColumnWriterV1.flush
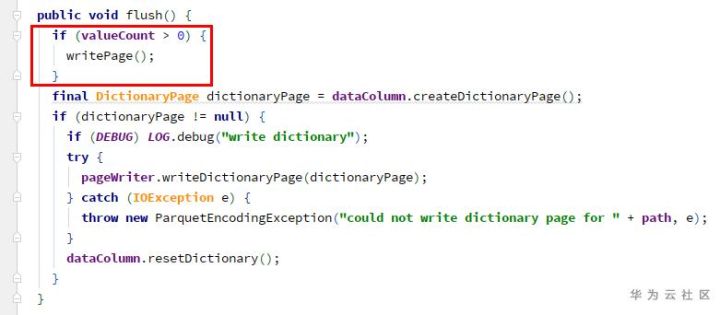
Page will not be written here because valuecount overflow is negative.
Because writepage has not been called, the totalvaluecount here is always 0.
ColumnWriterV1.writePage -> C olumnChunkPageWriter.writePage -&Value total
At the end of the write, interna lParquetRecordWriter.close -> flushRowGroupToStore -> Colum nChunkPageWriteStore.flushToFileWriter -> for each column C olumnChunkPageWriter.writeToFileWriter :
- ParquetFileWriter.startColumn : totalvaluecount is assigned to currentchunkvalueco untParquetFileWriter.writeDataPagesParquetFileWriter . endcolumn: currentchunk valuecount (0) and other metadata information construct a columnchunk metadata, and the relevant information will be written to the file eventually.
3.2 read process
Also, take spark as the entry to view.
Initialization phase: ParquetFileFormat.BuildReaderWithPartitionValues -> Vectorize dParquetRecordReader.initialize -> ParquetFileReader.readFooter -> Parq uetMetadataConverter.readParquetMetadata -> fromParquetMetadata -> ColumnChunkMetaData.get , which contains valuecount (0).
When reading: vectorize dParquetRecordReader.nextBatch -> checkEndOfRowGroup:
1) ParquetFileReader.readNextRowGroup -> for each chunk, currentRowGroup.addColumn ( chunk.descriptor.col , chunk.readAllPages ())
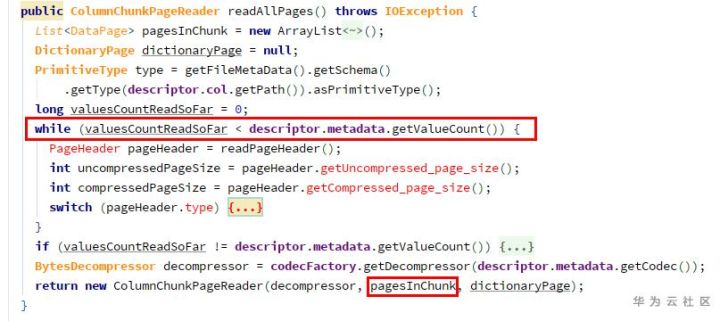
Since getvaluecount is 0, pagesinchunk is empty.
2) Construct columnchunkpagereader:
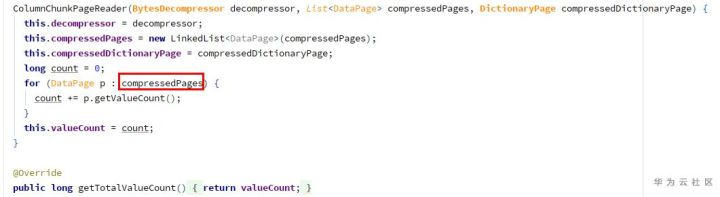
Because the page list is empty, the totalvaluecount is 0, resulting in an error in the construction of vectorizedcolumnreader.
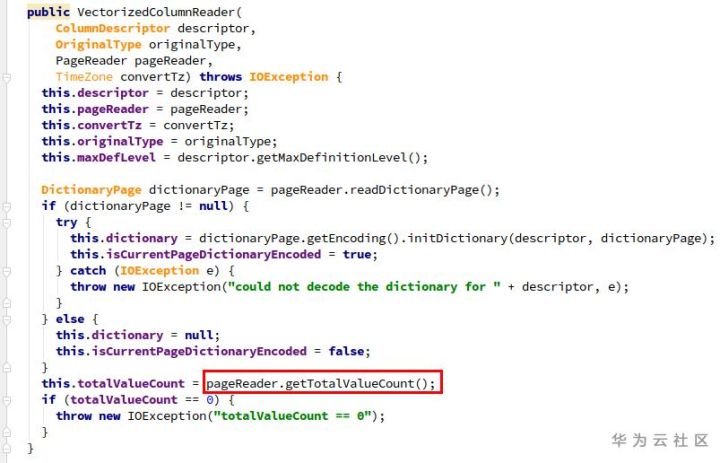
4. Solution: parquet upgrade (version 1.11.1)
In the new version, ParquetWriteSupport.write ->
MessageColumnIO.MessageColumnIORecordConsumer .endMessage ->
ColumnWriteStoreV1(ColumnWriteStoreBase).endRecord:
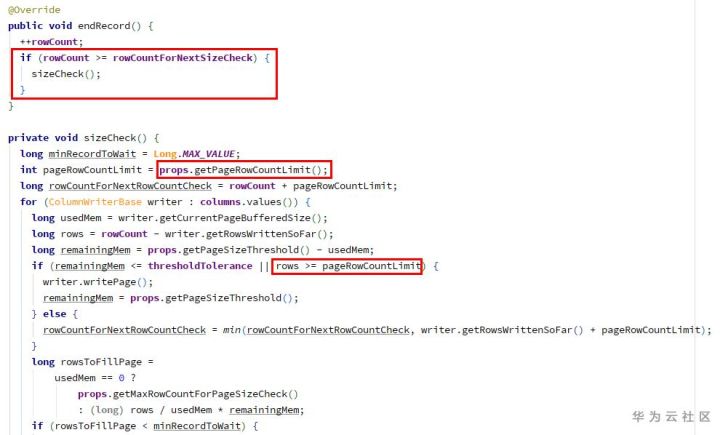
In endrecord, the attribute of maximum number of records per page (2W records by default) and the check logic are added. When the limit is exceeded, writepage will be generated, so that the valuecount of columnwriterv1 will not overflow (it will be cleared after each writepage).
Compared with the old version 1.8.3, columnwritestorev1.endrecord is empty.

Attachment: a small trick in parquet
In parquet, in order to save space, when a long type value is within a certain range, int will be used to store it. The method is as follows:
Determine whether it can be stored with int:

If you can, use intcolumnchunkmetadata instead of longcolumnchunkmetadata to convert on construction time:

When you use it, turn it back, in tColumnChunkMetaData.getValueCount -> intToPositiveLong():

The common int range is – 2 ^ 31 ~ (2 ^ 31 – 1). Because metadata information (such as valuecount) is a non negative integer, it can only store numbers in the 0 ~ (2 ^ 31 – 1) range. In this way, the number in the range of 0 ~ (2 ^ 32 – 1) can be expressed, and the expression range is doubled.
Attachment: test case code that can be used to reproduce (depending on some spark classes, it can be run in spark project)
Test case code.txt 1.88kb
Click follow to learn about Huawei’s new cloud technology for the first time~