foreword
After configuring the linux server environment, run the python script and find that the smtplib module reports an error, but not on windows, the error is as follows:
linux module 'smtplib' has no attribute 'SMTP_SSL'
configure
reason
Find the source code of smtplib.SMTP_SSL and find that the SMTP_SSL class is only established when have_ssl is True, and the have_ssl variable requires ssl dependency to be True, then the problem is found, there is no ssl dependency on linux
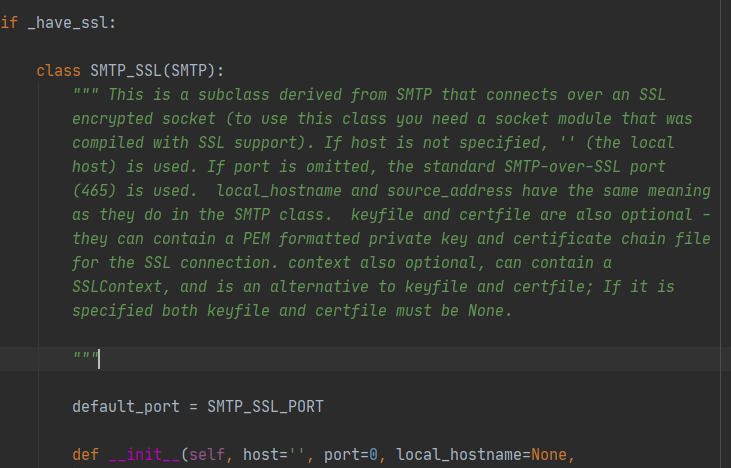
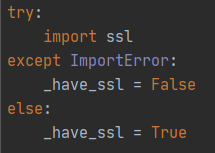
solution
yum install openssl openssl-devel
- Verify that the installation was successful, check the version
openssl version -a
- Enter your python3.7 directory, for example, my python-3.7.6.tgz file is decompressed and placed in the /usr/tgz/python/Python-3.7.6 directory, enter the Modules folder under the file, some versions is the Module file
cd /usr/tgz/python/Python-3.7.6
cd Modules
- Modify the Setup file, the changes are as follows, and uncomment the 5 lines of code at more than 200 lines
vim Setup
Press ESC, :wq, Enter and save and exit
- Return to the previous directory, that is, the python3.7 directory, and reinstall python
cd ..
make && make install
- Run the code, problem solved