Recently, I've been working on the application of Transformer to fine-grained images.
Solving the problem with the vit source code
KeyError: 'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/query\kernel is not a file in the archive'
This is a problem when merging paths with os.path.join
Solution.
1. In the modeling.py file
Add '/' to the following paths:
ATTENTION_Q = "MultiHeadDotProductAttention_1/query/"
ATTENTION_K = "MultiHeadDotProductAttention_1/key/"
ATTENTION_V = "MultiHeadDotProductAttention_1/value/"
ATTENTION_OUT = "MultiHeadDotProductAttention_1/out/"
FC_0 = "MlpBlock_3/Dense_0/"
FC_1 = "MlpBlock_3/Dense_1/"
ATTENTION_NORM = "LayerNorm_0/"
MLP_NORM = "LayerNorm_2/"
2. In the vit_modeling_resnet.py file
ResNetV2 class Add '/' after each 'block' and 'unit'
self.body = nn.Sequential(OrderedDict([
('block1/', nn.Sequential(OrderedDict(
[('unit1/', PreActBottleneck(cin=width, cout=width*4, cmid=width))] +
[(f'unit{i:d}/', PreActBottleneck(cin=width*4, cout=width*4, cmid=width)) for i in range(2, block_units[0] + 1)],
))),
('block2/', nn.Sequential(OrderedDict(
[('unit1/', PreActBottleneck(cin=width*4, cout=width*8, cmid=width*2, stride=2))] +
[(f'unit{i:d}/', PreActBottleneck(cin=width*8, cout=width*8, cmid=width*2)) for i in range(2, block_units[1] + 1)],
))),
('block3/', nn.Sequential(OrderedDict(
[('unit1/', PreActBottleneck(cin=width*8, cout=width*16, cmid=width*4, stride=2))] +
[(f'unit{i:d}/', PreActBottleneck(cin=width*16, cout=width*16, cmid=width*4)) for i in range(2, block_units[2] + 1)],
))),
]))
Category Archives: Python
[Solved] AttributeError: module ‘pandas‘ has no attribute ‘rolling_count‘
Problem Description:
For the problems encountered in automatic modeling today, we use iris data set to initialize the automl framework and pass in training data. The problem is that in the last line of fit, an error is reported: attributeerror: module ‘pandas’ has no attribute’ rolling_ At that time, I read the wrong version of pandas on the Internet. Then I reinstalled it on the Internet and found that it still couldn’t.
Use Microsoft’s flaml automated modeling framework to directly pip, Install flaml. Attach Code:
from flaml import AutoML
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
iris_data = pd.concat([pd.DataFrame(iris.data),pd.Series(iris.target)],axis=1)
iris_data.columns = ["_".join(feature.split(" ")[:2]) for feature in iris.feature_names]+["target"]
iris_data = iris_data[(iris_data.target==0) |(iris_data.target==1)]
flaml_automl = AutoML()
flaml_automl.fit(pd.DataFrame(iris_data.iloc[:,:-1]),iris_data.iloc[:,-1],time_budget=10,estimator_list=['lgbm','xgboost'])After the upgrade dask is finally executed (PIP install — upgrade dask), it can run normally. However, it is strange that the error message does not prompt dask related problems. Some bloggers on the Internet say that dask provides interfaces to pandas and numpy, which may be caused by the low version of the interface??
Finally, after upgrading dask, the problem is solved!
[Solved] Original error was: DLL load failed while importing _multiarray_umath
Error:
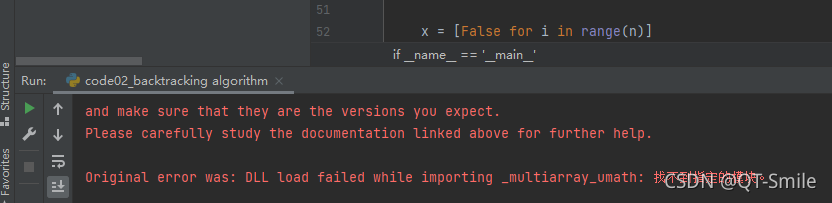
The solution:
Close pycharm and then open it again. It’s a perfect solution.
[Modified] AttributeError: ‘socket‘ object has no attribute ‘ioctl‘ python linux
For beginners of python, refer to the common codes on the Internet to set the heartbeat of TCP:
def __ init__ (self, IP=”127.0.0.1″, Port=5555):
“” “initialize object” “”
self.code_mode = “utf-8” # Transceiving data encoding/decoding format
self.IP = IP
self.Port = Port
self.my_socket =socket(AF_INET, SOCK_STREAM) # Create socket
self.my_socket.setsockopt(SOL_SOCKET,SO_KEEPALIVE,True)
self.my_socket.ioctl(SIO_KEEPALIVE_VALS,(1,10000,1000))
Run error:
AttributeError: ‘socket’ object has no attribute ‘ioctl’
It is found that there are no exceptions marked in VSC, and the rewritten code can be automatically supplemented, indicating that socket has this function. I checked that there is no relevant wrong information on the Internet, which may be due to my lack of TCP related common sense. This is confirmed by opening the socket.ioctl definition of Python. The definition is as follows:
if sys.platform == “win32”:
def ioctl(self, __control: int, __option: int | tuple[int, int, int] | bool) -> None: …
To sum up: I write code with vs in win7 and upload it to Linux for operation, while IOCTL is only valid in window.
Under Linux, it should be changed to
self.my_socket.setsockopt(SOL_SOCKET,SO_KEEPALIVE,True)
# self.my_socket.ioctl(SIO_KEEPALIVE_VALS,(1,10000,1000))
self.my_ socket.setsockopt(IPPROTO_TCP, TCP_KEEPIDLE, 10)
self.my_socket.setsockopt(IPPROTO_TCP, TCP_KEEPINTVL, 3)
self.my_socket.setsockopt(IPPROTO_TCP, TCP_KEEPCNT, 5)
[Solved] CONDA installs scikit-learn 0.24 Error: LinkError
Failed to update scikitlearn automatically when installing pytorch. Prompt error:
linkerror: post link script failed for package defaults:: scikit-learn-0.24.2-py36hf11a4ad_1

Solution:
Uninstall the original version of scikitlearn before installing it
[Solved] Nebula executes Algorithm Error: Error scanvertexresultiterator: get storage client error
The problem indicates that the storage client cannot be connected.
Solution:
Execute on the nebula console
show hosts;Since the default is 127.0.0.1, the storage client gets the storage address through the metad service when connecting to the nebula storage, so the storage address obtained in the spark connector is 127.0.0.1:9779, which is wrong.
Therefore, you can change the default address to the real address.
Django Error: binascii.Error: Incorrect padding [How to Solve]
The main reason is that Django is upgraded or downgraded;
Solution:
1. Delete database content
2、python manage.py makemigrations
3、python manage.py migrate
4、python manage.py createsuperuser
[Solved] Python Django error: error: (1146, “Table ‘mydb.django_session’ doesn’t exist”)
error: (1146, "Table 'mydb.django_session' doesn't exist")
Because there is no Django in the database table_session.
Execute the command at the terminal to migrate the data structure
$ python manage.py migrateAfter executing the above command, the output results are all OK. You can see that many tables have been added to the database table, The details are as follows
# By default 10 tables are automatically created in our database, as follows.
MariaDB [mydemo]> show tables;
+----------------------------+
| Tables_in_mydemo |
+----------------------------+
| auth_group |
| auth_group_permissions |
| auth_permission |
| auth_user |
| auth_user_groups |
| auth_user_user_permissions |
| django_admin_log |
| django_content_type |
| django_migrations |
| django_session |
| stu |
+----------------------------+
11 rows in set (0.00 sec)Then it was solved
[Solved] Python Project Import Module Error: ModuleNotFoundError
Question
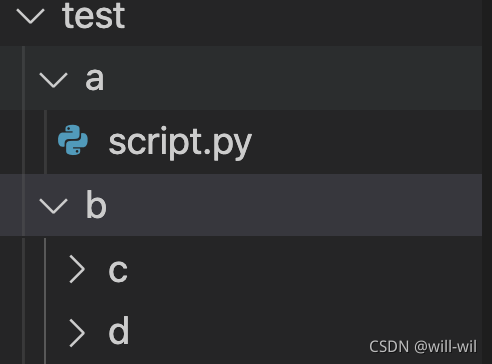
Importing a custom module in the project reports an error ModuleNotFoundError. The project directory structure is as follows. When in a.script.py from bc script.py, it prompts that the b module cannot be found, and the __init__.py file created in the b directory still reports an error.
Solution:
There are several methods of online search:
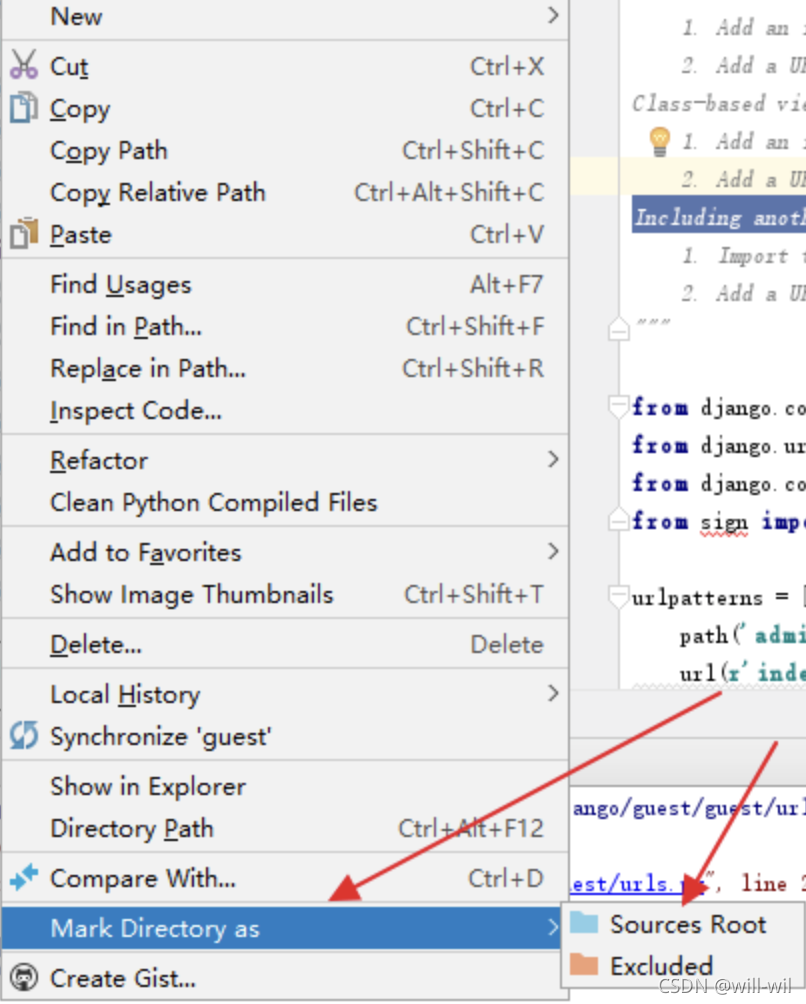
- If you use pycharm, you can right-click on the file directory location (not pycharm, visual inspection is useful)
2. import sys (Working)
sys.path.append(‘The address of the reference module’)
3. Create in the folder that needs to be imported __init.py__ (Not Working)
4. Direct export PYTHONPATH=path in linux (Working)
Summary
- If the imported module and the main program are in the same directory, import directly.
- If the imported module is in a subdirectory of the directory where the main program is located, you can add an __init__.py file to the subdirectory, which makes the python interpreter treat the directory as a package, and then you can directly “import the subdirectory. Module” “.
- If the imported module is in the parent directory of the directory where the main program is located, the above two are not feasible, and the path needs to be modified.
1.
The following method can be used, but it is a one-time thing.
import sys
sys.path.append('address of the referenced module')
File directory structure, need to be in the a.script.py filefrom b.c.1.py report error module not found
test
├── a
│ ├── _init_paths.py
│ └── script.py
└── b
├── c
│ └── 1.py
└── d
Suggested forms.
1. Write import sys sys.path.append('address of referenced module') directly at the beginning of the script.py file to add the path.
2. Create the _init_paths.py script in the a directory, and then just import _init_paths in script.py.
#_init_paths.py
import os
import sys
def add_path(path):
"""Add path to sys system path
"""
if path not in sys.path:
sys.path.append(path)
current_dir = os.path.dirname(__file__)
parent_dir = os.path.dirname(current_dir)
add_path(parent_dir)
2.Modify the environment variables directly, you can use export PYTHONPATH=path to add in linux.
[Solved] Python install kenlm error: ERROR: Command errored out with exit status 1: …
Use pip install kenlm error:
python/kenlm.cpp:6381:13: error: ‘PyThreadState {aka struct _ts}’ has no member named ‘exc_traceback’; did you mean ‘curexc_traceback’?
tstate->exc_traceback = *tb;
^~~~~~~~~~~~~
curexc_traceback
error: command ‘gcc’ failed with exit status 1
ERROR: Command errored out with exit status 1: …
It seems to be the GCC Issue
Solution:
Use pypi-kenlm
pip install pypi-kenlmIndexError: list index out of range [How to Solve]
IndexError: list index out of range
When training ctpn, some pictures report this error
the error code is as follows. Because the mean value is subtracted from three channels respectively when subtracting the mean value, some pictures are of two channels, and the length does not match, so an error is reported
solution: convert to RGB three channel diagram here
vggMeans = [122.7717, 102.9801, 115.9465]
imageList = cv2.split(image.astype(np.float32))
imageList[0] = imageList[0]-vggMeans[0]
imageList[1] = imageList[1]-vggMeans[1]
imageList[2] = imageList[2]-vggMeans[2]
image = cv2.merge(imageList)
[Solved] PyInstaller Error: ValueError: too many values to unpack
Execution: pyinstaller .\checkattendance.spec
report errors:
for name, pth in format_binaries_and_datas(datas, workingdir=spec_dir):
File "d:\python\winpython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\PyInstaller\building\utils.py", line 440, in format_binaries_and_datas
for src_root_path_or_glob, trg_root_dir in binaries_or_datas:
ValueError: too many values to unpackWhen reading an error, there should be a problem with the format of the data in the data or binaries. Think of adding content to the data field of the spec file, such as data = [“config.Ini”, ‘.’]
According to the information, the list of data is a list of tuples, and the tuple is a tuple of two elements. The first element is the position when reading the file in Python code, and the second element represents the real directory of the data file to be read.
So the format should be data = [(“config.Ini”, ‘.’)]

After modification, execute pyinstaller .\checkattendance.spec
It can be packed smoothly. I hope it can help you with the same problem~