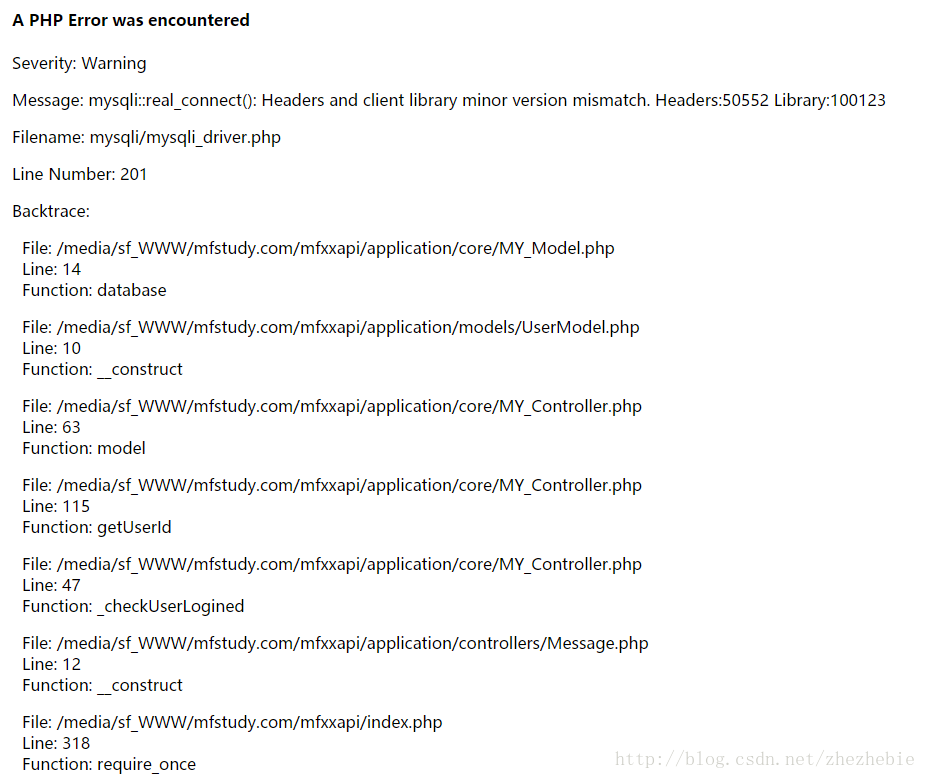
SQL92 and earlier versions do not allow the selection of lists,
HAVING condition or
ORDER BY list references unnamed non-grouped columns in the
GROUP BY clause. For example, in standard SQL92, this query is illegal because columns that are not listed in the
name selection list do not appear in the
GROUP BY :
SELECT o.custid, c.name, MAX(o.payment)FROM orders AS o, customers AS cWHERE o.custid = c.custidGROUP BY o.custid;
For the query in SQL92 to be valid, the name column must be omitted from the selection list or named in the GROUP BY clause.
SQL99 later allows for every optional function, T301, and so nonaggregates, if they are funcally dependent on GROUP BY column: if there is such a relationship between name, and custid, the query is legal. This is the case, for example, is custid the main key customers.
MySQL 5.7.5 or above function dependency detection function. If ONLY_FULL_GROUP_BY is enabled for SQL mode (BY default), MySQL rejects the list of options, HAVING conditions or the ORDER BY list references a subset that neither specifies the GROUP BY non-collection column, nor is it functionally dependent on them. (prior to 5.7.5, MySQL did not detect functional dependency, ONLY_FULL_GROUP_BY is not enabled by default). For a description of the behavior prior to 5.7.5, see the MySQL 5.6 Reference Manual.)
If ONLY_FULL_GROUP_BY is disabled, then the MySQL extension used BY standard SQL GROUP BY allows the selection of lists, HAVING conditions, or ORDER BY lists reference non-collection columns, even though the columns do not functionally depend on the GROUP BY columns. This causes MySQL to accept the previous query. In this case, the server is free to select any value in each group, so unless they are the same, the selected value is uncertain, which may not be what you want. In addition, the choice of the value for each group cannot be influenced BY adding a ORDER BY clause. The result set sorting occurs after the selected value, ORDER BY does not affect which value in each group the server selects. Disabling ONLY_FULL_GROUP_BY is useful primarily if you know that due to some attribute of the data each unnamed GROUP BY has the same value for each GROUP in each non-grouping column.
You can achieve the same effect without ONLY_FULL_GROUP_BY by referring to a non-grouped column using ANY_VALUE().
The following discussion illustrates functional dependencies, error messages when MySQL’s functions are not dependent, and the methods that cause MySQL to accept queries without functional dependencies.
This query may be ONLY_FULL_GROUP_BY is disabled because the column not listed in the address select list is not named in the GROUP BY clause:
SELECT name, address, MAX(age) FROM t GROUP BY name;
This query is valid if name is the primary key t or the only NOT NULL column. In this case, MySQL recognizes that the selected column is functionally dependent on the grouping column. For example, if name is the primary key, then the value is determined, address because each group has only one value of the primary key, so there is only one row. Therefore, there is no randomness in the selection of values in the address group, and there is no need to reject the query.
If name is NOT the primary key t or the only NOT NULL column, the query is invalid. In this case, functional relevance cannot be inferred and an error occurs:
mysql> SELECT name, address, MAX(age) FROM t GROUP BY name; ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUPBY clause and contains nonaggregated column 'mydb.t.address' whichis not functionally dependent on columns in GROUP BY clause; thisis incompatible with sql_mode=only_full_group_by
If you know, for a given data set, every name value actually uniquely identifies this address value, this address is functionally dependent name. To tell MySQL to accept a query, use the following ANY_VALUE() function:
SELECT name, ANY_VALUE(address), MAX(age) FROM t GROUP BY name;
Or, disable ONLY_FULL_GROUP_BY.
However, the above example is simple. In particular, you cannot group on a single primary key column because each group contains only one row. For additional examples of functional dependencies in more complex queries, see Section 12.19.4, “Functional dependency Detection.”
If the query has an aggregation function and no GROUP BY clause, it cannot have a non-collection column in the select list, HAVING condition, or the ORDER BY list ONLY_FULL_GROUP_BY :
mysql> SELECT name, MAX(age) FROM t; ERROR 1140 (42000): In aggregated query without GROUP BY, expression#1 of SELECT list contains nonaggregated column 'mydb.t.name'; thisis incompatible with sql_mode=only_full_group_by
There is no GROUP BY, there is a separate GROUP, and it is uncertain which name value is selected for the GROUP. Here also ANY_VALUE() can be used, if it is irrelevant, nameMySQL selects which value:
SELECT ANY_VALUE(name), MAX(age) FROM t;
ONLY_FULL_GROUP_BY also affects the handling of ORDER BY using a DISTINCT and queries in MySQL 5.7.5 or later. In the case of the table, t has three columns c1, c2 and c3 contain these rows:
c1 c2 c3
1 2 A
3 4 B
1 2 C
Suppose we execute the following query and expect the results to be sorted in the following order c3 :
SELECT DISTINCT c1, c2 FROM t ORDER BY c3;
To order results, you must first repeat. But to do that, should we keep the first row or the third row?This arbitrary choice affects the reserved value c3, which in turn affects the sorting and makes it arbitrary. To prevent this problem, if any expression does not meet at least one of the following criteria, the query with DISTINCT and ORDER BY is rejected is invalid ORDER BY :
The expression equals that all columns of the selected table referenced by an expression in the selection list and belonging to the query are elements of the selection list
Another MySQL extension of standard SQL allows alias expressions to be referenced in the HAVING clause in the select list. For example, the following query returns name values that occur only once in the table orders :
SELECT name, COUNT(name) FROM ordersGROUP BY nameHAVING COUNT(name) = 1;
MySQL extension allows HAVING to use aliases in clauses of aggregated columns:
SELECT name, COUNT(name) AS c FROM ordersGROUP BY nameHAVING c = 1;
Pay attention to
Prior to MySQL 5.7.5, enabling ONLY_FULL_GROUP_BY disables this extension, so you need HAVING to write this clause using an unused expression.
Standard SQL only allows column expressions in the GROUP BY clause, so such a statement is invalid because it FLOOR(value/100) is a non-column expression:
SELECT id, FLOOR(value/100)FROM tbl_nameGROUP BY id, FLOOR(value/100);
MySQL extends standard SQL to allow non-column expressions in the GROUP BY clause and treats the above statement as valid.
Standard SQL also does not allow aliases in the GROUP BY clause. MySQL extends standard SQL to allow aliases, so another way to write queries is as follows:
SELECT id, FLOOR(value/100) AS valFROM tbl_nameGROUP BY id, val;
The alias val in this clause is treated as the column expression GROUP BY.
When a non-column expression exists in the GROUP BY clause, MySQL recognizes the equality between that expression and the expression in the selection list. This means that when ONLY_FULL_GROUP_BY is enabled for the QL schema, the contained query GROUP BY id, FLOOR(value/100) is valid, because FLOOR() appears in the selection list with the same expression. MySQL, however, does not attempt to identify functional dependencies on non-GROUP BY column expression, so ONLY_FULL_GROUP_BY, even though the third selected expression is a simple formula for id column and FLOOR() expression in the clause, the following query is invalid GROUP BY :
SELECT id, FLOOR(value/100), id+FLOOR(value/100)FROM tbl_nameGROUP BY id, FLOOR(value/100);
The solution is to use derived tables:
SELECT id, F, id+FFROM0 (SELECT id, FLOOR(value/100) AS F1 3 4 FROM tbl_name5 6 7 8 GROUP BY id, FLOOR(value/100)) AS dt;9 0
1