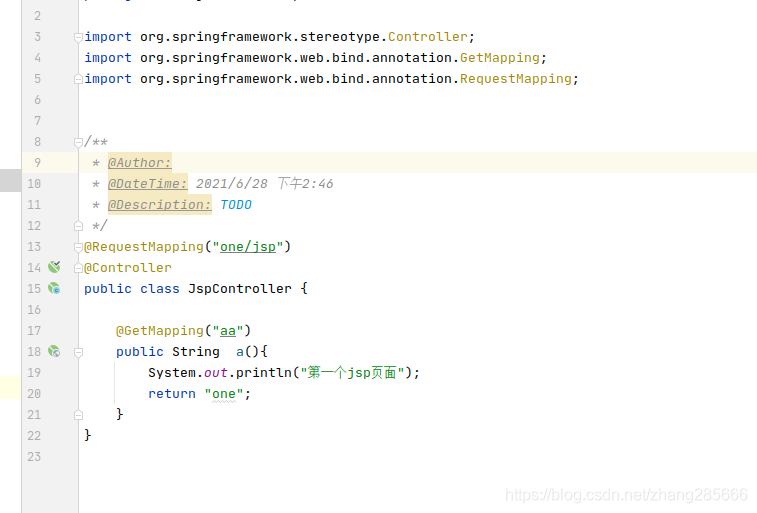
The error log information is as follows:
1 Unable to handle kernel NULL pointer dereference at virtual address 00000014
2 pgd = c0004000
3 [00000014] *pgd=00000000
4 Internal error: Oops: 5 [#1] PREEMPT SMP ARM
5 Modules linked in:
6 CPU: 0 PID: 1 Comm: swapper/0 Not tainted 3.10.45 #125
7 task: dc078000 ti: dc05a000 task.ti: dc05a000
8 PC is at at24c02_probe+0x78/0xa0
9 LR is at wake_up_klogd+0x84/0xac
10 pc : [<c03e27c0>] lr : [<c002d9b0>] psr: 40000113
11 sp : dc05bdb8 ip : dc05bcc0 fp : dc05bdd4
12 r10: c0a20a80 r9 : 0000009e r8 : c03e2748
13 r7 : 00000000 r6 : c08ccee4 r5 : c08ccf00 r4 : c075dbbc
14 r3 : 00000000 r2 : 00000001 r1 : 20000193 r0 : 00000020
15 Flags: nZcv IRQs on FIQs on Mode SVC_32 ISA ARM Segment kernel
16 Control: 10c5387d Table: 1000404a DAC: 00000015
17 Process swapper/0 (pid: 1, stack limit = 0xdc05a238)
1) According to the log information, the value of PC is PC is at at24c02_ probe+0x78/0xa0;
at24c02_ Probe: the function indicating the error;
0x78: indicates the offset position of the Error statement in the error function;
0xa0: AT24C02_ The size of probe function
2) Use arm none Linux gnueabi GCC nm command to find the function AT24C02_ The linear address of probe in the kernel (you can also find it in the system. Map file)
arm-none-linux-gnueabi-gcc-nm vmlinux | grep at24c02_ probe
(vmlinux is an uncompressed image file, which is in the compilation folder of the kernel.)
The results are as follows
1 c03e2748 t at24c02_probe
Description AT24C02_ The initial linear address of probe function in kernel is 0xc03e2748;
3) According to the deviation value of 0x78, using the arm none Linux gnueabi objdump command, the disassembly of address c03e2748-c03e27ff is displayed (estimated approximate range)
arm-none-linux-gnueabi-objdump -S vmlinux –start-address=0xc03e2748 –stop-address=0xc03e27ff >/tmp/file
Deviation value + starting address of function = 0x78 + 0xc03e2748 = 0xc03e27c0 (it can also be obtained from PC value of log)
The errors found in the file file are as follows:
1 c03e27b8: e59f0020 ldr r0, [pc, #32] ; c03e27e0 <at24c02_probe+0x98>
2 56 c03e27bc: eb0c86de bl c070433c <printk>
3 57 printk("The i2c device id data is %d\n", id->driver_data);
4 58 c03e27c0: e5971014 ldr r1, [r7, #20]
5 59 c03e27c4: e59f0018 ldr r0, [pc, #24] ; c03e27e4 <at24c02_probe+0x9c>
6 60 c03e27c8: eb0c86db bl c070433c <printk>
We can see that the wrong statement is: printk (“the I2C device ID data is% D/N”, ID – & gt; driver_ data);
Another method:
You can directly obtain the following information through the addr2line command:
Execute the following command under the compiled source code folder to show which line of code of that function has problems,
arm-none-linux-gnueabi-addr2line -e vmlinux c03e27c0
/opt/Sourcery_CodeBench_for_ARM_Embedded/bin/arm-none-linux-gnueabi-addr2line -e vmlinux c03e27c0
Note: please make sure that cross_ Compile is compiled with the same prefix as you, such as arm none Linux gnueabi – above. You must compile with this prefix, otherwise the calculated line number may deviate greatly.