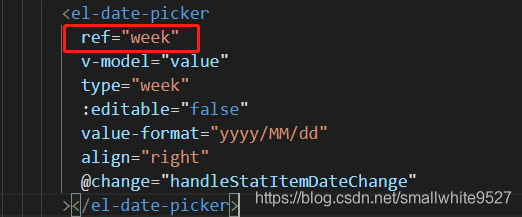
. This.$refs[‘ week ‘]. Close when pickerVisible is false
Author Archives: Robins
Microsoft edge was unable to log in. Error code: 3,15, – 2147023579
PS: I tried a lot of methods on the Internet are not good, I found that this can be solved, so I hope to help more people
If you use Win10 to download the new version of Edge browser, landing account found that can not login, may be the computer did not set Microsoft account.
My operation is:
Open the old version of Edge browser – Settings – Account and click on it. It will jump to the system’s Add Account interface and enter your Microsoft account to log in.
Then I looked at the old version of Edge and found that it had already logged in and synced automatically.
At this point, open the new version of Edge browser and click Login. Select Microsoft Account. A pop-up interface will automatically fill in the account you just logged in.
Point next step, enter password again, discover won’t report wrong, can land normally.
Conclusion: This error may be caused by the failure to check the local Microsoft account and the failure to automatically complete the account.
If you use Win10 to download the new version of Edge browser, landing account found that can not login, may be the computer did not set Microsoft account.
My operation is:
Open the old version of Edge browser – Settings – Account and click on it. It will jump to the system’s Add Account interface and enter your Microsoft account to log in.
Then I looked at the old version of Edge and found that it had already logged in and synced automatically.
At this point, open the new version of Edge browser and click Login. Select Microsoft Account. A pop-up interface will automatically fill in the account you just logged in.
Point next step, enter password again, discover won’t report wrong, can land normally.
Conclusion: This error may be caused by the failure to check the local Microsoft account and the failure to automatically complete the account.
Ubuntu starts Xilinx vivado
1, if you are the current user is
3, the end of the file with source/opt/Xilinx/Vivado/2016.4/settings64. Sh
4. If not, start the file source.bashrc
hadoop , enter the directory is /home/hadoop
/ code> 3, the end of the file with source/opt/Xilinx/Vivado/2016.4/settings64. Sh
4. If not, start the file source.bashrc
Install in Python 3. X web.py
Install web.py in Python 3.x
Recently decided to move from Python 2.7 to work on 3.x.
using the database, still chose before more interested in web. Py
but seemed to have all sorts of problems found when installation.
ImporError: No module named ‘utils’
ModuleNotFoundError: No module named ‘db’
I finally decided to give the dev version a try.
pip install web.py==0.40.dev0It turns out that the dev version of web.py works perfectly on Python 3.x.
I personally tested Python 3.6
The code is as follows:
import pymysql
pymysql.install_as_MySQLdb()
import web
db = web.database(dbn='mysql', host='db_host', port=3306,
user='root', pw='password', db='db_name', charset='utf8')
results = db.query('select * from user where id = 1;')
for user in results:
print(user.name)
print(user.id_no)Hopefully this article will help those of you who are looking for web.py available on Python 3.x.
Group by operator of hive execution plan
Group By Operator</code bbb>oup aggregate, common attribute
aggregations、grouping is for which aggregation function
mode, generally hash, computes the hash of keys
keys When there is no keys attribute, there is only one grouping.
outputColumnNames Temporary column names for output
For example
explain select sum(sal) from tb_emp;
Look at its Group By Operator
+---------------------------------------------------------------------------------------------+
|Explain |
+---------------------------------------------------------------------------------------------+
| Group By Operator |
| aggregations: sum(sal) |
| mode: hash |
| outputColumnNames: _col0 |
| Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE|
+---------------------------------------------------------------------------------------------+
Again for instance
explain select deptno,sum(sal) from tb_emp group by deptno;
Look at its Group By Operator</code bbb>
+------------------------------------------------------------------------------------------------+
|Explain |
+------------------------------------------------------------------------------------------------+
| Group By Operator |
| aggregations: sum(sal) |
| keys: deptno (type: int) |
| mode: hash |
| outputColumnNames: _col0, _col1 |
| Statistics: Num rows: 89 Data size: 718 Basic stats: COMPLETE Column stats: NONE|
+------------------------------------------------------------------------------------------------+
The group by implementation principle
The process of transforming a GROUP BY task into a MR task is as follows:
Map: Generate key-value pairs, using the column in the GROUP BY condition as the Key and the result of the aggregation function as the Value
Shuffle: Hash according to the value of the Key, and send the key-value pairs to different Reducers according to the Hash value
Reduce: Reduce based on the columns of the SELECT clause and the aggregation function
conclusion
Group By Operator</code bbb>s four attributes. g> By Operator can als>ve Group By oper> . Group by>rator
reference
Group by Execution Plan Analysis (Hive
Springdatajpa @query with like @param
Direct to the code
//Using :name this way must be added, cut @Param is org.springframework.data.repository.query.Param package below the note
@Query(nativeQuery = true, value = "select a.id,a.name,a.code,a.age,b.age as sub_age from dog a inner join dog b on a.age = b.age where a.name like concat('%',:name ,'%')")
List<Dog> findAllByAgeAfter2(@Param("name") String name);
//The use of ?1 does not require the addition of @Param, and the addition of @Param does not affect
@Query(nativeQuery = true, value = "select a.id,a.name,a.code,a.age,b.age as sub_age from dog a inner join dog b on a.age = b.age where a.name like CONCAT('%',?1,'%')")
List<Dog> findAllByAgeAfter(String name);The test is as follows:

I hope I can help you, thank you!
How to Fix the common Warning Errors after Vue Project Startup
There are multiple modules with names that only differ in casing.This can lead to unexpected........

cause: Inconsistent file name and reference, one uppercase letter, one lowercase letter. For example, the file name is app.js, but when you referenced it, you wrote app.js
. ‘@/API/oa/workingHours aWorkinghoursAllowed/index’; I have written the file name AworkingChina Allowed as AworkingChina Allowed, which is why the above warning appears
52:12-24 Critical dependency: the request of a dependency is an expression

the reason: not in the main. Js file directly defining methods and instance of the prototype and note the red box part is problem solving
just began to found the problem and made for a long time have no problem, also a lot of related articles, baidu is not yet finally settled gave up, first put the
there behind the project are not busy, just use the most stupid way all commented out the code at the beginning, then one line to the test, the result unexpectedly directly to find the problems in one fell swoop
Image not found Return status code 404 (Not Found)
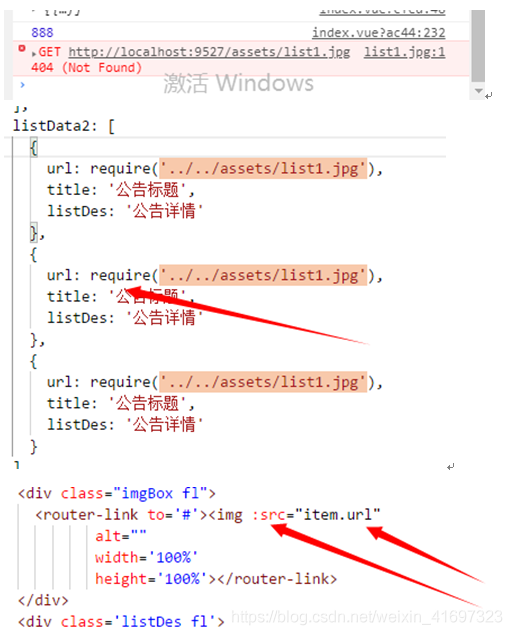
1- Write the URL in the data :require(‘./assets/images/logo.png ‘)
2- Write in the template
Request processing failed; nested exception is tk.mybatis.mapper.MapperException: The current entity class does not contain a property named rnable!

cause: front-background field names do not match
Error: listen EADDRNOTAVAIL 192.168.1.166:9527
at Object.exports._errnoException (util.js:1020:11)
at exports._exceptionWithHostPort (util.js:1043:20)
at Server._listen2 (net.js:1245:19)
at listen (net.js:1294:10)
at net.js:1404:9
at _combinedTickCallback (internal/process/next_tick.js:83:11)
at process._tickCallback (internal/process/next_tick.js:104:9)
at Module.runMain (module.js:606:11)
at run (bootstrap_node.js:389:7)
at startup (bootstrap_node.js:149:9)
at bootstrap_node.js:504:3
Reason: The server IP address has been changed
Error occured while trying to proxy to: localhost:9527/api//auth/jwt/token and returns the status code 500
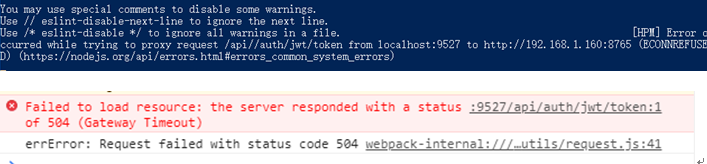
Cause: The background server is not on or down
How to Skip testing when Maven is packaged
Development record
I have a Maven project and I will clone the latest code. The Maven Package is about to be packaged, but an error is reported during the TEST phase. Confused, I decided to skip testing to package and deploy.
Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.12.4:test
Skip Test when running MVN Install or MVN Package
Method 1: Modify the pOM.xml file
<project>
[...]
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
</build>
[...]
</project>
Method 2: Execute the command in Terminal
mvn install -DskipTests
Method 3: Execute the command in Terminal
mvn install -Dmaven.test.skip=true
Method 4: Use the Spring Boot project
The spring-boot-maven-plugin is already integrated with the maven-surefire-plugin, which automatically runs JUnit test
. You just need to add the following configuration to your pom.xml:
<properties>
<!-- Skip Test -->
<skipTests>true</skipTests>
</properties>
Higher order components in react
High-order components (Hoc) is an advanced technique used to reuse component logic in React. Hoc itself is not part of the React API, but rather a design pattern based on React’s combinatorial features.
In particular, a higher-order component is a function that takes an argument to a component and returns a value to the new component.
Components convert props to UI, and higher-order components convert components to another component.
const EnhancedComponent = higherOrderComponent(WrappedComponent);
pytorch RuntimeError: Error(s) in loading state_ Dict for dataparall… Import model error solution
When importing model files in pytorch, the following error is reported.

RuntimeError: Error(s) in loading state_dict for DataParallel:
Unexpected running stats buffer(s) “module.norm1.norm_func.running_mean” and “module.norm1.norm_func.running_var” for InstanceNorm2d with track_running_stats=False. If state_dict is a checkpoint saved before 0.4.0, this may be expected because InstanceNorm2d does not track running stats by default since 0.4.0. Please remove these keys from state_dict. If the running stats are actually needed, instead set track_running_stats=True in InstanceNorm2d to enable them. See the documentation of InstanceNorm2d for details.
…
Unexpected running stats buffer(s) “module.res5.norm1.norm_func.running_mean” and “module.res5.norm1.norm_func.running_var” for InstanceNorm2d with track_running_stats=False. If state_dict is a checkpoint saved before 0.4.0, this may be expected because InstanceNorm2d does not track running stats by default since 0.4.0. Please remove these keys from state_dict. If the running stats are actually needed, instead set track_running_stats=True in InstanceNorm2d to enable them. See the documentation of InstanceNorm2d for details.
…
Process finished with exit code 0
According to the hint, the imported model was generated with pytorch 0.4.0, but now we are using pytorch 1.0, so we checked the load_state_dict function in the module.

I guess the keyword has changed with the version.
The solution is.
Change the above statement to
RuntimeError: Error(s) in loading state_dict for DataParallel:
Unexpected running stats buffer(s) “module.norm1.norm_func.running_mean” and “module.norm1.norm_func.running_var” for InstanceNorm2d with track_running_stats=False. If state_dict is a checkpoint saved before 0.4.0, this may be expected because InstanceNorm2d does not track running stats by default since 0.4.0. Please remove these keys from state_dict. If the running stats are actually needed, instead set track_running_stats=True in InstanceNorm2d to enable them. See the documentation of InstanceNorm2d for details.
…
Unexpected running stats buffer(s) “module.res5.norm1.norm_func.running_mean” and “module.res5.norm1.norm_func.running_var” for InstanceNorm2d with track_running_stats=False. If state_dict is a checkpoint saved before 0.4.0, this may be expected because InstanceNorm2d does not track running stats by default since 0.4.0. Please remove these keys from state_dict. If the running stats are actually needed, instead set track_running_stats=True in InstanceNorm2d to enable them. See the documentation of InstanceNorm2d for details.
…
Process finished with exit code 0
According to the hint, the imported model was generated with pytorch 0.4.0, but now we are using pytorch 1.0, so we checked the load_state_dict function in the module.
I guess the keyword has changed with the version.
The solution is.
Change the above statement to
model_dict = torch.load(args.test_weight_path)
model_dict_clone = model_dict.copy()
for key, value in model_dict_clone.items():
if key.endswith(('running_mean', 'running_var')):
del model_dict[key]
Gnet.load_state_dict(model_dict,False)Android 4.1:Entry name ‘classes.dex‘ collided
The previous compilation of the APK results in either deleting all APKs in the app/build and app/release directories, or deleting all files in both directories and then compiling the APK.
RuntimeError: ONNX export failed: Couldn‘t export operator aten::upsample_bilinear2d
pth –> Onnx error
RuntimeError: ONNX export failed: Couldn't export operator aten::upsample_bilinear2d
Solution:
torch.onnx.export(model, input, onnx_path, verbose=True, input_names=input_names, output_names=output_names)
#add:opset_version=11
torch.onnx.export(model, input, onnx_path, verbose=True, input_names=input_names, output_names=output_names, opset_version=11)