When reviewing Java Web, I want to make my workspace cleaner, so I cleaned up the web projects left in the Tomcat installation directory webapps, and double-click start Bat file, the CMD window flashes by, and I feel strange at once. This situation is usually JAVA_Home environment variable is not configured correctly.
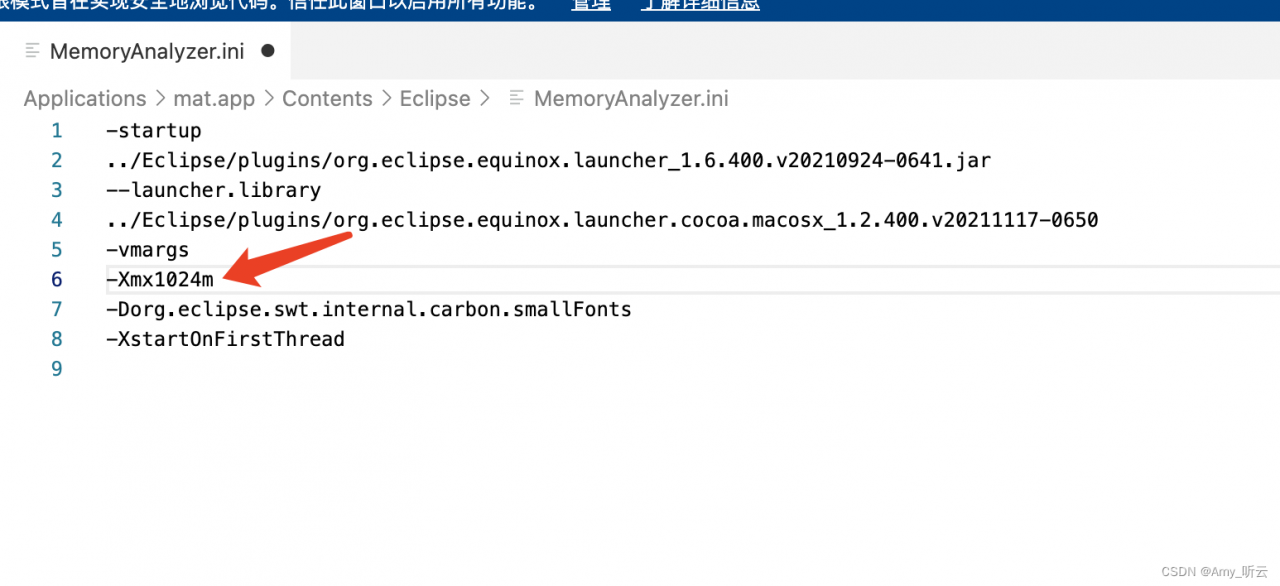
Then open start.bat in text mode, add “pause” after the end statement at the end, and double-click start.bat again after saving, the following results appear:
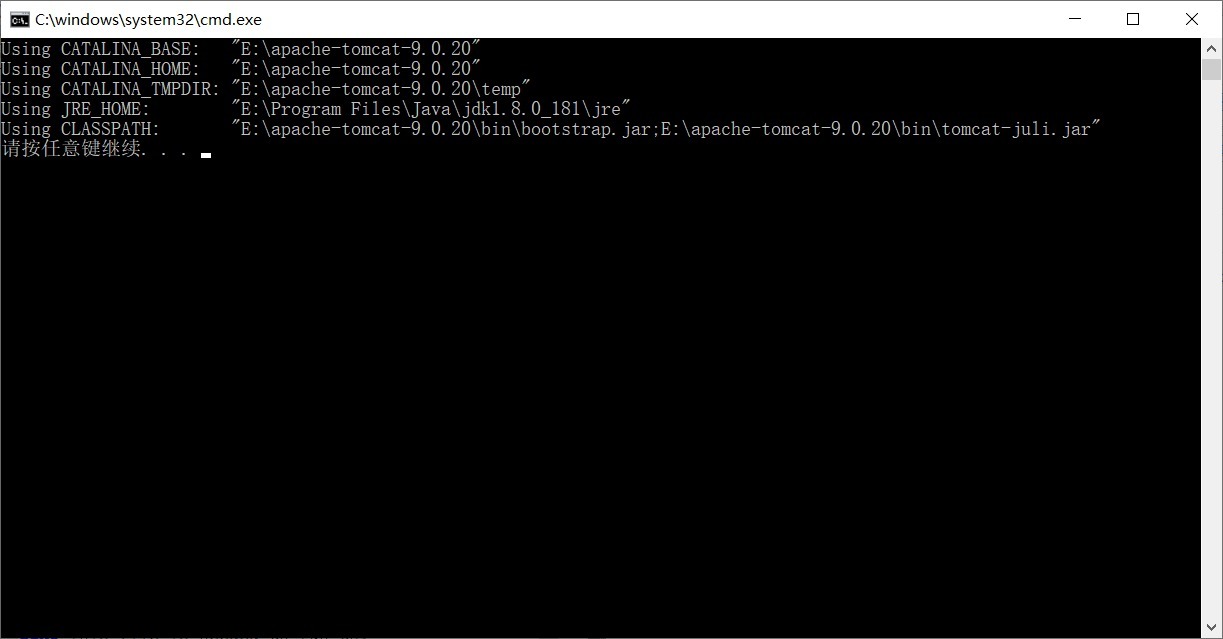
It is found that the paths are correct, indicating that there is no problem with my environment variable configuration.
Open start.bat again as text, call call "%EXECUTABLE%" start %CMD_LINE_ARGS% statement is changed to run. After saving, double-click start.bat, the following message appears:
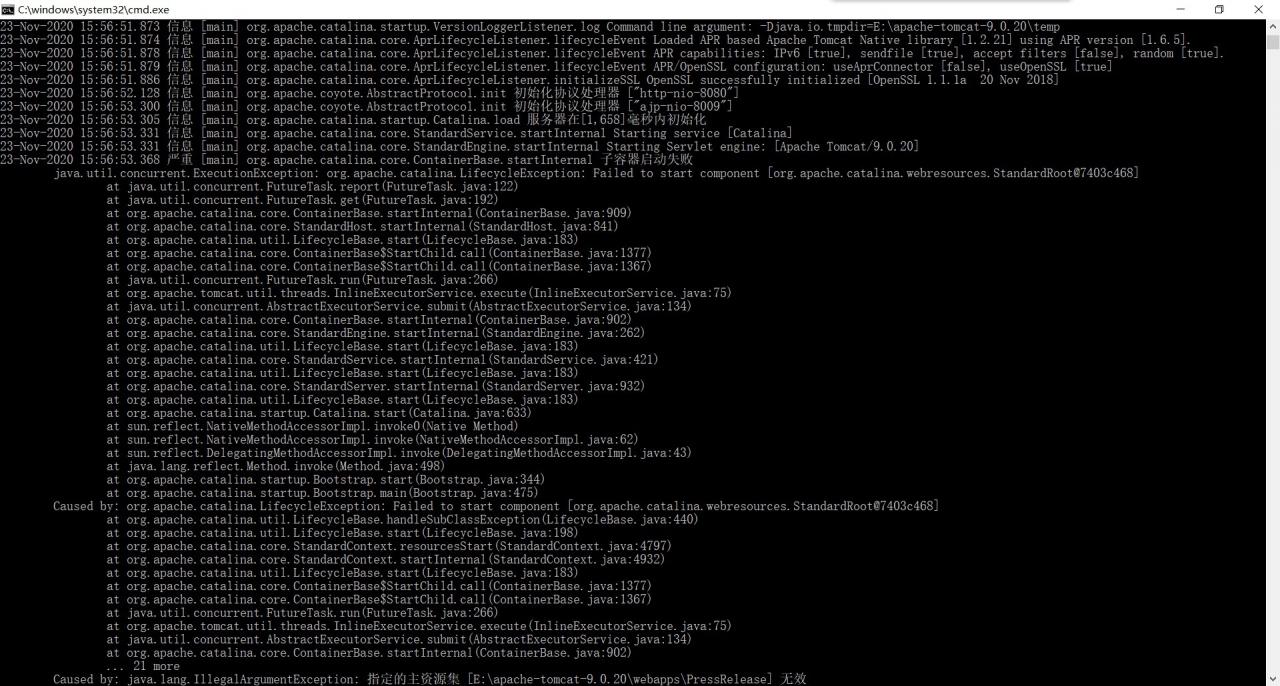
A series of errors are shown later, and I only cut one illustratively.
The main information observed is that the sub-container failed to start, and a specified resource set is invalid. The service component necessary Catalina.start fails to start; When you look carefully, you find that it shows an invalid resource set path (at the end of the figure above). You can see that there is no relevant folder under this path.
So I looked at the server.xml file in the conf directory and saw the following configuration (only the code was intercepted):
<Service name="Catalina">
<Engine defaultHost="localhost" name="Catalina">
<Host appBase="webapps" autoDeploy="true" name="localhost" unpackWARs="true">
<Context docBase="E:apache-tomcat-9.0.20webappsSSM" path="/SSM" reloadable="true" source="org.eclipse.jst.jee.server:SSM"/>
<Context docBase="E:apache-tomcat-9.0.20webappsSpring" path="/Spring" reloadable="true" source="org.eclipse.jst.jee.server:Spring"/>
<Context docBase="E:apache-tomcat-9.0.20webappsPressRelease" path="/PressRelease" reloadable="true" source="org.eclipse.jst.jee.server:PressRelease"/>
</Host>
</Engine>
</Service>
In the Context tag, docBase specifies the path of the project, which is accessed through the virtual path path. Because I deleted these three folders together when cleaning the project before, there was an error when Tomcat started.
Delete the contents of the three Context tags in the server.xml file, double-click start.bat after saving, and find that Tomcat has started normally and can access port 8080;
Or create the corresponding SSM, Spring, and PressRelease folders in the webapps directory, and Tomcat can also be started normally.