1, background
there was a problem after my tensorflow version was updated recently, and the error was also very vague: DLL load failed: the specified module could not be found. Let me start with my context:
win10 + pycharm
anaconda3 (python3.6)
tensorflow1.9
ii. Problem description
used its own version of tensorflow, which was 1.9, for almost a year and never had any problems. Later, I saw that the version of TensorFlow was updated to 1.12, so I thought I would update it. However, after the update, the error of importing tensorFlow was reported. After that, even lowering the tensorflow version to 1.2 still gives an error:
when import tensorflow, there will be an error message:
D:\python\anaconda\python.exe D:*****.py
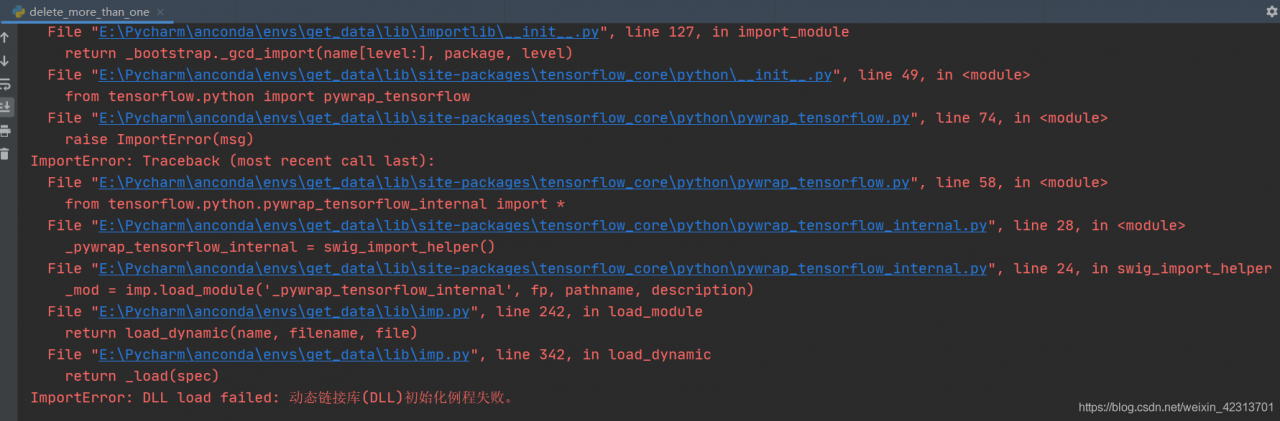
Traceback (most recent call last):
File "D:\python\anaconda\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 58, in <module>
from tensorflow.python.pywrap_tensorflow_internal import *
File "D:\python\anaconda\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 28, in <module>
_pywrap_tensorflow_internal = swig_import_helper()
File "D:\python\anaconda\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
File "D:\python\anaconda\lib\imp.py", line 243, in load_module
return load_dynamic(name, filename, file)
File "D:\python\anaconda\lib\imp.py", line 343, in load_dynamic
return _load(spec)
ImportError: DLL load failed: 找不到指定的模块。
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:/python/item/64-MARTAGAN/train_marta_gan.py", line 7, in <module>
import tensorflow as tf
File "D:\python\anaconda\lib\site-packages\tensorflow\__init__.py", line 24, in <module>
from tensorflow.python import pywrap_tensorflow # pylint: disable=unused-import
File "D:\python\anaconda\lib\site-packages\tensorflow\python\__init__.py", line 49, in <module>
from tensorflow.python import pywrap_tensorflow
File "D:\python\anaconda\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 74, in <module>
raise ImportError(msg)
ImportError: Traceback (most recent call last):
File "D:\python\anaconda\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 58, in <module>
from tensorflow.python.pywrap_tensorflow_internal import *
File "D:\python\anaconda\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 28, in <module>
_pywrap_tensorflow_internal = swig_import_helper()
File "D:\python\anaconda\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
File "D:\python\anaconda\lib\imp.py", line 243, in load_module
return load_dynamic(name, filename, file)
File "D:\python\anaconda\lib\imp.py", line 343, in load_dynamic
return _load(spec)
ImportError: DLL load failed: 找不到指定的模块。
Failed to load the native TensorFlow runtime.
See https://www.tensorflow.org/install/errors
for some common reasons and solutions. Include the entire stack trace
above this error message when asking for help.
Process finished with exit code 1
my error message is: DLL load failed: the specified module cannot be found; Specified Module Could not be Found DLL Load Failed: The Specified Module could not be found
. Solution
this is new, the current solution is less online, after a search, finally found a similar problem and I post on making the first link: https://github.com/tensorflow/tensorflow/issues/25597, are described in detail below.
attachment situation is similar to mine, give the attachment environment first:
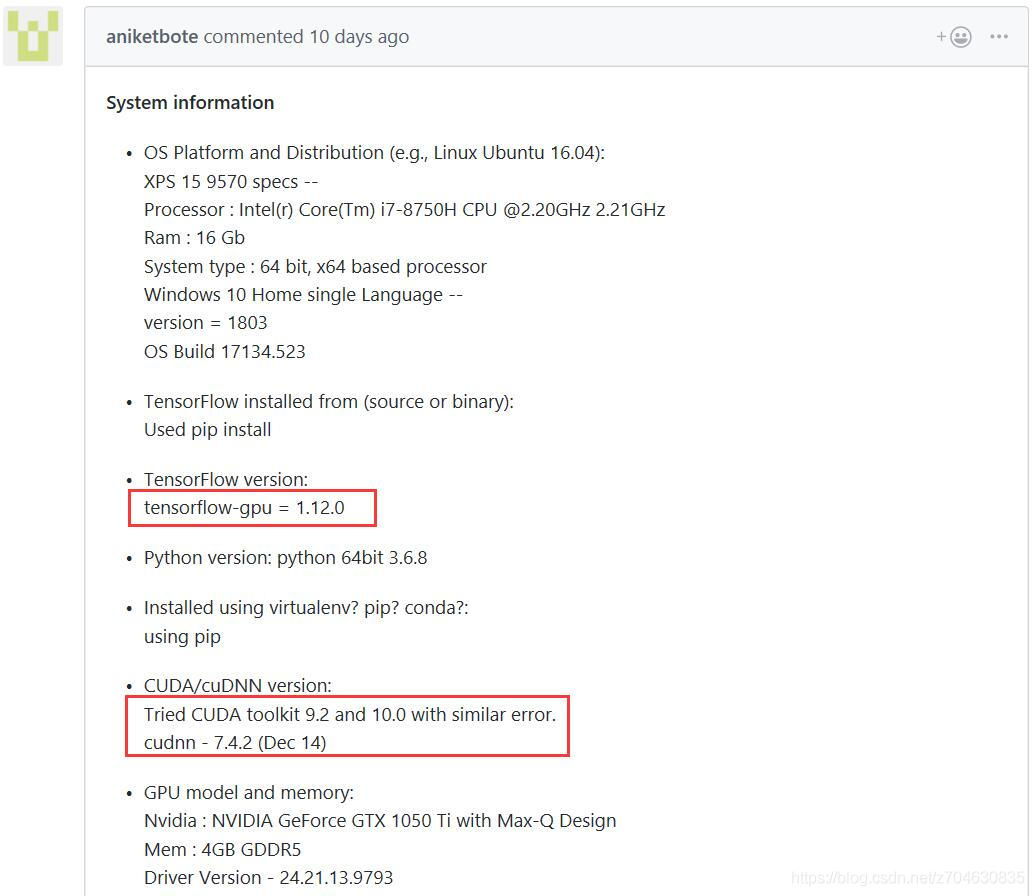
you can see that the sponsor also updated the tensorflow version to 1.12 before it encountered this problem. The following is a detailed description of how to configure your environment, and mentions that this error still occurs with CUDA9.2 and CUDA10.0 versions.
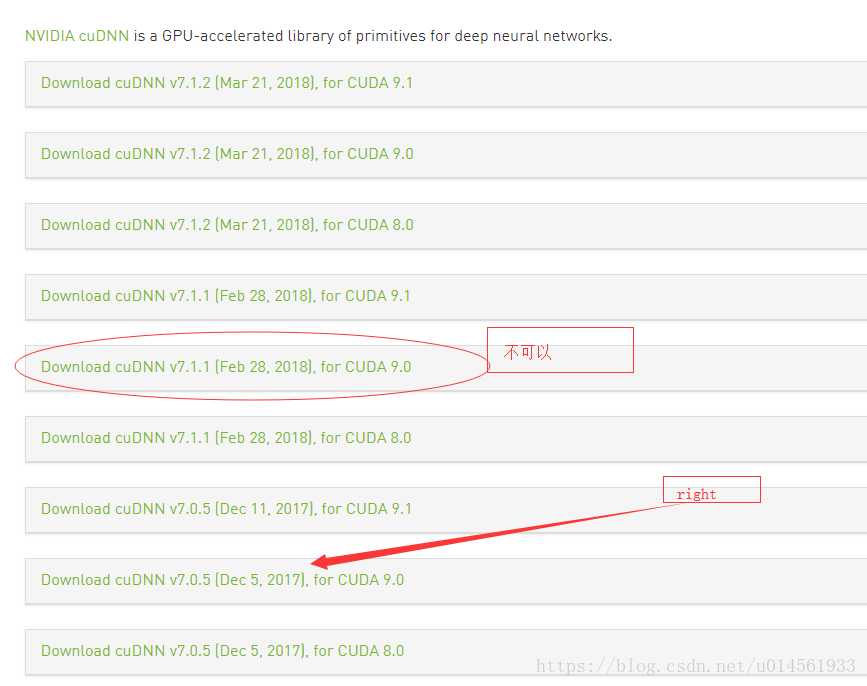
to solve this problem, it has been proposed to install CUDA9.0:
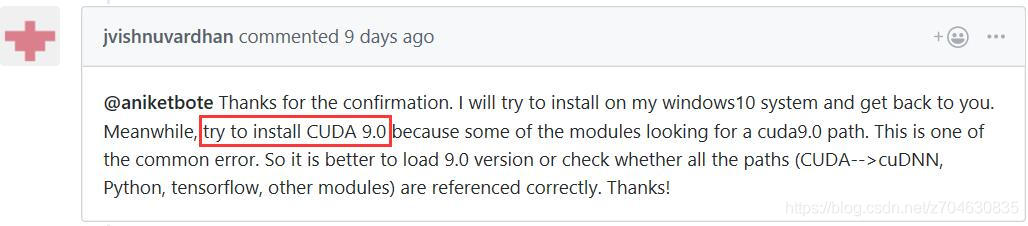
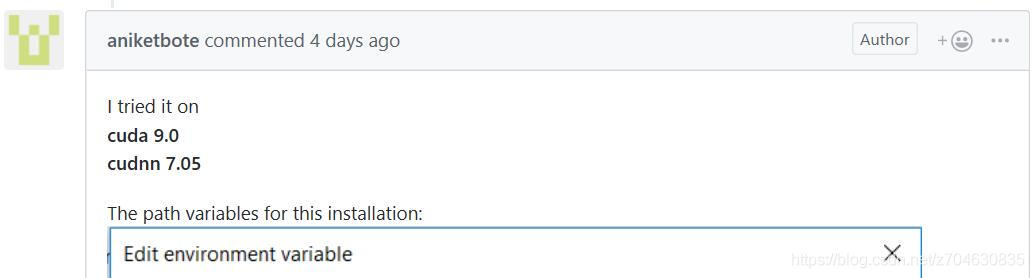
then the host reconfigured his environment to CUDA9.0 and cuDNN7.05
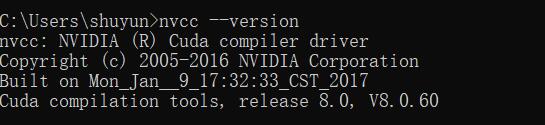
about how to view your CUDA version, you can open CMD, in CMD NVCC –version can be viewed:
here are some of the methods I’ve tried, but none of them solve the problem :
(1) install other versions of CUDA. But it didn’t solve the problem…
(2) update VS2015, reference blog: tensorflow installation issues and github. But it doesn’t solve the problem…
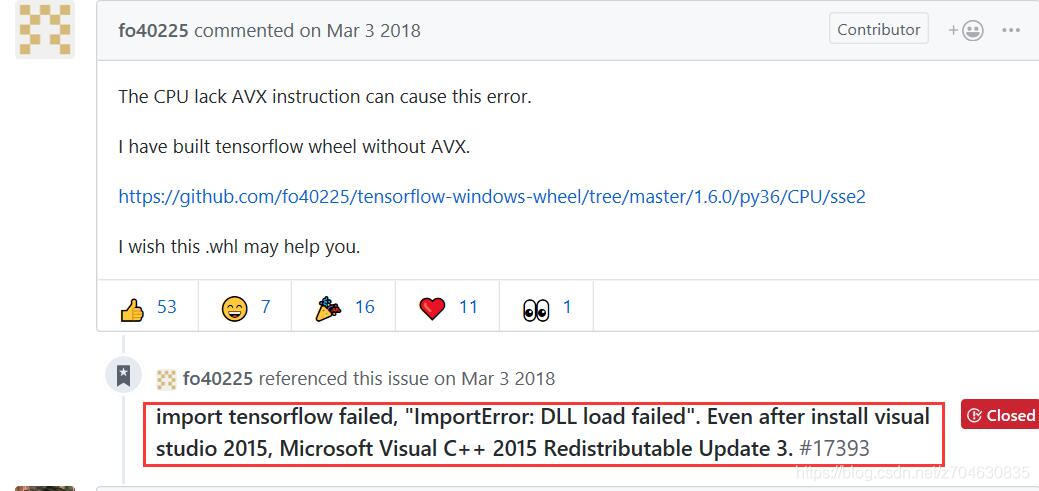
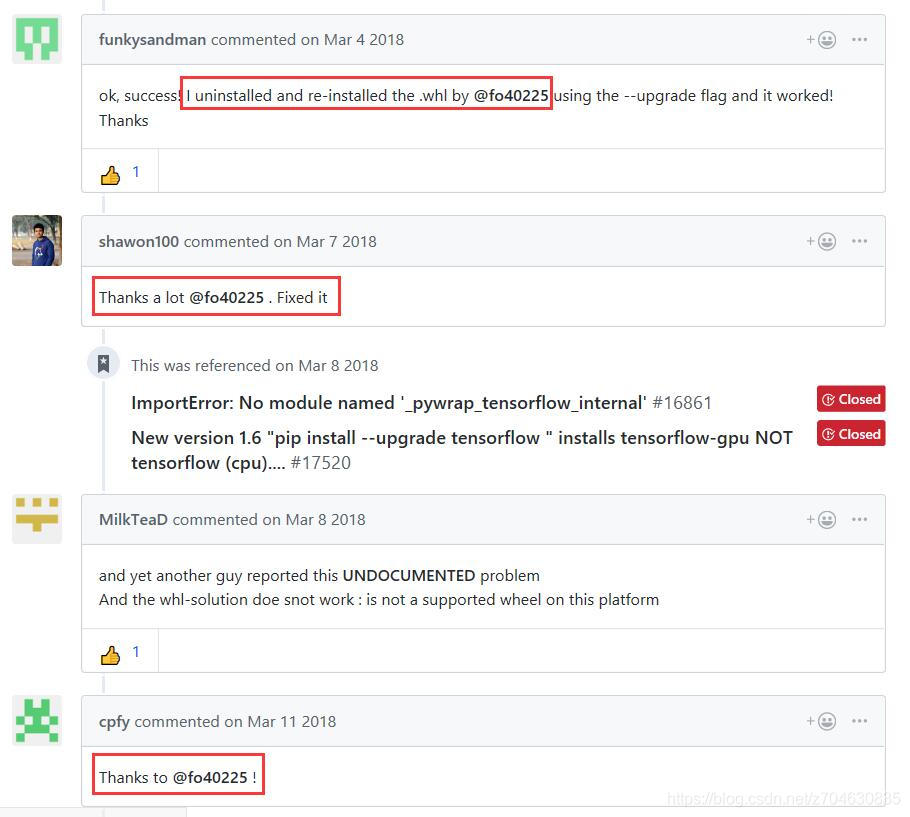
(3) continue to check the post on github, found that many people are thanking the layer master fo40255, is the layer master message above (2), reinstall the.whl file, but I did not try this method, I will mention my method later, below casually pick a paragraph of reply:
finally summed up my own way to solve this problem:
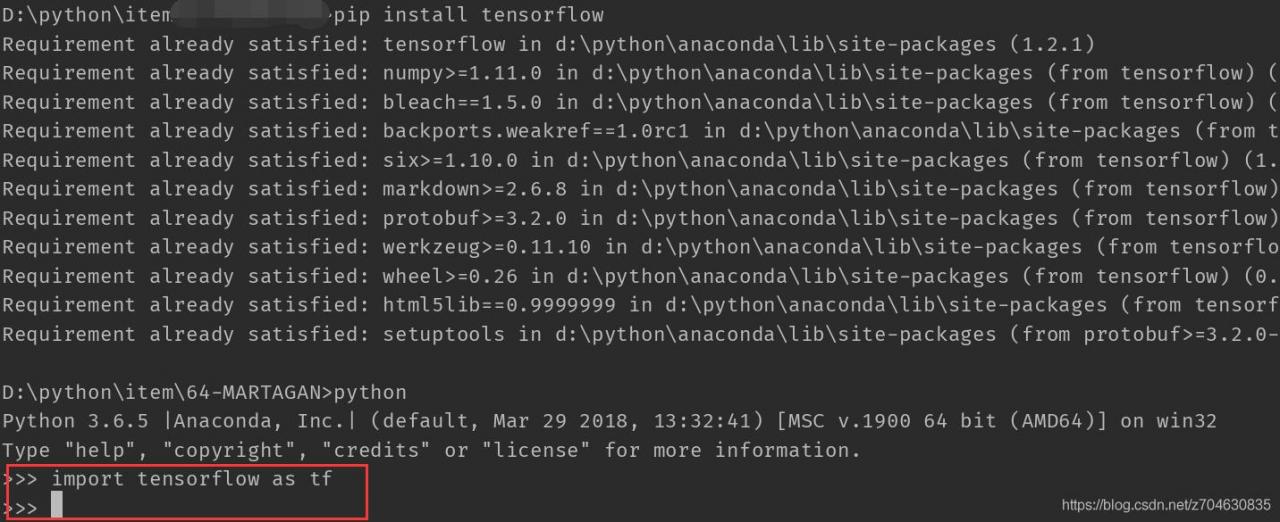
(1) open CMD and enter PIP uninstall tensorflow, that is, uninstall tensorflow.
(2) reinstall after uninstalling and enter PIP install tensorflow.
(3) after the installation of a simple test, no error. in short, if it breaks, reload… (that’s how I redid it anyway)
of course, if reinstall will not solve the problem, you can consider the above fo40255 layer of the main method, cover again. WHL file, the file link here also is given, by the way: https://github.com/fo40225/tensorflow-windows-wheel/tree/master/1.6.0/py36/CPU/sse2