In business scenarios, Python is often required to develop some small programs/scripts/GUI interfaces, which can be delivered to Xiaobai or partners who do not have Python installed
Deng Deng Deng Deng
pyinstaler
Scene description
Use pyinnstaller to package Python scripts or projects to generate executable. Exe files. Pyinstaller is a very good free packaging tool, supports windows, Linux and MacOS, and perfectly supports 32-bit and 64 bit systems. In addition to pyinstaller, you can also use py2exe for packaging
Pyinstaller installation
pip install pyinstaller
Packing parameters
# Common packing parameters
# -F -D mutually exclusive parameters
-F package into an exe file, small projects can be used, slow to open, multiple .py package can not be used
-D default parameter, package the result into the created folder, you can see a lot of dependency files inside
# -w -c mutually exclusive parameters
-w use the project GUI interface, no cmd console
-c default parameter, use cmd console If the execution of the package file reports an error, you can try to use -c to show the console
-n the name of the execution project, default .py file name
-i package ico icon into exe file
--hidden-import package information when packaging
# It is highly recommended to package PyQt projects with the following parameters
--hidden-import PyQt5.sip
# Example package command
# Execute the package command in the root directory of the project
pyinstaller -w xxx.py --hidden-import PyQt5.sip
# The output of the package is in the dist folder in the project's root directory
# It is not recommended to use -F to package into an exe file as the saying goes: package for a while, open for 5 seconds
# Non-F command, static resources, built Sqlite database can be put directly into the dist generated folder
explain
Pyinstaller just packages Python interpreter and script into an executable file, which is different from compiling into real machine code. So the efficiency of the code is reduced, only to solve the operation difficulty of Xiaobai users. When packaging, we will analyze the project dependencies, package the related dependencies, and encrypt them. Different operating systems need to be packaged in different operating systems
Summary of solutions to packaging problems
Console debug
runs successfully locally. It is recommended to use the - C command when the EXE is packaged for the first time, so that possible error messages can be displayed in the console
if the - C is not used during packaging, the console will not appear or the console will flash by and the error message will not be seen, you can execute the EXE file fatal error failed to execute script file in the CMD command line window
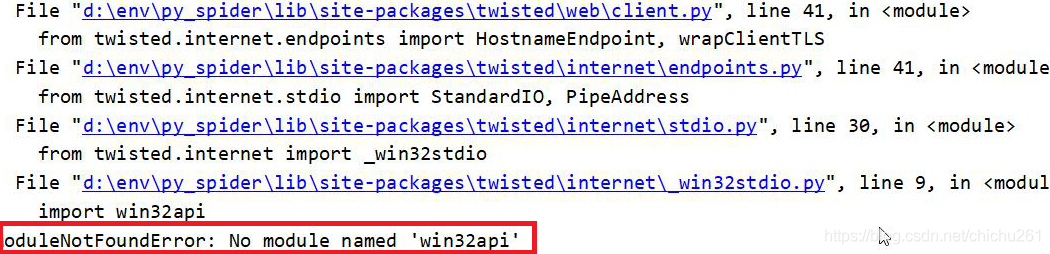
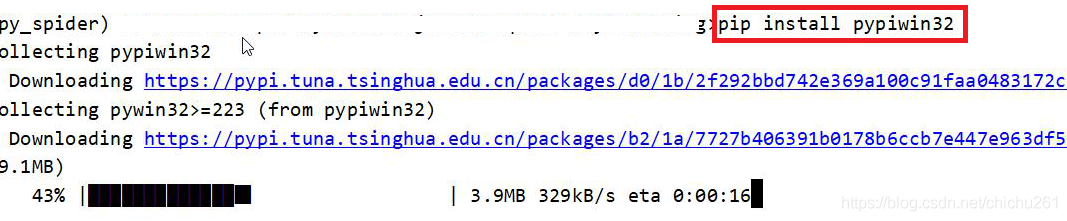
pyinstaller. Some libraries are not packaged during packaging, The library in error reporting information can be packaged by -- hidden import error reporting package
Solutions to various errors in pyinstall packaging python3.6 + pyqt5
The result file is too large
Parameters in help
>>> pyinstaller -h
usage: pyinstaller [-h] [-v] [-D] [-F] [--specpath DIR] [-n NAME]
[--add-data <SRC;DEST or SRC:DEST>]
[--add-binary <SRC;DEST or SRC:DEST>] [-p DIR]
[--hidden-import MODULENAME]
[--additional-hooks-dir HOOKSPATH]
[--runtime-hook RUNTIME_HOOKS] [--exclude-module EXCLUDES]
[--key KEY] [-d {all,imports,bootloader,noarchive}] [-s]
[--noupx] [--upx-exclude FILE] [-c] [-w]
[-i <FILE.ico or FILE.exe,ID or FILE.icns>]
[--version-file FILE] [-m <FILE or XML>] [-r RESOURCE]
[--uac-admin] [--uac-uiaccess] [--win-private-assemblies]
[--win-no-prefer-redirects]
[--osx-bundle-identifier BUNDLE_IDENTIFIER]
[--runtime-tmpdir PATH] [--bootloader-ignore-signals]
[--distpath DIR] [--workpath WORKPATH] [-y]
[--upx-dir UPX_DIR] [-a] [--clean] [--log-level LEVEL]
scriptname [scriptname ...]
positional arguments:
scriptname name of scriptfiles to be processed or exactly one
.spec-file. If a .spec-file is specified, most options
are unnecessary and are ignored.
optional arguments:
-h, --help show this help message and exit
-v, --version Show program version info and exit.
--distpath DIR Where to put the bundled app (default: .\dist)
--workpath WORKPATH Where to put all the temporary work files, .log, .pyz
and etc. (default: .\build)
-y, --noconfirm Replace output directory (default:
SPECPATH\dist\SPECNAME) without asking for
confirmation
--upx-dir UPX_DIR Path to UPX utility (default: search the execution
path)
-a, --ascii Do not include unicode encoding support (default:
included if available)
--clean Clean PyInstaller cache and remove temporary files
before building.
--log-level LEVEL Amount of detail in build-time console messages. LEVEL
may be one of TRACE, DEBUG, INFO, WARN, ERROR,
CRITICAL (default: INFO).
What to generate:
-D, --onedir Create a one-folder bundle containing an executable
(default)
-F, --onefile Create a one-file bundled executable.
--specpath DIR Folder to store the generated spec file (default:
current directory)
-n NAME, --name NAME Name to assign to the bundled app and spec file
(default: first script's basename)
What to bundle, where to search:
--add-data <SRC;DEST or SRC:DEST>
Additional non-binary files or folders to be added to
the executable. The path separator is platform
specific, ``os.pathsep`` (which is ``;`` on Windows
and ``:`` on most unix systems) is used. This option
can be used multiple times.
--add-binary <SRC;DEST or SRC:DEST>
Additional binary files to be added to the executable.
See the ``--add-data`` option for more details. This
option can be used multiple times.
-p DIR, --paths DIR A path to search for imports (like using PYTHONPATH).
Multiple paths are allowed, separated by ';', or use
this option multiple times
--hidden-import MODULENAME, --hiddenimport MODULENAME
Name an import not visible in the code of the
script(s). This option can be used multiple times.
--additional-hooks-dir HOOKSPATH
An additional path to search for hooks. This option
can be used multiple times.
--runtime-hook RUNTIME_HOOKS
Path to a custom runtime hook file. A runtime hook is
code that is bundled with the executable and is
executed before any other code or module to set up
special features of the runtime environment. This
option can be used multiple times.
--exclude-module EXCLUDES
Optional module or package (the Python name, not the
path name) that will be ignored (as though it was not
found). This option can be used multiple times.
--key KEY The key used to encrypt Python bytecode.
How to generate:
-d {all,imports,bootloader,noarchive}, --debug {all,imports,bootloader,noarchive}
Provide assistance with debugging a frozen
application. This argument may be provided multiple
times to select several of the following options.
- all: All three of the following options.
- imports: specify the -v option to the underlying
Python interpreter, causing it to print a message
each time a module is initialized, showing the
place (filename or built-in module) from which it
is loaded. See
https://docs.python.org/3/using/cmdline.html#id4.
- bootloader: tell the bootloader to issue progress
messages while initializing and starting the
bundled app. Used to diagnose problems with
missing imports.
- noarchive: instead of storing all frozen Python
source files as an archive inside the resulting
executable, store them as files in the resulting
output directory.
-s, --strip Apply a symbol-table strip to the executable and
shared libs (not recommended for Windows)
--noupx Do not use UPX even if it is available (works
differently between Windows and *nix)
--upx-exclude FILE Prevent a binary from being compressed when using upx.
This is typically used if upx corrupts certain
binaries during compression. FILE is the filename of
the binary without path. This option can be used
multiple times.
Windows and Mac OS X specific options:
-c, --console, --nowindowed
Open a console window for standard i/o (default). On
Windows this option will have no effect if the first
script is a '.pyw' file.
-w, --windowed, --noconsole
Windows and Mac OS X: do not provide a console window
for standard i/o. On Mac OS X this also triggers
building an OS X .app bundle. On Windows this option
will be set if the first script is a '.pyw' file. This
option is ignored in *NIX systems.
-i <FILE.ico or FILE.exe,ID or FILE.icns>, --icon <FILE.ico or FILE.exe,ID or FILE.icns>
FILE.ico: apply that icon to a Windows executable.
FILE.exe,ID, extract the icon with ID from an exe.
FILE.icns: apply the icon to the .app bundle on Mac OS
X
Windows specific options:
--version-file FILE add a version resource from FILE to the exe
-m <FILE or XML>, --manifest <FILE or XML>
add manifest FILE or XML to the exe
-r RESOURCE, --resource RESOURCE
Add or update a resource to a Windows executable. The
RESOURCE is one to four items,
FILE[,TYPE[,NAME[,LANGUAGE]]]. FILE can be a data file
or an exe/dll. For data files, at least TYPE and NAME
must be specified. LANGUAGE defaults to 0 or may be
specified as wildcard * to update all resources of the
given TYPE and NAME. For exe/dll files, all resources
from FILE will be added/updated to the final
executable if TYPE, NAME and LANGUAGE are omitted or
specified as wildcard *.This option can be used
multiple times.
--uac-admin Using this option creates a Manifest which will
request elevation upon application restart.
--uac-uiaccess Using this option allows an elevated application to
work with Remote Desktop.
Windows Side-by-side Assembly searching options (advanced):
--win-private-assemblies
Any Shared Assemblies bundled into the application
will be changed into Private Assemblies. This means
the exact versions of these assemblies will always be
used, and any newer versions installed on user
machines at the system level will be ignored.
--win-no-prefer-redirects
While searching for Shared or Private Assemblies to
bundle into the application, PyInstaller will prefer
not to follow policies that redirect to newer
versions, and will try to bundle the exact versions of
the assembly.
Mac OS X specific options:
--osx-bundle-identifier BUNDLE_IDENTIFIER
Mac OS X .app bundle identifier is used as the default
unique program name for code signing purposes. The
usual form is a hierarchical name in reverse DNS
notation. For example:
com.mycompany.department.appname (default: first
script's basename)
Rarely used special options:
--runtime-tmpdir PATH
Where to extract libraries and support files in
`onefile`-mode. If this option is given, the
bootloader will ignore any temp-folder location
defined by the run-time OS. The ``_MEIxxxxxx``-folder
will be created here. Please use this option only if
you know what you are doing.
--bootloader-ignore-signals
Tell the bootloader to ignore signals rather than
forwarding them to the child process. Useful in
situations where e.g. a supervisor process signals
both the bootloader and child (e.g. via a process
group) to avoid signalling the child twice.