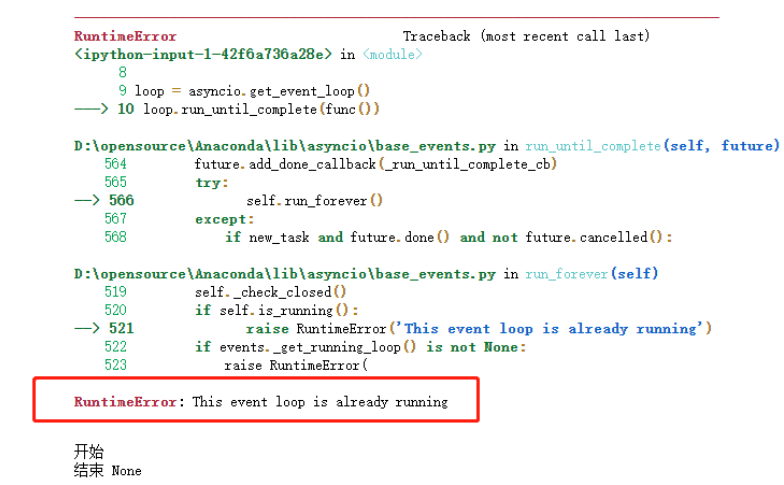
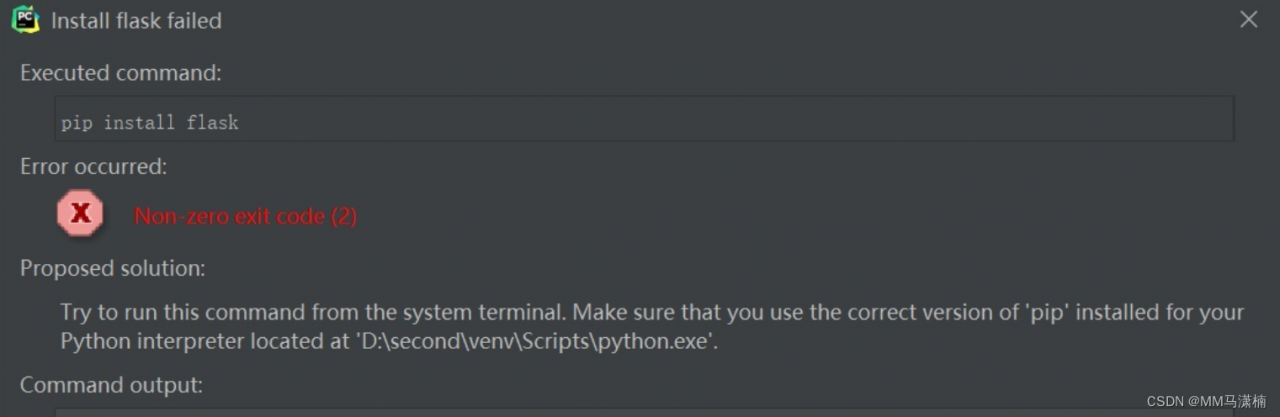
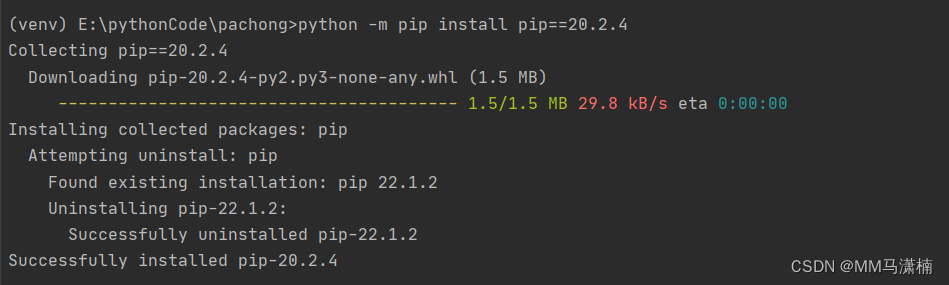
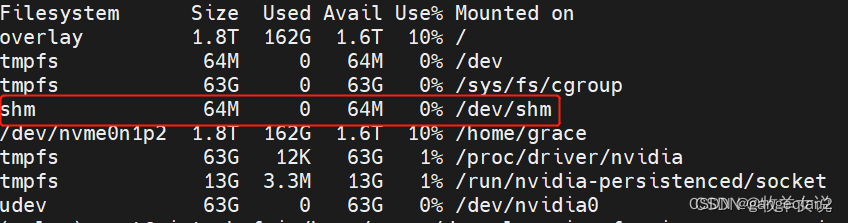
The following error occurred while running the project:
[nltk_data] Error loading stopwords: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
[nltk_data] Error loading averaged_perceptron_tagger: <urlopen error
[nltk_data] [Errno 11004] getaddrinfo failed>
The Solution is as follows:
Go to: https://github.com/nltk/nltk_data
Go to the directory /packages/corpora/ and find the corresponding file stopwords.zip and put it under the corresponding file
It is recommended that the entire nltk_data project is downloaded with a size of 695M to avoid other problems that cannot be downloaded!
Extract the zip file
nltk_data-gh-pages.zip\nltk_data-gh-pages\packages
all files to the following directory
C:\Users\Administrator\AppData\Roaming\nltk_data
Here the installation directory may be different for each person, here I am in the above directory.
Modify the corresponding file.
\venv\Lib\site-packages\chatterbot\utils.py under the current project directory
(Some children’s directory may not be under the current project, you can find the corresponding site-packages directory according to your own configuration and then find the corresponding files to modify)
The corresponding code nltk_download_corpus(‘xxx’) needs to be modified as follows:
def download_nltk_stopwords():
"""
Download required NLTK stopwords corpus if it has not already been downloaded.
"""
nltk_download_corpus('corpora/stopwords')
def download_nltk_wordnet():
"""
Download required NLTK corpora if they have not already been downloaded.
"""
nltk_download_corpus('corpora/wordnet')
def download_nltk_averaged_perceptron_tagger():
"""
Download the NLTK averaged perceptron tagger that is required for this algorithm
to run only if the corpora has not already been downloaded.
"""
nltk_download_corpus('taggers/averaged_perceptron_tagger')
def download_nltk_vader_lexicon():
"""
Download the NLTK vader lexicon for sentiment analysis
that is required for this algorithm to run.
"""
nltk_download_corpus('sentiment/vader_lexicon')
Done!