Unable to find “e:\pythonenv\dataspider\lib\sit-packages\setuptools-40.8.0-py3.7.egg\EGG-INFO” when adding binary and data files.
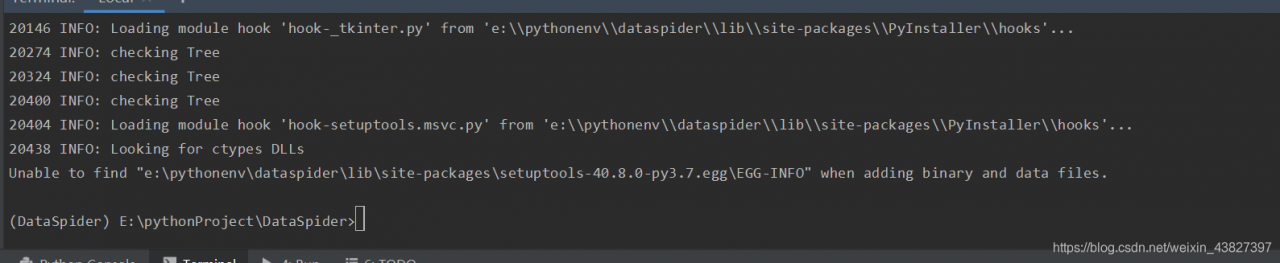
Error resolution.
The version of setuptools is too low, upgrade the version on it, click File-settings-project:xxx-Project interpreter – click
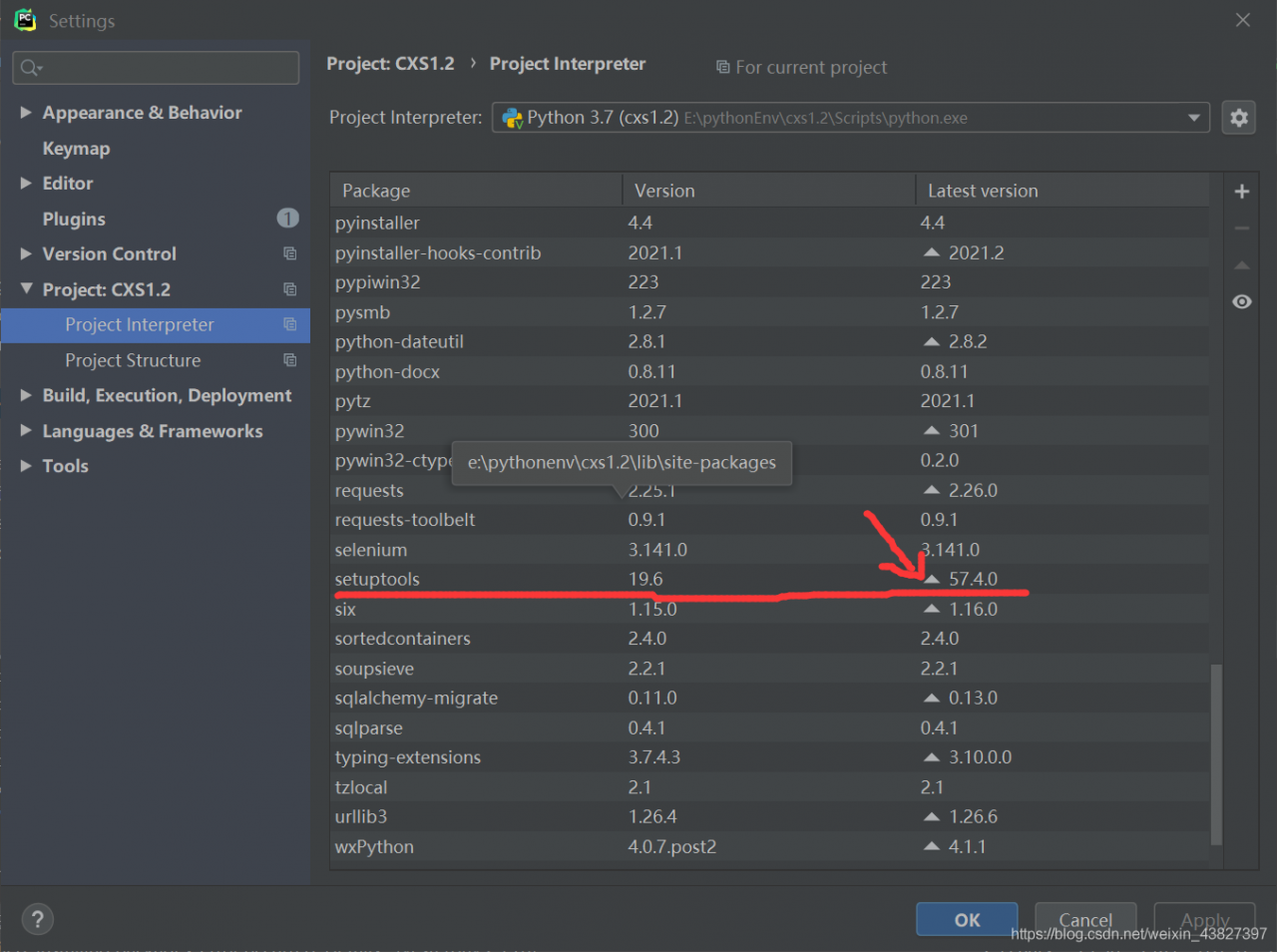
然后install package即可
Tag Archives: python
[Solved] RuntimeError: Numpy is not available (Associated Torch or Tensorflow)
Runtimeerror: numpy is not available solution
Problem Description:
Today, the old computer crashed (cried) and the new computer got started. I couldn’t wait to install the pytorch and check the operation of the previous project. As a result, there was an error running the model training
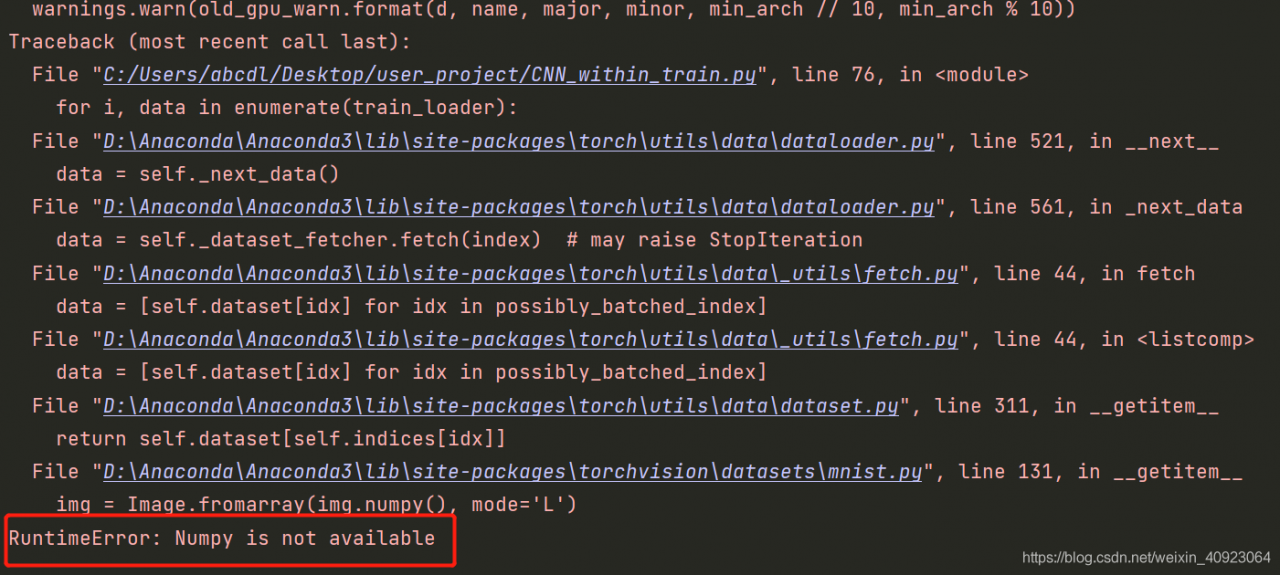
the key sentence is the sentence loading the model training data
for i, data in enumerate(train_loader):
The bottom layer of this statement is applied to the operation of converting the tensor variable to numpy, that is
import numpy
import torch
test_torch = torch.rand(100,1,28,28)
print(test_torch.numpy())
# will produce the same error

Problem root
The direct correlation between pytoch and tensorflow is ignored
if there is only torch but no tensorflow in the environment, the tensor variable used by torch will lose the tensor related operation function, such as torch. Numpy()
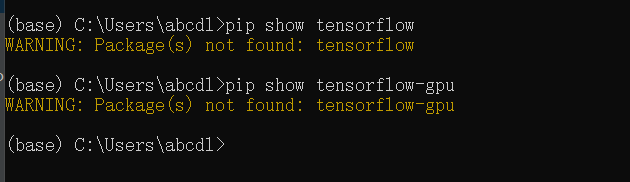
Solution:
Install tensorflow in the basic environment, whether CPU version or GPU version
in Anaconda environment, you can directly
conda install tensorflow
Otherwise pip
pip install --ignore-installed --upgrade tensorflow-gpu
From the tensorboard command line, enter tensorboard — logdir$$
On the tensorboard command line, enter tensorboard — logdir = log (log is the name of the stored log, which is variable. If it is not written, it defaults to runs)
The following is the directory structure
The log storage location in the code

the generated directory structure
needs to enter the directory of the project. In Lily’s folder, the log of this article is saved as log, so execute the command tensorboard — logdir = log to enter and exit http://localhost:6006 You can see the visualization results

(Caused by SSLError(SSLError(1, ‘[SSL: WRONG_VERSION_NUMBER] wrong version number (_ssl.c:1123)‘)))
You want to use Python’s request library to call the company interface and create some data, but you finally report an error
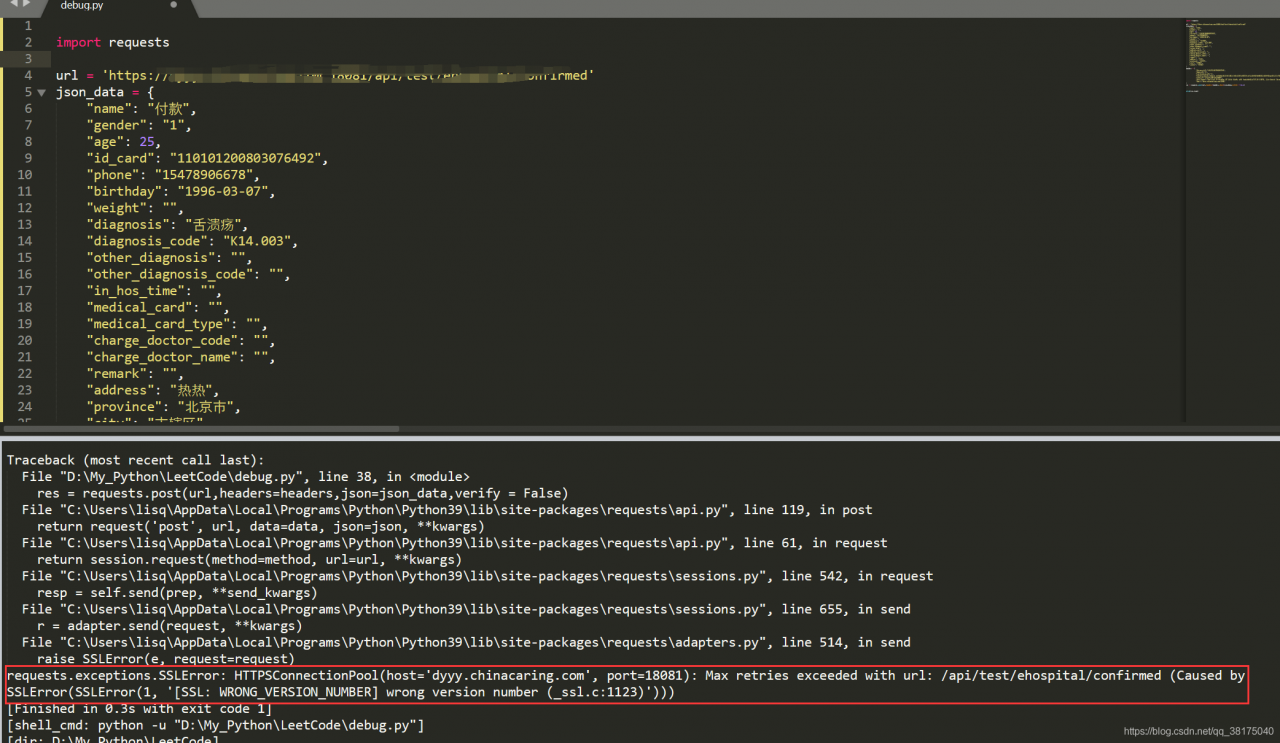
Traceback (most recent call last):
File "D:\My_Python\LeetCode\debug.py", line 38, in <module>
res = requests.post(url,headers=headers,json=json_data,verify = False)
File "C:\Users\lisq\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\api.py", line 119, in post
return request('post', url, data=data, json=json, **kwargs)
File "C:\Users\lisq\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "C:\Users\lisq\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\sessions.py", line 542, in request
resp = self.send(prep, **send_kwargs)
File "C:\Users\lisq\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\sessions.py", line 655, in send
r = adapter.send(request, **kwargs)
File "C:\Users\lisq\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\adapters.py", line 514, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='dyyy.chinacaring.com', port=18081): Max retries exceeded with url: /api/test/ehospital/confirmed (Caused by SSLError(SSLError(1, '[SSL: WRONG_VERSION_NUMBER] wrong version number (_ssl.c:1123)')))
I searched many methods on the Internet and tried to verify = false, but it didn’t work.
finally, I found that it was because my packet capture tool was on, because I first used the packet capture tool to catch the interface, and then used the requests library to operate. The packet capture tool Charles was not off.
just turn off the packet capture tool
AttAttributeError: module ‘typing‘ has no attribute ‘NoReturn‘
Problem Description:
an error is reported when installing tensorflow GPU = = 1.4.1 in the virtual environment with Python version 3.6.0
AttAttributeError: module ‘typing’ has no attribute ‘NoReturn’
Cause analysis:
Python version is too low. Python has changed a lot since 3.6
Solution:
install a newer version of python, and you can solve the problem above 3.6.2
UserWarning: Failed to initialize NumPy: No module named ‘numpy.core._multiarray_umath‘
This error is usually caused by the mismatch of numpy versions, and the related MKL libraries are also uninstalled
pip unstall numpy
pip unstall mkl-serviceThen PIP reinstall it
I just don’t know why I can’t solve it with CONDA uninstall + reinstall. Just replace it with PIP. It seems that there is a difference between uninstall and installed library?
Opencv Python realizes the paint filling function in PS, one click filling color and the possible reasons for opencv’s frequent errors
First of all, first solve the opencv error problem, once up on the error report headache
cv2.error: OpenCV(4.5.3) C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-z4706ql7\opencv\modules\highgui\src\window.cpp:1274: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support. If you are on Ubuntu or Debian, install libgtk2.0-dev and pkg-config, then re-run cmake or configure script in function ‘cvShowImage’
This version is probably not downloaded well, delete and start again
pip uninstall opencv-pythonThen download the command
pip3 install opencv-contrib-pythonNice successfully solved the problem. Of course, there may be errors in the path with Chinese or spaces, and sometimes errors will be reported.
No more code, no more nonsense
import cv2 as cv
import numpy as np
def fill_color_demo(image): #Define the function to fill the color with one click
Img2 = image.copy() # make a copy of the input image
h, w = image.shape[:2] #Get the length and width of the image
mask = np.zeros([h+2, w+2],np.uint8) #mask must be row and column plus 2, and must be uint8 single-channel array, fill the edges need more than 2 pixels, otherwise it will report an error
cv.floodFill(Img2, mask, (100, 100), (127, 127, 127), (100, 100, 100), (50, 50 ,50), cv.FLOODFILL_FIXED_RANGE)
#cv.floodFill, parameter 1,: indicates the input image, parameter 2: indicates the mask of a single channel, parameter 3: indicates the starting point of the flooding algorithm, parameter 4 indicates the color of the fill, and parameters 5,6 indicate the maximum positive and negative difference between the currently observed pixel point and the neighboring pixel points
#x coordinates are from left to right, y coordinates are from top to bottom
cv.imshow("result", Img2) # display the result image
img = cv.imread('. /1.jpg') # read in the image
cv.imshow('input', img) #Show the input image
fill_color_demo(img) #Transfer the input image into the defined fill color function
cv.waitKey(0) Then there is the result, as shown below
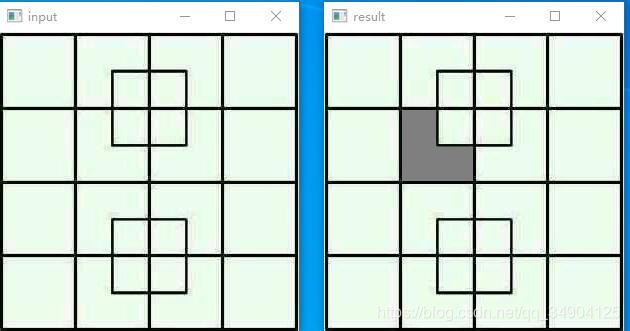
On the left is the original image of input and on the right is the output image. The color is (127127) gray and the coordinates are (100100). You can change the color coordinates as you like. It’s still very fun
Remember to like, pay attention to and collect
[Solved] Sudo doesn‘t work: “/etc/sudoers is owned by uid 1000, should be 0”
1.error
When I type a sudo command into the terminal it shows the following error:
sudo: /etc/sudoers is owned by uid 1000, should be 0
sudo: no valid sudoers sources found, quitting
sudo: unable to initialize policy plugin
How do I fix this?
2. Solution:
Change the owner back to root:
pkexec chown root:root /etc/sudoers /etc/sudoers.d -R
Or use the visudo command to ensure general correctness of the files:
pkexec visudo
How to Solve RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu
In this case, the data and models are generally one in the CPU, one in the GPU, or the data used for calculation. Some have been put in the GPU, and some still exist in the CPU. Here is an idea.
First, find the error reporting line, see which variables or data are used in the calculation, and then use. Is_ CUDA this attribute to check which are on the GPU and which are on the CPU, and then put them on the CPU or GPU. for instance:
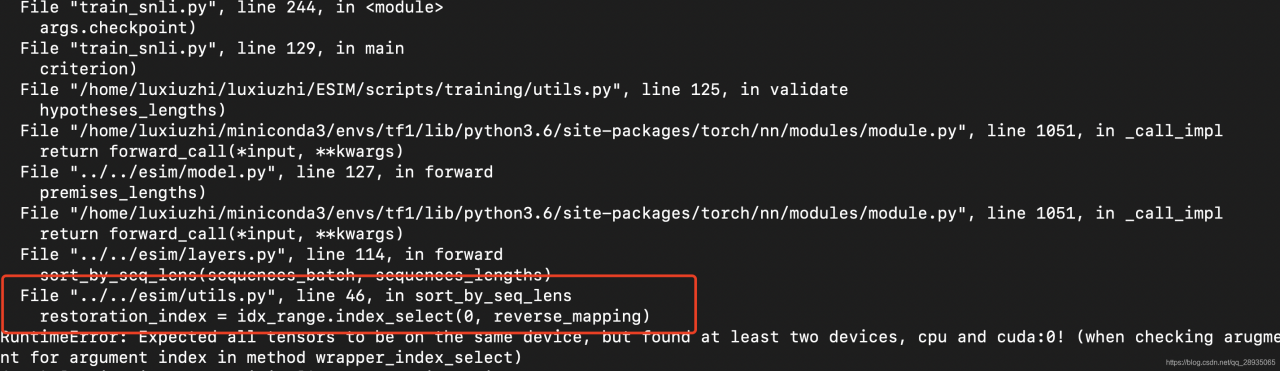
The error message indicates that there is a problem in line 46 of utils.py. Then enter the file and locate line 46
Print idx_ Range and reverse_ Mapping to check whether it is on the GPU or the CPU at the same time,
print(idx_ range.is_cuda,reverse_mapping.is_cuda)
After verification, IDX was found_ Range on CPU, reverse_ Mapping on GPU, idx_ Range on GPU (IDX)_ Range. To (device)), problem-solving
[Solved] modulenotfounderror: no module named ‘torchtext.legacy.data.datasets_ utils‘
Cause: pytorch version is too low## Title
Solution.
Step 1: Find the utils.py file inside the downloaded E:\anaconda\package\envs\pytorch_gpu\Lib\site-packages\d2lzh_pytorch installation package and open it.
Step 2: Change the import torchtext inside to import torchtext.legacy as torchtext
Step 3: Close jupyter and reopen it, successfully.
Nginx manager jupyter notebook v1.0.0 http websocket
v1.0.0
Environment introduction
1、 The virtual machine on this machine. There is jupyter in the virtual machine
2、 Jupyter notebook web server is an online editor
3、 A proxy server on this machine, such as nginx
Configuration steps
1、 Virtual machine
Start the virtual machine
2、 Jupyter
Set the root directory of the file
sudo GEDIT (VIM) ~ /. Jupyter/jupyter_ notebook_ config.py
c.NotebookApp.notebook_dir = '/path/to/jupyter'
sudo gedit(vim)~/.jupyter/jupyter notebook config.py
c.NotebookApp.allow_origin = '*' # allow cors
3、 Nginx
Start nginx configuration nginx.conf excerpt
# Actual tcp/websocket server address
upstream jupyter_url {
server virtual machine ip:8888;
}
server {
listen 8000;
server_name localhost;
charset utf-8;
location/{
proxy_pass http://jupyter_url;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
Test effect
Visit: nginxip: 8000
‘c’ argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapp
When Python draws a line chart, using scatter, the use of parameter C = ” will cause warning:
ax.scatter(x_value,y_value,c=(0,0.2,0),s=10)
‘c’ argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with ‘x’ & ‘y’. Please use a 2-D array with a single row if you really want to specify the same RGB or RGBA value for all points.
It may be a problem with the version of matplotlib, higher versions no longer report a warning.
You can change the original statement to the following one.
ax.scatter(x_value,y_value,color=(0,0.2,0),s=10)
Or let the log display only errors of error level:
from matplotlib.axes._axes import _log as matplotlib_axes_logger
matplotlib_axes_logger.setLevel('ERROR')
Hope to help you through sharing, thank you.