Abnormal information
npm ERR! code 1
npm ERR! path D:\demo\node_modules\node-sass
npm ERR! command failed
npm ERR! command C:\Windows\system32\cmd.exe /d /s /c node scripts/build.js
npm ERR! Building: C:\Program Files\nodejs\node.exe D:\demo\node_modules\node-gyp\bin\node-gyp.js rebuild --verbose --libsass_ext= --libsass_cflags= --libsass_ldflags= --libsass_library=
npm ERR! gyp info it worked if it ends with ok
npm ERR! gyp verb cli [
npm ERR! gyp verb cli 'C:\\Program Files\\nodejs\\node.exe',
npm ERR! gyp verb cli 'D:\\demo\\node_modules\\node-gyp\\bin\\node-gyp.js',
npm ERR! gyp verb cli 'rebuild',
npm ERR! gyp verb cli '--verbose',
npm ERR! gyp verb cli '--libsass_ext=',
npm ERR! gyp verb cli '--libsass_cflags=',
npm ERR! gyp verb cli '--libsass_ldflags=',
npm ERR! gyp verb cli '--libsass_library='
npm ERR! gyp verb cli ]
npm ERR! gyp info using [email protected]
npm ERR! gyp info using [email protected] | win32 | x64
npm ERR! gyp verb command rebuild []
npm ERR! gyp verb command clean []
npm ERR! gyp verb clean removing "build" directory
npm ERR! gyp verb command configure []
npm ERR! gyp verb check python checking for Python executable "python2" in the PATH
npm ERR! gyp verb `which` failed Error: not found: python2
npm ERR! gyp verb `which` failed at getNotFoundError (D:\demo\node_modules\which\which.js:13:12)
npm ERR! gyp verb `which` failed at F (D:\demo\node_modules\which\which.js:68:19)
npm ERR! gyp verb `which` failed at E (D:\demo\node_modules\which\which.js:80:29)
npm ERR! gyp verb `which` failed at D:\demo\node_modules\which\which.js:89:16
npm ERR! gyp verb `which` failed at D:\demo\node_modules\isexe\index.js:42:5
npm ERR! gyp verb `which` failed at D:\demo\node_modules\isexe\windows.js:36:5
npm ERR! gyp verb `which` failed at FSReqCallback.oncomplete (node:fs:195:21)
npm ERR! gyp verb `which` failed python2 Error: not found: python2
npm ERR! gyp verb `which` failed at getNotFoundError (D:\demo\node_modules\which\which.js:13:12)
npm ERR! gyp verb `which` failed at F (D:\demo\node_modules\which\which.js:68:19)
npm ERR! gyp verb `which` failed at E (D:\demo\node_modules\which\which.js:80:29)
npm ERR! gyp verb `which` failed at D:\demo\node_modules\which\which.js:89:16
npm ERR! gyp verb `which` failed at D:\demo\node_modules\isexe\index.js:42:5
npm ERR! gyp verb `which` failed at D:\demo\node_modules\isexe\windows.js:36:5
npm ERR! gyp verb `which` failed at FSReqCallback.oncomplete (node:fs:195:21) {
npm ERR! gyp verb `which` failed code: 'ENOENT'
npm ERR! gyp verb `which` failed }
npm ERR! gyp verb check python checking for Python executable "python" in the PATH
npm ERR! gyp verb `which` succeeded python C:\Users\Administrator\AppData\Local\Programs\Python\Python39\python.EXE
npm ERR! gyp ERR! configure error
npm ERR! gyp ERR! stack Error: Command failed: C:\Users\Administrator\AppData\Local\Programs\Python\Python39\python.EXE -c import sys; print "%s.%s.%s" % sys.version_info[:3];
npm ERR! gyp ERR! stack File "<string>", line 1
npm ERR! gyp ERR! stack import sys; print "%s.%s.%s" % sys.version_info[:3];
npm ERR! gyp ERR! stack ^
npm ERR! gyp ERR! stack SyntaxError: invalid syntax
npm ERR! gyp ERR! stack
npm ERR! gyp ERR! stack at ChildProcess.exithandler (node:child_process:326:12)
npm ERR! gyp ERR! stack at ChildProcess.emit (node:events:394:28)
npm ERR! gyp ERR! stack at maybeClose (node:internal/child_process:1067:16)
npm ERR! gyp ERR! stack at Process.ChildProcess._handle.onexit (node:internal/child_process:301:5)
npm ERR! gyp ERR! System Windows_NT 10.0.19042
npm ERR! gyp ERR! command "C:\\Program Files\\nodejs\\node.exe" "D:\\demo\\node_modules\\node-gyp\\bin\\node-gyp.js" "rebuild" "--verbose" "--libsass_ext=" "--libsass_cflags=" "--libsass_ldflags=" "--libsass_library="
npm ERR! gyp ERR! cwd D:\demo\node_modules\node-sass
npm ERR! gyp ERR! node -v v16.3.0
npm ERR! gyp ERR! node-gyp -v v3.8.0
npm ERR! gyp ERR! not ok
npm ERR! Build failed with error code: 1
npm ERR! A complete log of this run can be found in:
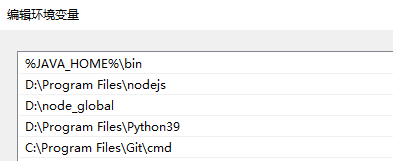
npm ERR! C:\Users\Administrator\AppData\Local\npm-cache\_logs\2021-06-22T01_36_13_984Z-debug.logConfigure environment variables
This is to exclude path customization without permission
NODE_ PATH=D:\node_ global\node_ modules
Put the critical path forward in the path
Global install cnpm
npm config set registry http://registry.npm.taobao.org/
npm i cnpm
Install windows platform compilation environment
npm install -g node-gyp
npm install –global –production windows-build-tools
Change the node sass version in package.json
“Node sass”: “~ 4.12.0” changed to “node sass”: “v4.13.0”
Delete node under root directory_ Modules folder
Cnpm reinstall
cnpm i