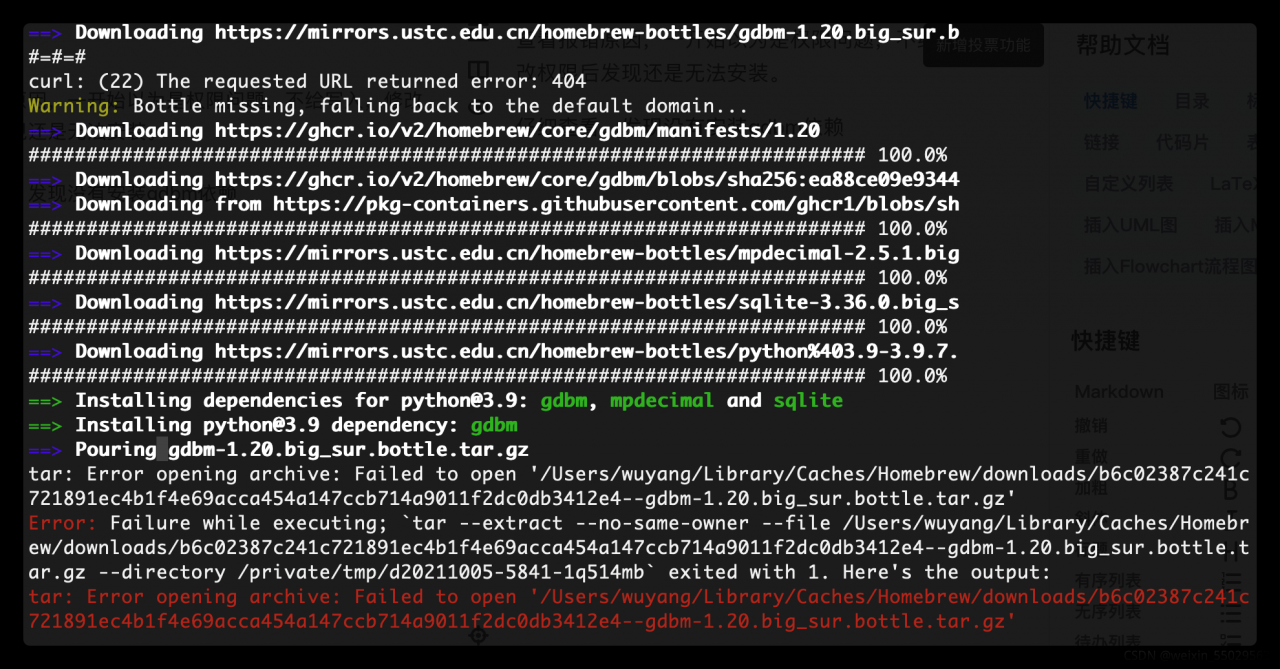
Background
At the beginning, I wrote an ArcGIS Python script, which is an independent script. I ran it in Python and ran it successfully. But if you put this script in the ArcGIS toolbox, it won’t work properly. The following errors are reported.
IndentationError: unexpected indent。
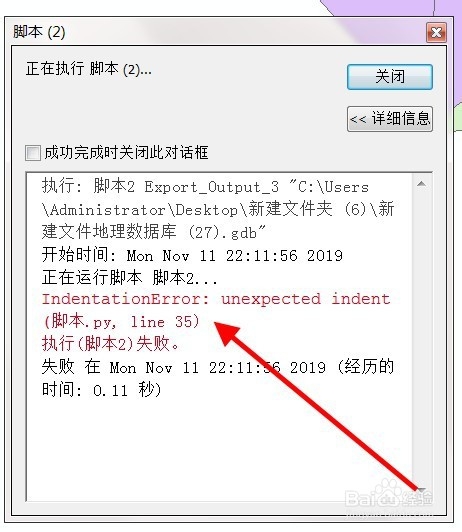
The above figure is an article from Baidu experience. Because there was no screenshot at that time, I didn’t bother to reproduce this problem again…
Find solutions
Code indentation problem
When searching for this error report on Baidu, most of the answers are to ask you to find the indentation problem and space problem in the code. As in the article from the above figure.
The problem is that my code can run successfully in pycharm, and I checked the code several times and found no problem…
Chinese in code (including Chinese in notes)
I use ArcGIS 10.2 and python version is 2.7. This version of Python doesn’t support Chinese very much, but generally you can run normally by adding # coding = UTF-8 at the beginning of the code in the python environment.
# coding=utf-8There is a Chinese comment on the last line of the wrong line of my code. So I tried to remove that line of Chinese notes and succeeded
Summary
1. If the python script of ArcGIS does not need Chinese, do not use Chinese
2. If you have to use Chinese, you can consider adding # coding: cp936 at the beginning of the script code