Python reports an error when connecting to the database. Command listdatabases requires authentication, full error: {OK ‘: 0.0,’ errmsg ‘:’ command listdatabases requires authentication ‘,’ code ‘: 13,’ codename ‘:’ unauthorized ‘}
The reason for the error is that authentication is required, indicating that user name and password authentication are required to connect to mongodb database.
Connect mongodb without password. The code is as follows:
from pymongo import MongoClient
class MongoDBConn:
def __init__(self, host, port, db_name, user, password):
"""
Establishing database connections
"""
self.conn = MongoClient(host, port)
self.mydb = self.conn[db_name]
With password authentication, connect to Mongo database, and the code is as follows:
from pymongo import MongoClient
class MongoDBConn:
def __init__(self, host, port, db_name, user, password):
"""
Establishing database connections
"""
self.conn = MongoClient(host, port)
self.db = self.conn.admin
self.db.authenticate(user, password)
self.mydb = self.conn[db_name]
Pit record
In fact, an error was reported in the middle:
Authentication failed., full error: {‘ok’: 0.0, ‘errmsg’: ‘Authentication failed.’, ‘code’: 18, ‘codeName’: ‘AuthenticationFailed’}
Originally used directly in the code:
self.db = self.conn[db_name]
self.db.authenticate(user, password)
If you directly use the target database for link authentication, you will report the above error. Instead, first connect to the system default database admin, use admin for authentication, and you will succeed, and then do the corresponding operation for the target database.

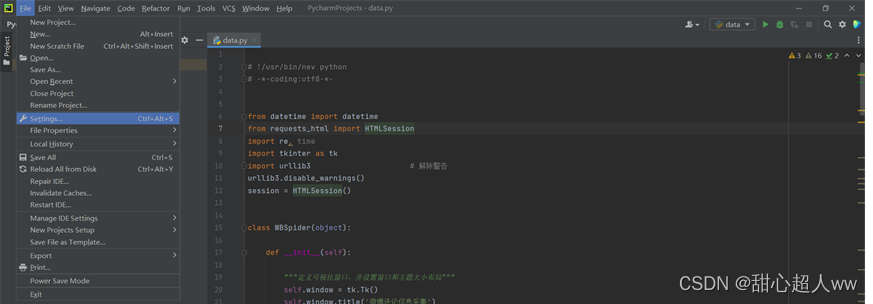
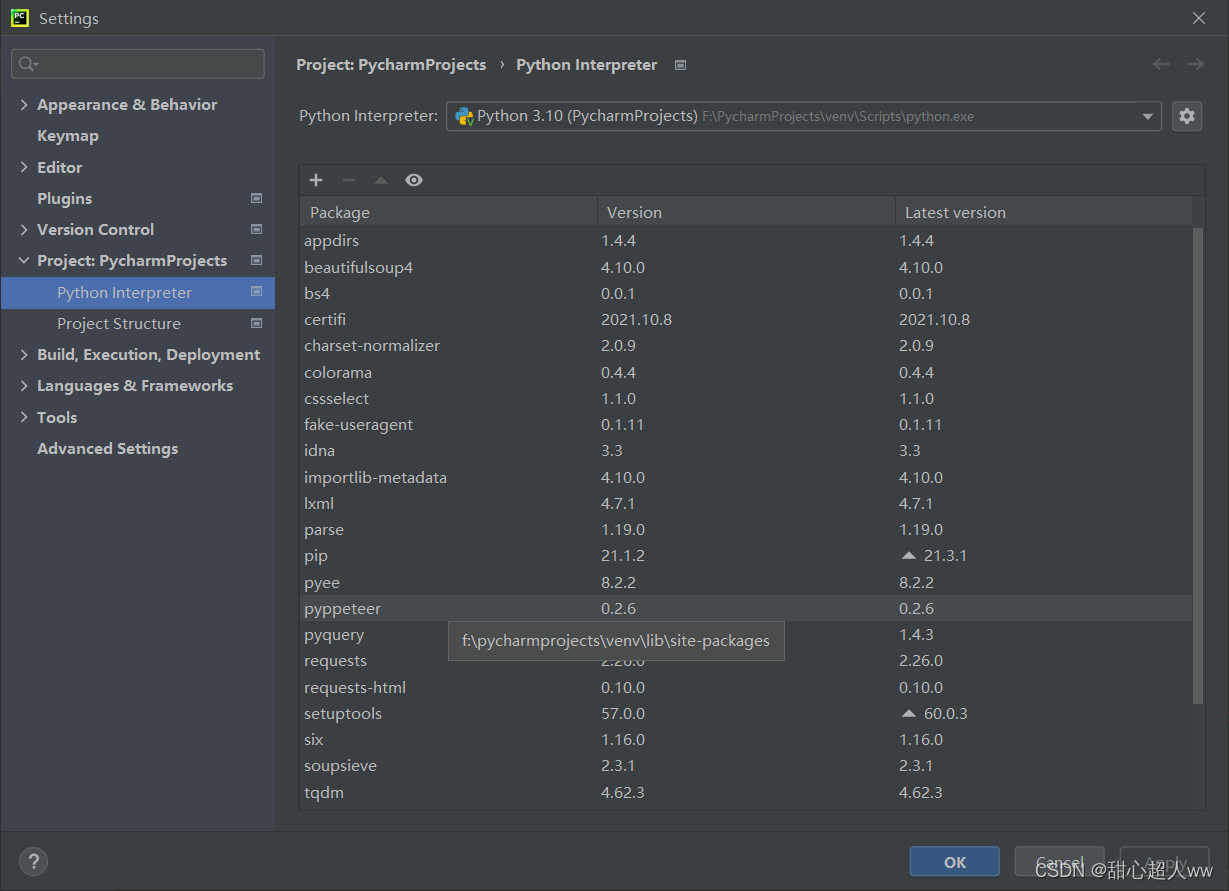
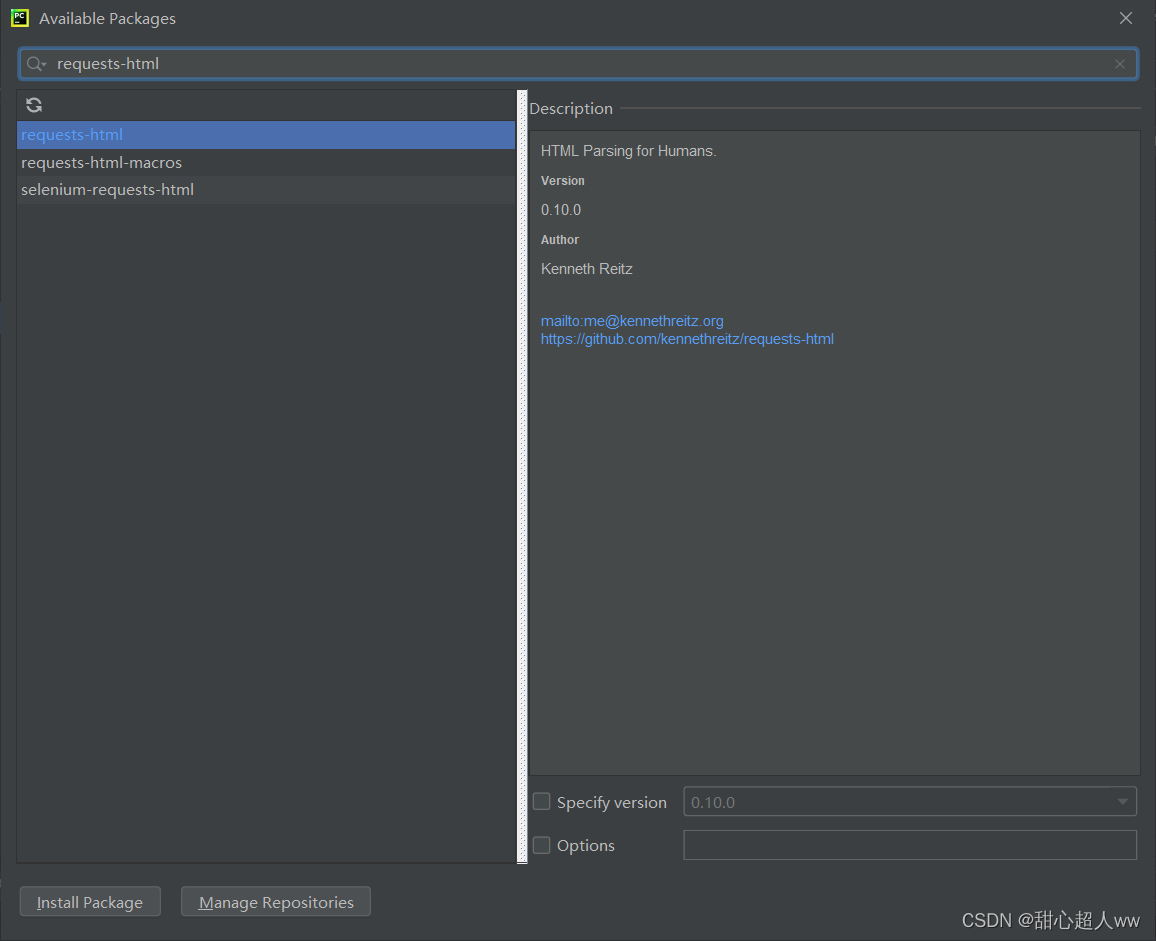
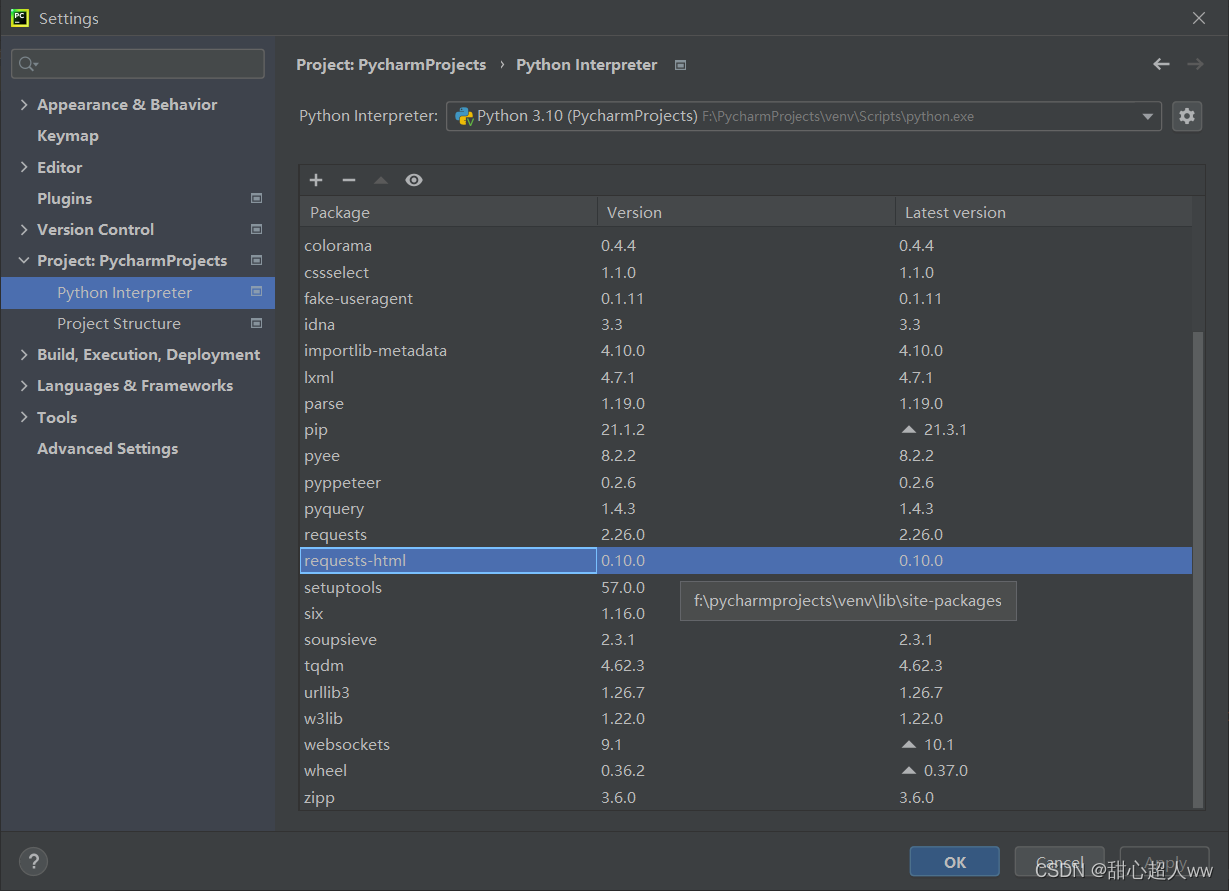

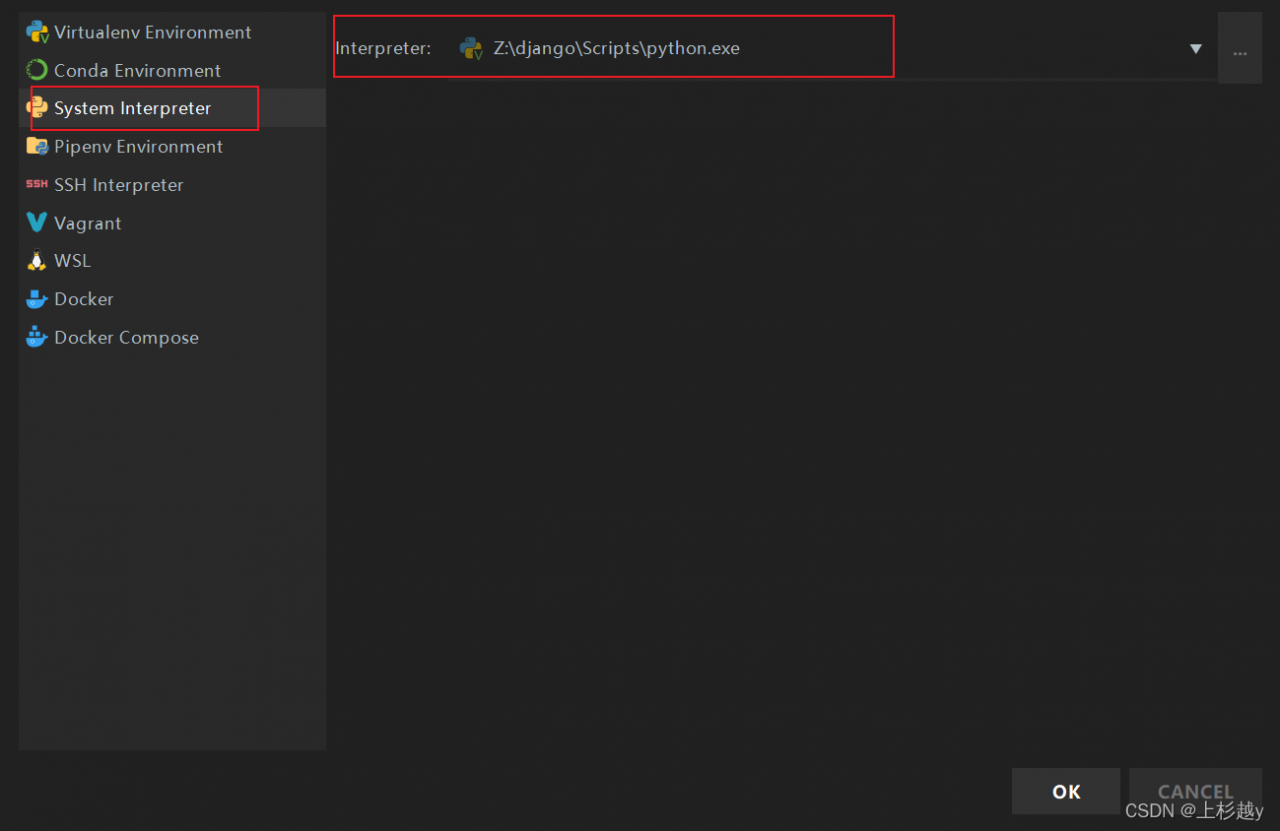
 in Python, file => settings=> project interpreter=> add=> System
in Python, file => settings=> project interpreter=> add=> System