1. Problem description
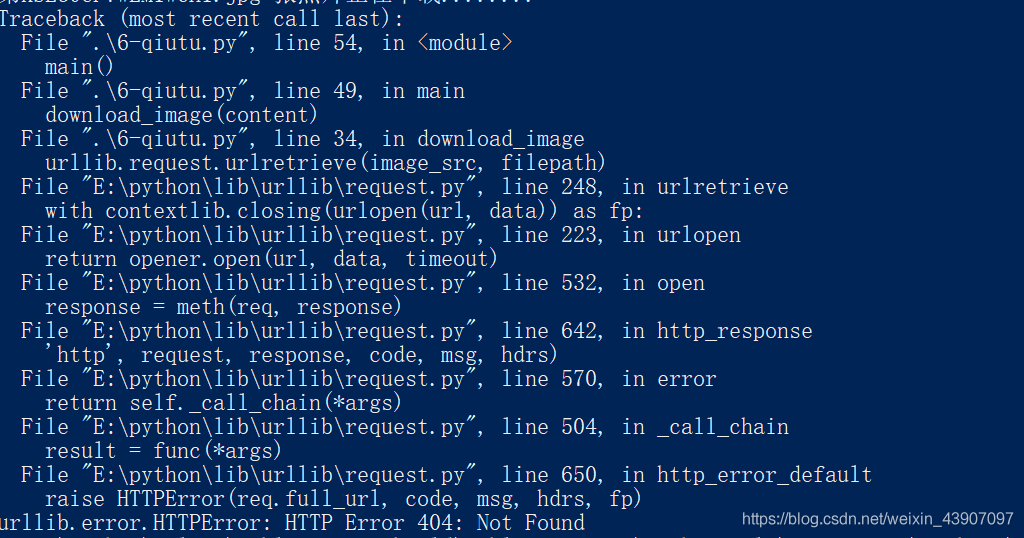
The following error occurred during crawler batch download
raise ContentTooShortError(
urllib.error.ContentTooShortError: <urlopen error retrieval incomplete: got only 0 out of 290758 bytes>2. Cause of problem
Problem cause: urlretrieve download is incomplete
3. Solution
1. Solution I
Use the recursive method to solve the incomplete method of urlretrieve to download the file. The code is as follows:
def auto_down(url,filename):
try:
urllib.urlretrieve(url,filename)
except urllib.ContentTooShortError:
print 'Network conditions is not good.Reloading.'
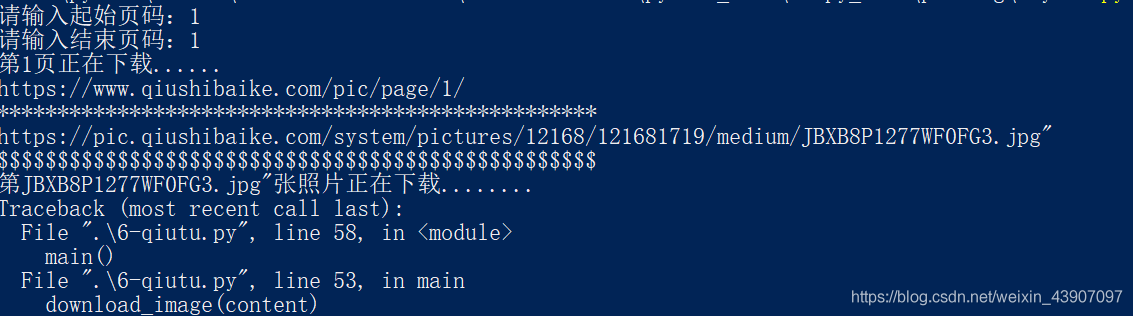
auto_down(url,filename)However, after testing, urllib.ContentTooShortError appears in the downloaded file, and it will take too long to download the file again, and it will often try several times, or even more than a dozen times, and occasionally fall into a dead cycle. This situation is very unsatisfactory.
2. Solution II
Therefore, the socket module is used to shorten the time of each re-download and avoid falling into a dead cycle, so as to improve the operation efficiency
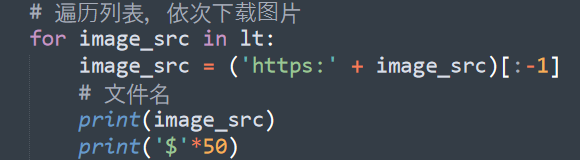
the following is the code:
import socket
import urllib.request
#Set the timeout period to 30s
socket.setdefaulttimeout(30)
#Solve the problem of incomplete download and avoid falling into an endless loop
try:
urllib.request.urlretrieve(url,image_name)
except socket.timeout:
count = 1
while count <= 5:
try:
urllib.request.urlretrieve(url,image_name)
break
except socket.timeout:
err_info = 'Reloading for %d time'%count if count == 1 else 'Reloading for %d times'%count
print(err_info)
count += 1
if count > 5:
print("downloading picture fialed!")