1. Project scenario
Host os:kylin-server-10-sp1-release-build02-20210518-arm64
docker:docker-ce-18.09.7
cloud: openstack queens
storage: same acs5000
VM os: kylin-server-10-sp1-release-build02-20210518-arm64
2. Problem description and cause analysis
2.1 problem description
The volume-based virtual machine can be created normally, but the error after restarting the virtual machine, checking the logs of nova-compute, found that it reports ProcessExecutionError:unexpected error while running command. command: multipah -f 320b508ca45022b80 failed, map in use, failed to remove multipath map 320b508ca45022b80.
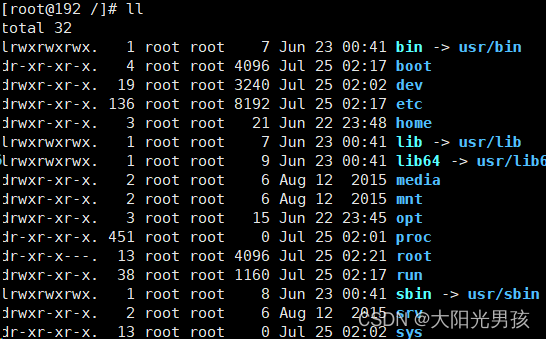
I manually executed multipah -f 320b508ca45022b80, and it did report the status of in use, so I suspect that there are processes using the volume, and I found that the same volume group name was activated through lvdisplay, vgdisplay and lsblk, so I suspect that the virtual machine and the physical machine used the same volume group name, and the volume group name was activated after the virtual machine started. The VM has been activated, and the process of reactivating all logical volumes in the volume group failed, resulting in multipath -f failure. Therefore, we need to configure lvm to activate only the logical volumes of the system, check the system volumes by lsblk, and then configure accordingly, edit /etc/lvm/lvm.conf and modify the following content
devices {
filter = [ "a/sda/", "r/.*/" ]
}
allocation {
volume_list = ["klas"]
auto_activation_volume_list = ["klas"]
}
Restart service:
systemctl restart lvm2-lvmetad.service lvm2-lvmetad.socket
Re create the virtual machine and restart it. It is also recommended that the virtual machine adopt other volume group names
2.2 storage configuration
2.2.1 drive
Use the same driver version zeus-driver-3.1.2.000106, copy the driver to the cinder_volume container /usr/lib/python2.7/site-packages/cinder/volume/drivers/ directory and the cinder_backup container /usr/lib/python2.7/site-packages/cinder/backup/drivers/ directory, and restart the related services.
2.2.2 configure cinder volume
vim /etc/kolla/cinder-volume/cinder.conf
[DEFAULT]
enabled_backends=toyou_ssd
[toyou_ssd]
volume_driver = cinder.volume.drivers.zeus.Acs5000_iscsi.Acs5000ISCSIDriver
san_ip = x.x.x.x
use_mutipath_for_image_xfer = True
image_volume_cache_enabled = True
san_login = cliuser
san_password = ******
acs5000_volpool_name = toyou_ssd
acs5000_target = 0
volume_backend_name = toyou_ssd
Restart the cinder-volume service. For others, please refer to the “reference scheme”
3. Solutions
View the adopted system disk through lsblk, and then edit /etc/lvm/lvm.conf to modify the following contents
devices {
filter = [ "a/sda/", "r/.*/" ]
}
allocation {
volume_list = ["klas"]
auto_activation_volume_list = ["klas"]
}
Restart service:
systemctl restart lvm2-lvmetad.service lvm2-lvmetad.socket
Note that it is mainly the filter. The drive letter in the filter is determined by the system disk recognized by lsblk, which may be SDB or nvme, etc