First, let’s look at the page error reporting example:
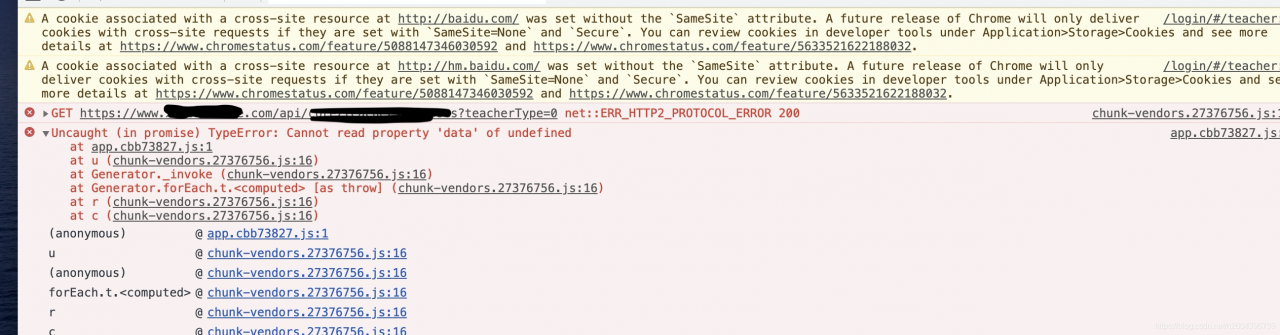
Net ::ERR_HTTP2_PROTOCOL_ERROR 200 shows up after multiple calls from multiple interfaces
Therefore, it is basically concluded that it is not a single interface or database problem, because we used four Nginx for load balancing and forwarding, so it is basically concluded that nginx is the problem, but which machine in Nginx and what causes it?
The positioning strategy in 2 is given below:
1) Observe the HEADER information in HTTP every time there is an error, and count the nginx information corresponding to via label in the header every time. This method can be derived from the problem of Nginx.
Below:
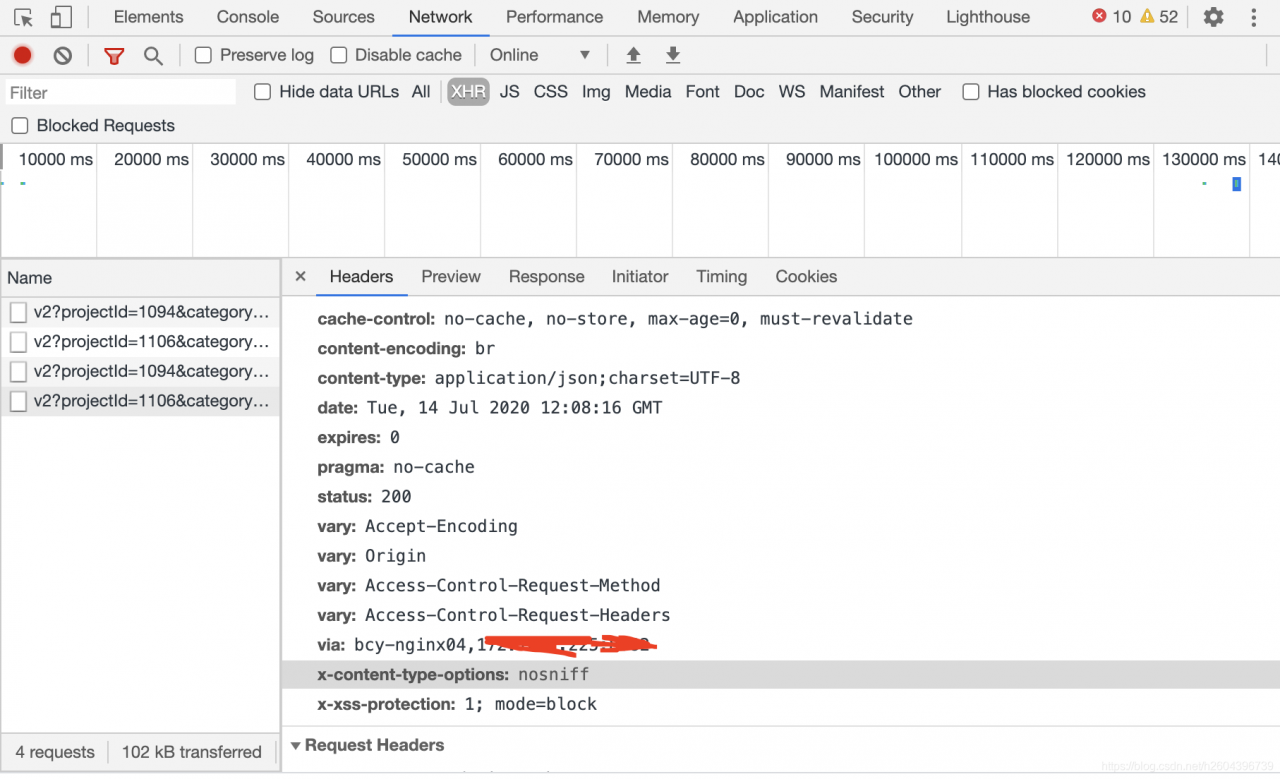
2) In the dead of night, no one else called the service, so I called it by myself. I checked the log files of each Nginx service separately to see which machine would have error information when there was a problem. Here is my machine error log:
2020/07/13 11:45:52 [Error] 20217#0: *85294045 Open () “/usr/local/nginx-1.18/ HTML /50x.html” failed (2: No such File or Directory), Client: 100.97.200.204, Server: www.test.com, Request: “POST/API/core/scratch/exercise/HTTP/1.1”, the host: “www.test.com”, referrer, “https://www.test.com/scratch/v3/?token=aee00163e0b79bf004a0001& projectType=1& practiceType=2& lesson=0172cd54dad800163e0b79bf004a0001& class=7712bc6db96f48febccafe008d9869a1& templateId=65032& category=2& role=1& fr=ts& canSave=1& isOnline=0”
This method gives the specific reason for the error, which I have seen here is that the file does not exist and cannot be opened.
Then I communicated with operation and maintenance and found out that Nginx upgraded today, but only reload was not restarted, so the solution to the problem caused by some cached information was to restart Nginx after operation and maintenance.
Here’s an article on the difference between nginx restart and Reload:
https://www.cnblogs.com/fanggege/p/12145956.html