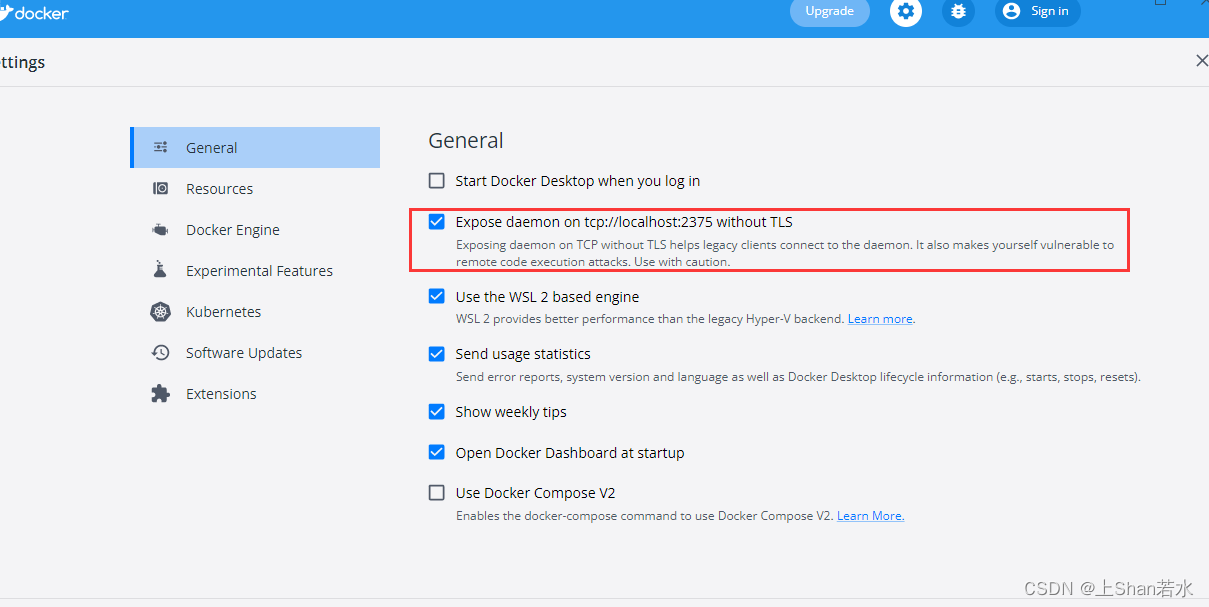
The docker service on the Linux server cannot be started after running for a period of time
Record a docker service problem encountered at the customer’s site
Problem description
After running the docker service for a period of time, some services are killed and cannot be restarted successfully through docker compose. Check the docker service log and report an error stream copy error: reading from a closed FIFO
Troubleshooting process:
1. The initial positioning is that there is not enough memory. Check with Free -g and find that the content is enough

2 After searching the Internet, some bloggers said that restarting docker could solve the problem. After restarting docker, they found that the error changed, and the service that didn’t get up before still couldn’t get up. The error became failed to allocate network resources for node *****
3 The network of docker service is the default. Regardless of the problem of docker network, changing the stack name and restarting still won’t work
4 Docker service PS ID/docker service logs ID check the service log that failed to start. It is found that the error log is still stream copy error: reading from a closed FIFO
5 Finally, before restarting the server, check the disk with the df -h command and find that the/dev/mapper/centosroot disk is full
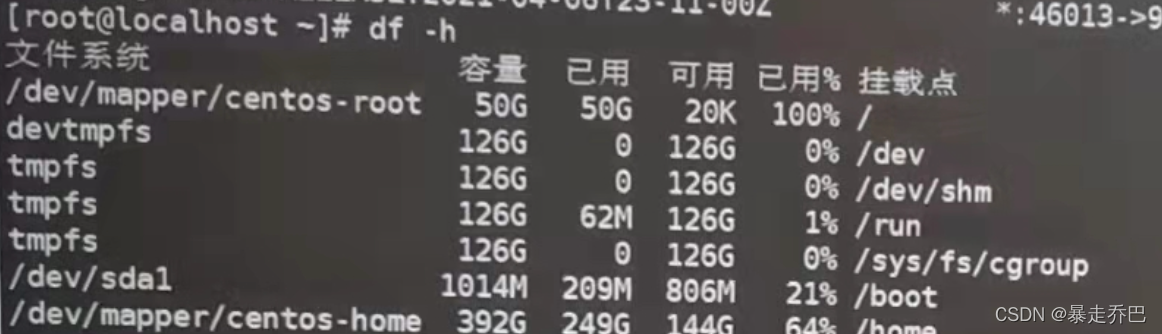
Solution:
Go to cd /var/log to delete some useless log files, if the current log files are small, you can use du -sh in the root directory to view those folders occupy a lot of space, generally the /var folder and /root folder will occupy the root disk, you need to delete the contents of these two folders