Problem Description:
In flash web development, we will use the flash migrate library to migrate the database, so as to submit the changed database model we wrote in the program script to the database without deleting and rebuilding the database model
if we use Python manage.py DB init to create a migration warehouse, and then use the migrate or upgrade in flash migrate, the following two instructions:
python manage.py db migrate
python manage.py db upgrade
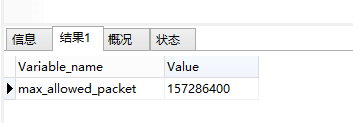
Error [flag_migrate] error: can’t locate revision identified by ‘a1c25fe0fc0e’ may appear. The identification number of ‘a1c25fe0fc0e’ corresponds to different database models! As shown in the figure:

resolvent:
The reason for the above error is that flash migrate cannot find the revision of “a1c25fe0fc0e” logo. We just need to indicate the missing logo number in the command
we can use the following commands in order in the shell command line window:
python app.py db revision --rev-id <Fill the prompt's identification number into this location, such as a1c25fe0fc0e above>
python app.py db migrate
python app.py db upgrade
Enter the following command to demonstrate:
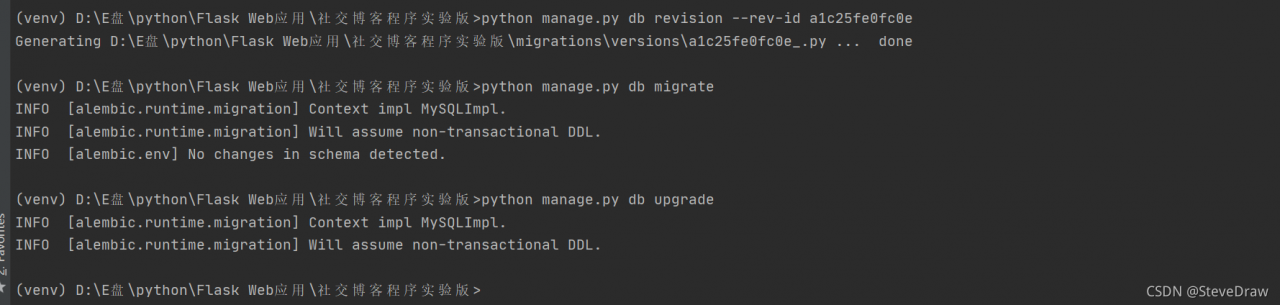
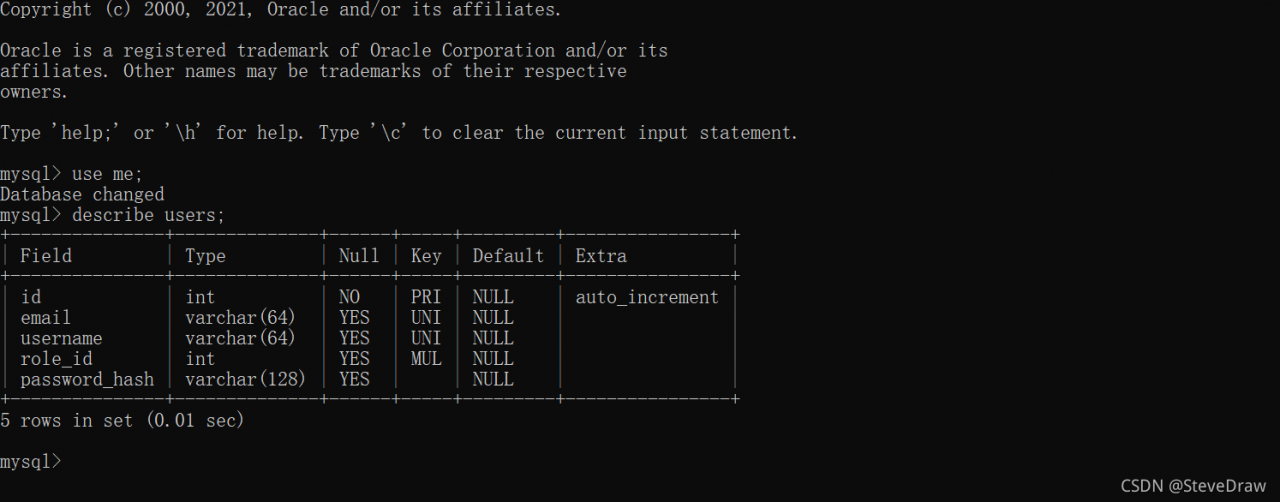
then, the database migration succeeds
Finally, if there are deficiencies in the article, criticism and correction are welcome!