Problem: back up the database on centos7 of the virtual machine, and an error occurs when executing mysqldump: error: ‘access denied; You need (at least one of) the process privilege (s) for this operation ‘when trying to dump tablespaces
[root@localhost backup]# sh ./mysql_backup.sh
Start exporting the database...
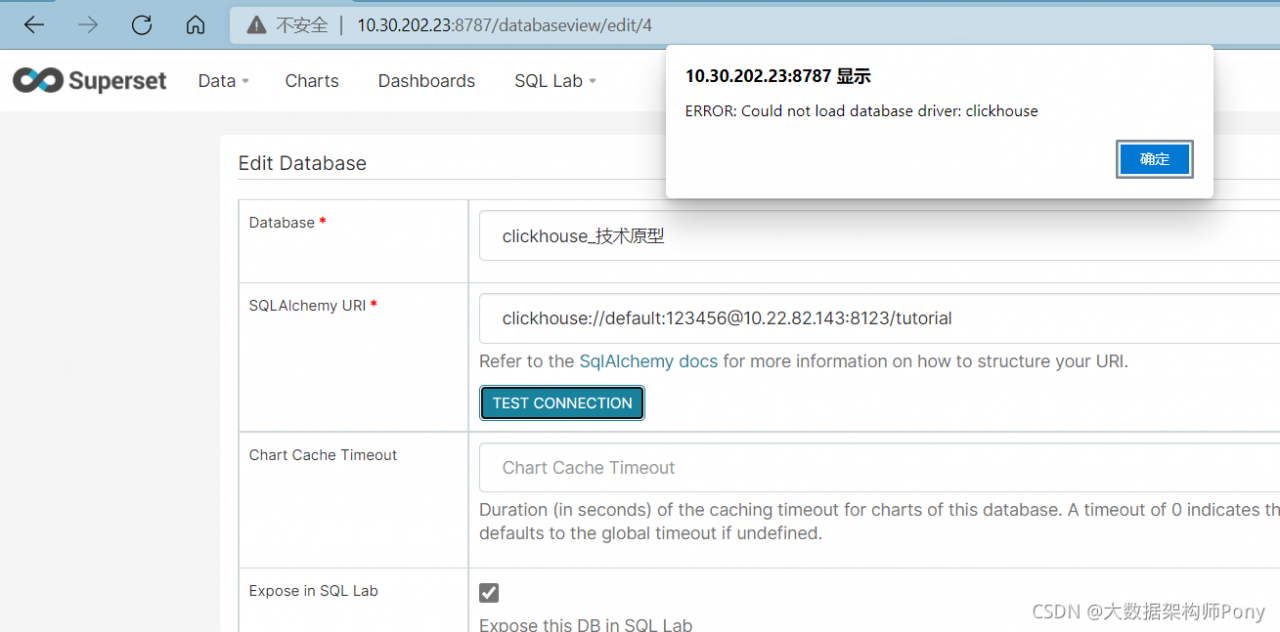
mysqldump: Error: 'Access denied; you need (at least one of) the PROCESS privilege(s) for this operation' when trying to dump tablespaces
The export was successful and the file name is : /data/backup/mysql/2021-10-06_003536.sql.gz
Solution: log in to MySQL with the root account in CentOS
[root@localhost backup]# mysql -uroot -p
Input password
Then execute the command
mysql> GRANT PROCESS ON *.* TO 'demo'@'localhost';
This demo should be changed to your own login database account
Then refresh the database
mysql> flush privileges;
All execution processes:
[root@localhost backup]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 61
Server version: 8.0.24 Source distribution
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> GRANT PROCESS ON *.* TO 'demo'@'localhost';
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
mysql> exit
Bye
[root@localhost backup]# sh ./mysql_backup.sh
Start exporting the database...
The export was successful and the file name is : /data/backup/mysql/2021-10-06_003815.sql.gz
[root@localhost backup]#
This method is accessed locally by the user
Another method is to change localhost to% by using the global access command
mysql> GRANT PROCESS ON *.* TO 'demo'@'%';
Similarly, change the demo to your own MySQL login account, and then execute the above command to refresh the database
I used the first method.