Error:
The solution:
Close pycharm and then open it again. It’s a perfect solution.
Error:
The solution:
Close pycharm and then open it again. It’s a perfect solution.
gensim error: AttributeError: The vocab attribute was removed from KeyedVector in Gensim 4.0.0.
Use KeyedVector’s .key_to_index dict, .index_to_key list, and methods .get_vecattr(key, attr) and .set_vecattr(key, attr, new_val) instead.
Solution:
1. directly modify the code
Find all the modules of vocab.keys() and modify them if they are mods defined by gensim.

Show:
## Wrong
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
words = np.random.choice(list(model.vocab.keys()), sample)
## Right
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
words = np.random.choice(list(model.key_to_index.keys()), sample)
Method 2: install the original version
!pip install gensim==3.0
There is a problem with strcpy(), but there is still a problem with strncpy().
#define PATH_MAX 128
e.g. strncpy(file_path, src, PATH_MAX);Strncpy () is prone to two problems: 1) the source string is too long, resulting in no terminator, and there are out of bounds garbled references. 2) the length of string is easily inconsistent with the nominal length. Like file_ Path says that it can support 128 characters at most. However, if the terminator is included, it is usually only 127.
Strncpy source code: when SRC reaches count, there is no terminator:
char* strncpy(char* dest, const char* source, size_t count)
{
char* start=dest;
while (count && (*dest++=*source++))
count--;
if(count)
while (--count)
*dest++='\0';
return(start);
}A good solution is:
1. Ensure that the length of the string is the nominal length, not the virtual mark
2. Secondly, it is not allowed to cross the boundary. It must have the correct ending character ‘\ 0’
3. The length of DST must be at least one character longer than Src
The possible implementation is as follows: using safe_ Strncpy (), and get DST length for security check
#define PATH_MAX 128
char file_path[PATH_MAX+1];
e.g. safe_strncpy(file_path, src,PATH_MAX+1, PATH_MAX);
int safe_strncpy(char *dst, const char *src, size_t dst_size,size_t str_size)
{
if(dst_size <= str_size)
return -1;
dst[dst_size-1] = '\0';
return strncpy(dst,src,str_size);
}The key is to make sure that the DST string is long enough.
It’s not very good to check at run time. The reason is that you have to test it before you can find the problem.
A better solution is to check the DST length during compilation.
GCC compile time checking scheme
GCC seems to have started to support compile time assertions in 4.3
_ Static_ assert( expr,”msg”)
If the code is wrongly written and the DST space is equal to size, there is no terminator bug and an error should be reported.
The following font string file_ Path supports 128 characters, but file does not_ The path definition space is also 128, which should be defined as 129
#define PATH_MAX 128
char file_path[PATH_MAX];
e.g. safe_strncpy(file_path, src, PATH_MAX);
The results are as follows
../include/comm.h:202:5: error: static assertion failed: "strncp small buf size error"
_Static_assert( sizeof(dst) > size,"strncp small buf size error");\
^
cmd_mark.c:137:13: note: in expansion of macro ‘safe_strncpy’
safe_strncpy(file_path, optarg, OS_PATH_MAX);
The code is as follows:
#define safe_strncpy(dst,src,size) \
do { \
_Static_assert( sizeof(dst) > size,"strncp small buf size error");\
_safe_strncpy(dst,src,sizeof(dst),size); \
}while(0)In this way, all calls to safe can be guaranteed as long as they are compiled_ There’s enough space for strncpy().
The power of compile time assertions lies in finding problems earlier than at run time. If someone misuses safe_ Strncpy (char * PTR, SRC, size) also finds problems in code ahead of time, rather than at run time or even after release.
As shown in the figure (CodeBlocks IDE)
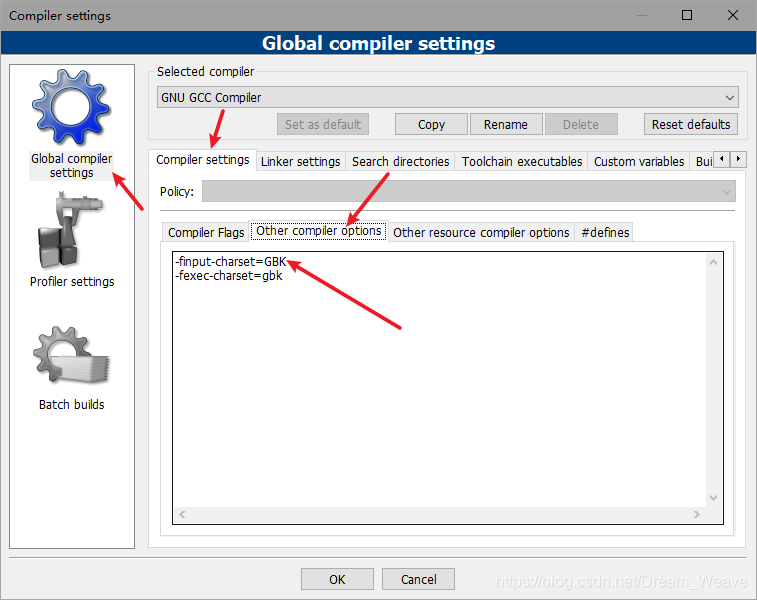
A lot of people also had coding problems before. Maybe this is UTF-8. Try GBK~
-Find put charset = GBK (or GB2312)
Argument interpolation should be of type InterpolationMode instead of int.
from torchvision.transforms import InterpolationMode
Image.BICUBIC
InterpolationMode.BICUBIC
First of all, there are two main concepts about MySQL character set, one is character sets, the other is collations, the former is character content
and encoding, and the latter is some rules for comparing the former. These two parameter sets can be specified at four levels: database instance, single database, table and column.
For users, utf8 encoding is generally recommended to store data. To solve the problem of garbled code, it is not only the storage of MySQL data, but also related to the coding mode of user program files and the connection mode between user program and MySQL database.
first of all, MySQL has a default character set, which is determined during installation. When compiling mysql, you can use default_ Charset =
utf8 and default_ COLLATION=utf8_ general_ CI (MySQL version 5.5, version 5.1 uses — with charset =
utf8 — with collation = utf8)_ general_ The default character set is utf8, which is also the most once and for all method. After this is specified,
the coding mode of client connecting to database is utf8 by default, and the application does not need any processing.
unfortunately, many people don’t specify these two parameters when compiling and installing mysql, and most people install it through binary programs.
at this time, the default character set of MySQL is Latin1. At this time, we can still specify the default character set of MySQL by my.cnf Add two parameters to the file:
1. Add
default character set = utf8 under [mysqld]
2. Add
default character set = utf8 under [Client]
2 In this way, we don’t need to specify utf8 character set when we build database and table. This writing method in the configuration file solves the problem of data storage and comparison
, but it has no effect on the connection of the client. At this time, the client usually needs to specify utf8 connection to avoid garbled code. This is the general set
Names command. In fact, the set names utf8 command corresponds to the following server-side commands:
set character_ set_ client = utf8;
SET character_ set_ results = utf8;
SET character_ set_ Connection = xutf8;
but these three parameters cannot be written in the configuration file my.cnf It’s in the library. It can only be modified dynamically by the set command. What we need is to write a way to
Yongyi in the configuration file. At this time, is there a way to solve the problem on the server?The feasible idea is in init_ Set in connect. This command will be triggered every time an ordinary user connects. You can add the following line in the [mysqld] section to set the connection character set:
Add under [mysqld]:
init_ Connect =’set names utf8 ‘
summary:
1. It is preferred to specify two parameters to use utf8 encoding when compiling and installing mysql.
2. Select in the configuration file my.cnf or my.ini Set two parameters and init at the same time_ Connect parameter.
3. The third is in the configuration file my.cnf or my.ini Set two parameters, and specify the set names command for the client connection.
4. In the configuration file my.cnf The default character set parameter is added to the client and server in to facilitate management.
First let’s look at the official definition:
Grammatical definitions:
Definition:
> Mysqli_connect_error () : The function returns an error description of the last connection error.
> Mysqli_connect_errno () : The function returns the error code for the last connection error.
Note: One returns an error description and the other an error code.
camera.close()
When
runs again, an error may occur:
picamera.exc.PiCameraMMALError: Failed to enable connection: Out of resource
solution:
just find and kill the process where the Camera is.
step1: ps -u
find the corresponding python PID, such as 14255
step2: kill 14255
step3: re-run, problem solved
E/ART:向调试器发送回复失败:管道损坏。
what is E/ART?
ART is </ strong> A ndroid – [R not Ť IME. This is the Android phones bytecode interpreter. E just means the ERROR record level. </ strong> </ strong> </ strong> </ p>
what is the send reply debugger?
debugging on Android phones is using adb (Android debugging bridge). Adb processes run on your development computer (your laptop or PC), and daemons run on Android devices (that is, emulators or phones).
what is a broken pipe?
Your development machine and Android device communicate like a client server. corrupt pipe indicates that the communication has become invalid. For example, the client (Android device) is trying to send a reply to the server (adb process running on the development machine), but the server has closed the socket.
by performing cleanup/rebuild
Then, if you are running an application using USB debugging on a real phone, you can usually solve the problem by unplugging the USB cable and re-inserting it to re-establish the client/server connection.
If this doesn’t work, you can disconnect the USB cable (stop the emulator if necessary) and close Android Studio. This is usually enough to block the ADB process. Then, when you open Android Studio again, it will restart and re-establish the connection.
if this does not work, you can try to use the instructions to manually stop the adb server in this problem. For example, you could try to open a command prompt or terminal, then go to the SDK/platform-tools directory and type:
adb kill-server
adb start-server*The daemon is not running; tcp:5037 is now started.
*Successful start of the daemon
When this appears.