Vite build & Flask Error: Failed to load module script. Strict MIME type checking is enforced
Stack Overflow
questions
I have this HTML:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<link
rel="stylesheet"
href="../../../static/css/style.css"
type="text/css" />
<link
rel="stylesheet"
href="../../../static/css/user_header.css"
type="text/css" />
<!--suppress HtmlUnknownTarget -->
<link rel="shortcut icon" href="/favicon.png">
<script type="module" src="../../../static/js/node_connect.js" ></script> <-- Error
<script src="../../../static/lib/jquery.min.js"></script>
<script src="../../../static/lib/selfserve.js"></script>
</head>
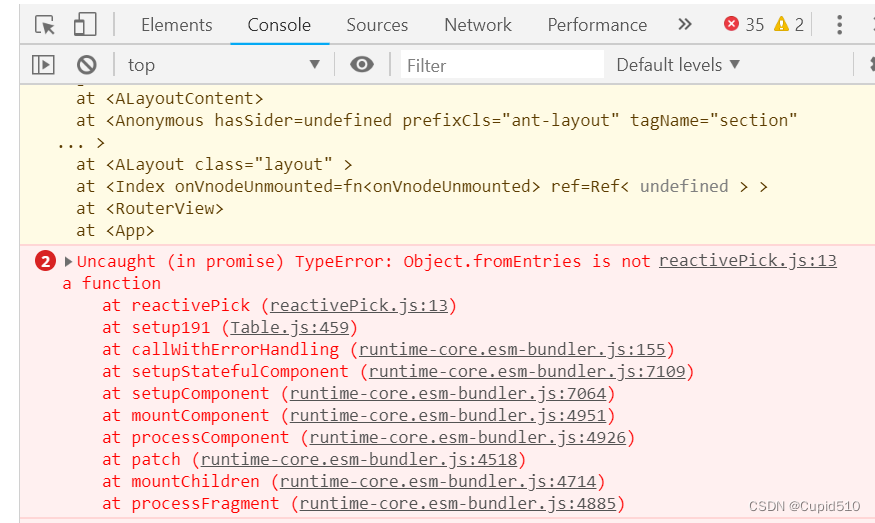
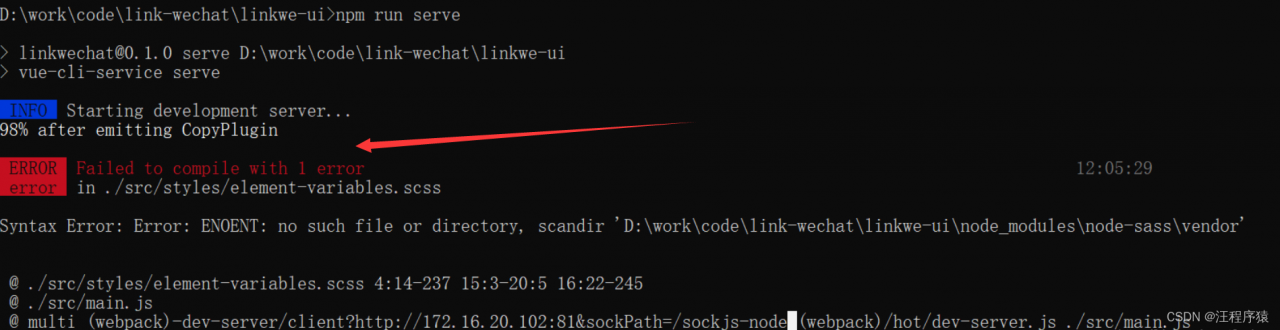
The problem is node_connect.jsfile. Start the flash web tool locally (Python 3.7.2), and the console will report the following error when opening the page:
Failed to load module script: The server responded with a non-JavaScript MIME type of "text/plain".
Strict MIME type checking is enforced for module scripts per HTML spec.
Check Title:
Content-Type: text/plain; charset=utf-8
However, in production (when starting through gunicorn), it gives:
Content-Type: application/javascript; charset=utf-8
I guess the web server (APACHE) serves them in the production case, but another thing is that when testing other pages of the web tool, they all work and load JavaScript files correctly (even if their content type is text/plain text). However, the difference is that I notice that in the type.
This applies to my situation:
<script src="../../static/js/translator/library/materialize.js"></script>
Or this:
<script type="application/javascript" src="../../static/js/translator/library/materialize.js"></script>
Of course, I tried this for the problematic JavaScript . File and received the following error (which means it is now loaded):
Uncaught SyntaxError: Cannot use import statement outside a module
According to my research, this basically means that I need to set the type to module (but this will make the browser reject .js files).
Who can help me solve this problem?
best answer:
The problem is caused by flash how to guess the content type of each static file
Import mimetypes from flash and call mimeType, encoding = mimetypes guess_type (download_name) this module creates a database of known MIME types from multiple sources and uses it to return MIME types
Linux and MacOS: look at the mimetypes.py files:
knownfiles = [
"/etc/mime.types",
"/etc/httpd/mime.types", # Mac OS X
"/etc/httpd/conf/mime.types", # Apache
"/etc/apache/mime.types", # Apache 1
"/etc/apache2/mime.types", # Apache 2
"/usr/local/etc/httpd/conf/mime.types",
"/usr/local/lib/netscape/mime.types",
"/usr/local/etc/httpd/conf/mime.types", # Apache 1.2
"/usr/local/etc/mime.types", # Apache 1.3
]
But in windows, it will look in the registry:
with _winreg.OpenKey(_winreg.HKEY_CLASSES_ROOT, '') as hkcr:
for subkeyname in enum_types(hkcr):
try:
with _winreg.OpenKey(hkcr, subkeyname) as subkey:
# Only check file extensions
if not subkeyname.startswith("."):
continue
# raises OSError if no 'Content Type' value
mimetype, datatype = _winreg.QueryValueEx(
subkey, 'Content Type')
if datatype != _winreg.REG_SZ:
continue
self.add_type(mimetype, subkeyname, strict)
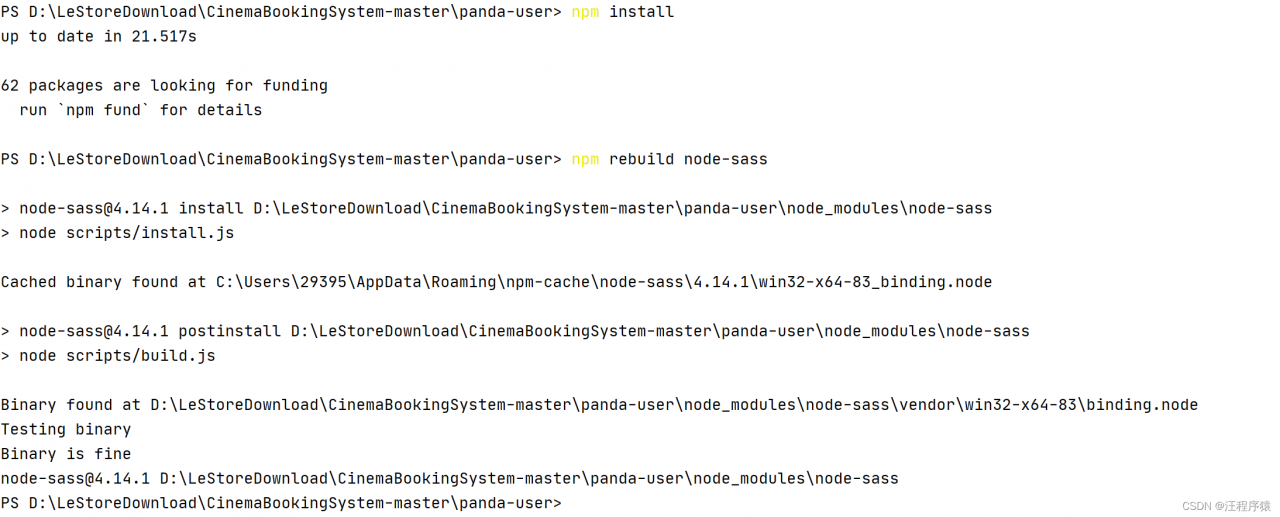
So to solve the problem, flask thinks JS file is actually a problem of text/plain , just open regedit and adjust this registry key to application/javaScript .
solutions for vite:
Find the registry value, double-click content type to change it to Application/JavaScript , and then restart the computer
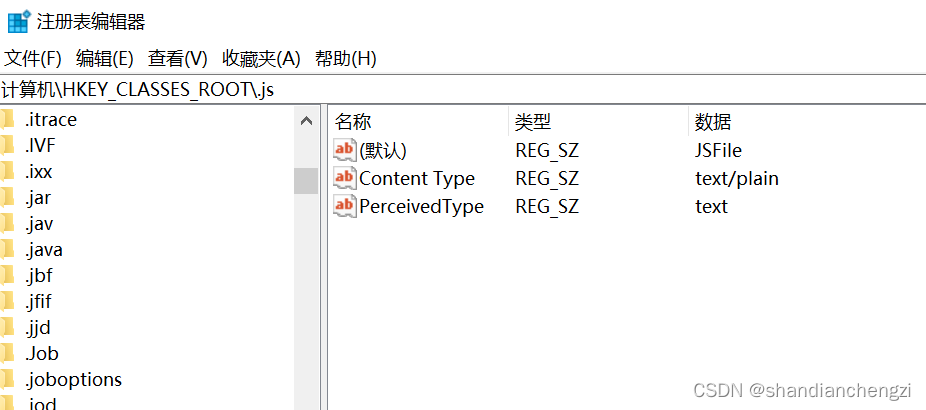
if not, please see if your suffix is simple .js, if it is .1242342.js , must be changed to pure .JS suffix can take effect
In order to completely eradicate the disadvantages of modifying files, we can change the configuration file of vite , and modify the name of the output JS file by using the custom packaging option rollupOptions.
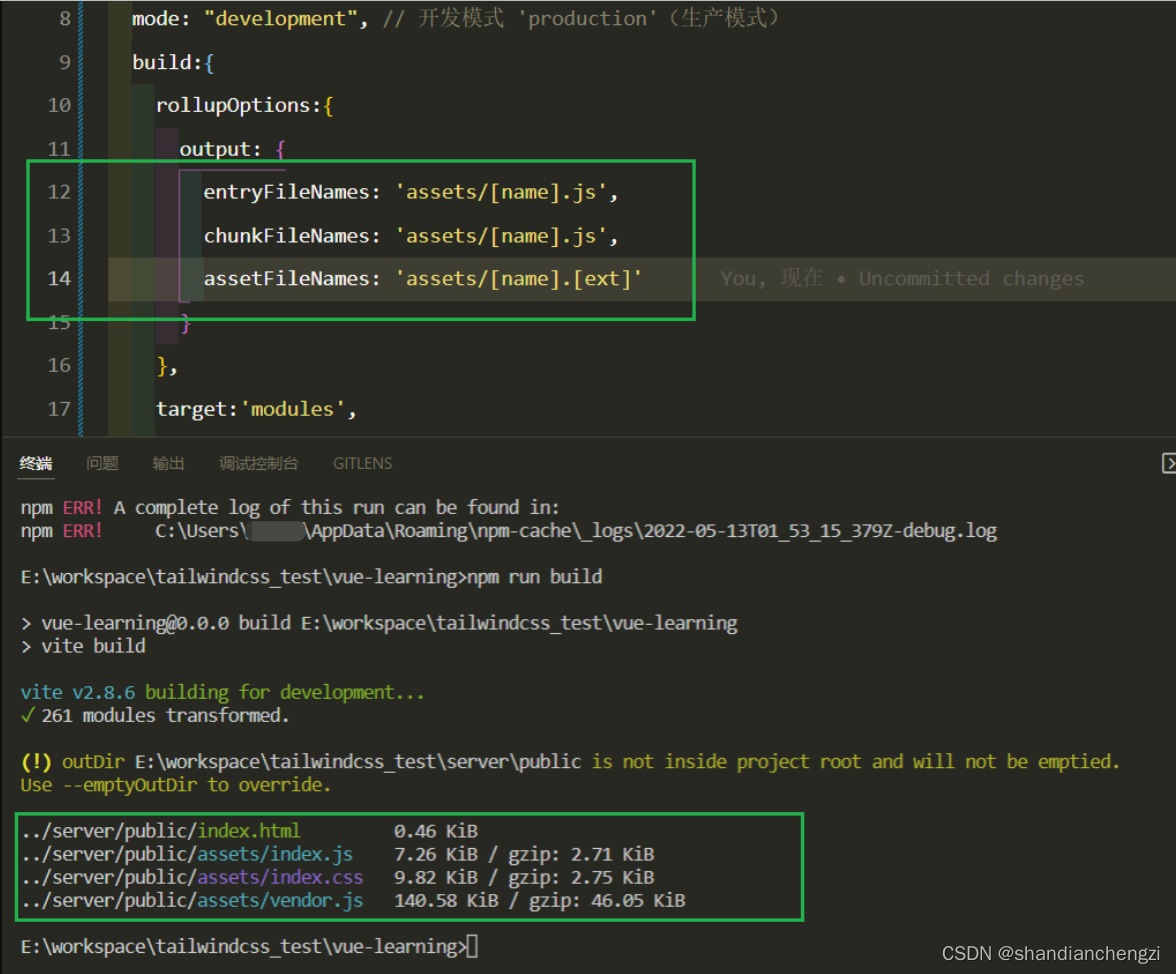
Reference: vite2 how to set the file name after packaging
Other configuration items of vite.config.js are shown on the official website. Click here to view more configuration items on the official website.