Exception in thread “main” org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
Exchange hashpartitioning(subject#6, 200)
+- *HashAggregate(keys=[subject#6, name#7], functions=[count(1)], output=[subject#6, name#7, c#12L])
+- Exchange hashpartitioning(subject#6, name#7, 200)
+- *HashAggregate(keys=[subject#6, name#7], functions=[partial_count(1)], output=[subject#6, name#7, count#43L])
+- *Project [_1#3 AS subject#6, _2#4 AS name#7]
+- *SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._1, true) AS _1#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#4]
+- Scan ExternalRDDScan[obj#2]Caused by: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
Caused by: org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://leetom:8020/user/root/file/dataSource/teacher.txt
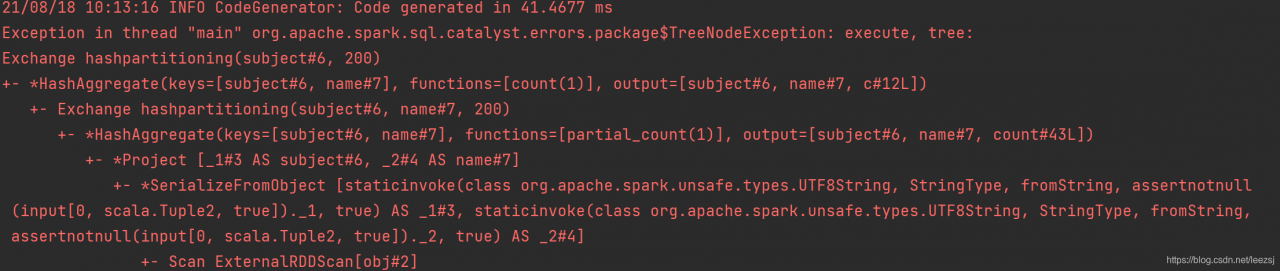


Exchange hashpartitioning(subject#6, 200)
+- *HashAggregate(keys=[subject#6, name#7], functions=[count(1)], output=[subject#6, name#7, c#12L])
+- Exchange hashpartitioning(subject#6, name#7, 200)
+- *HashAggregate(keys=[subject#6, name#7], functions=[partial_count(1)], output=[subject#6, name#7, count#43L])
+- *Project [_1#3 AS subject#6, _2#4 AS name#7]
+- *SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._1, true) AS _1#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#4]
+- Scan ExternalRDDScan[obj#2]Caused by: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
Caused by: org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://leetom:8020/user/root/file/dataSource/teacher.txt

Modify:
