The questions are as follows:
1. The problems are as follows:
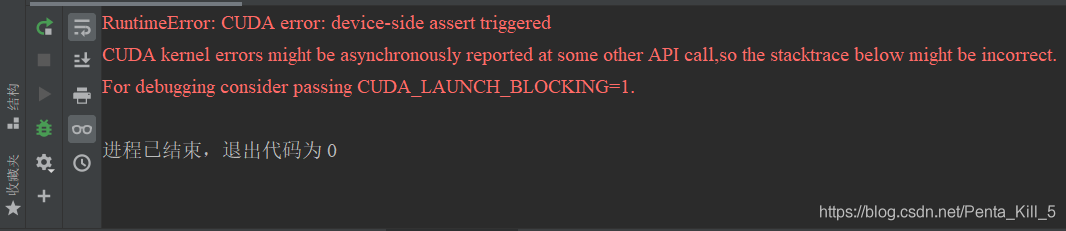
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_ LAUNCH_ BLOCKING=1.
2. Solution:
(1) At the beginning, I searched for solutions on the Internet. As a result, most netizens’ solutions are similar to this:
Some people say that the reason for this problem is that there are tags exceeding the number of categories in the training data when doing the classification task. For example: if you set up a total of 8 classes, but there is 9 in the tag in the training data, this error will be reported. So here’s the problem. There’s a trap. If the tag in the training data contains 0, the above error will also be reported. This is very weird. Generally, we start counting from 0, but in Python, the category labels below 0 have to report an error. So if the category label starts from 0, add 1 to all category labels.
Python scans the train itself_ Each folder under path (each type of picture is under its category folder), and map each class to a numerical value. For example, there are four categories, and the category label is [0,1,2,3]. In the second classification, the label is mapped to [0,1], but in the fourth classification, the label is mapped to [1,2,3,4], so an error will be reported.
(2) In fact, it’s useless for me to solve the same problem that I still report an error. Later, I looked up the code carefully and found that it was not the label that didn’t match the category of the classification, but there was a problem with the code of the last layer of the network. If you want to output the categories, you should fill in the categories.
self.outlayer = nn.Linear(256 * 1 * 1, 3) # The final fully connected layer
# Others are 3 categories, while mine is 5 categories, corrected here to solve
self.outlayer = nn.Linear(256 * 1 * 1, 5) # The last fully connected layer(3) It’s actually a small problem, but it’s been working for a long time. Let’s make a record here. The actual situation after the solution:
Read More:
- [Solved] torch Do Targer Detection Error: RuntimeError: CUDA error: device-side assert triggered
- [Solved] CUDA error: device side assert triggered classification task error
- Deep learning model error + 1: CUDA error: device side assert triggered
- [Solved] RuntimeError: CUDA error: invalid device ordinal
- TensorFlow-gpu Error: failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
- Cuda Runtime error (38) : no CUDA-capable device is detected
- [Solved] RuntimeError: CUDA error: out of memory
- PyCharm Error: RuntimeError: CUDA out of memory [How to Solve]
- [Solved] RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
- [Solved] RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and
- [Solved] CUDA error:-UserWarning: CUDA initialization: CUDA unknown error
- [Solved] UserWarning: CUDA initialization: CUDA unknown error
- Audit reported an error: “the device settings could not be applied because of the following error: Mme device internal error“
- [Solved] std::max() error C2589: ‘(‘ : illegal token on right side of ‘::‘
- [Solved] selenium.common.exceptions.WebDriverException: Message: An unknown server-side error
- [Solved] Bringing up interface eth0: Error: No suitable device found: no device found for connection ‘System eth0’.
- [Solved] MindSpore Error: “RuntimeError: Unable to data from Generator..”
- CUDA_ERROR_SYSTEM_DRIVER_MISMATCH [How to Solve]
- [Solved] appium Error: An unknown server-side error occurred while processing the command
- [Solved] NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL ,unhandled cuda error, NCCLversion 2.7.8