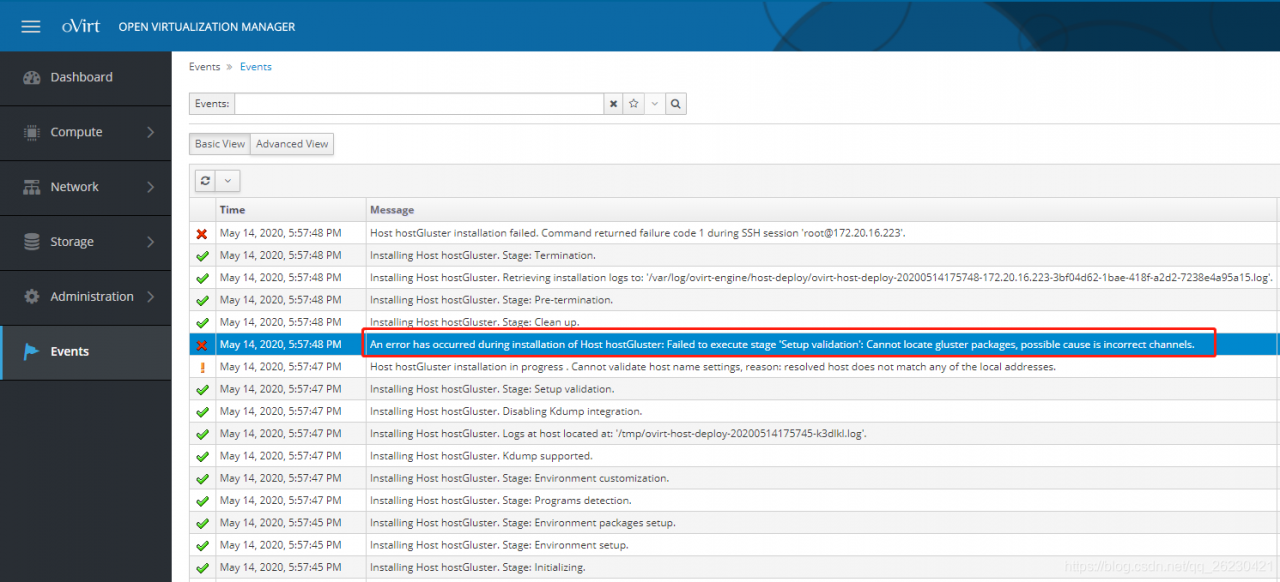
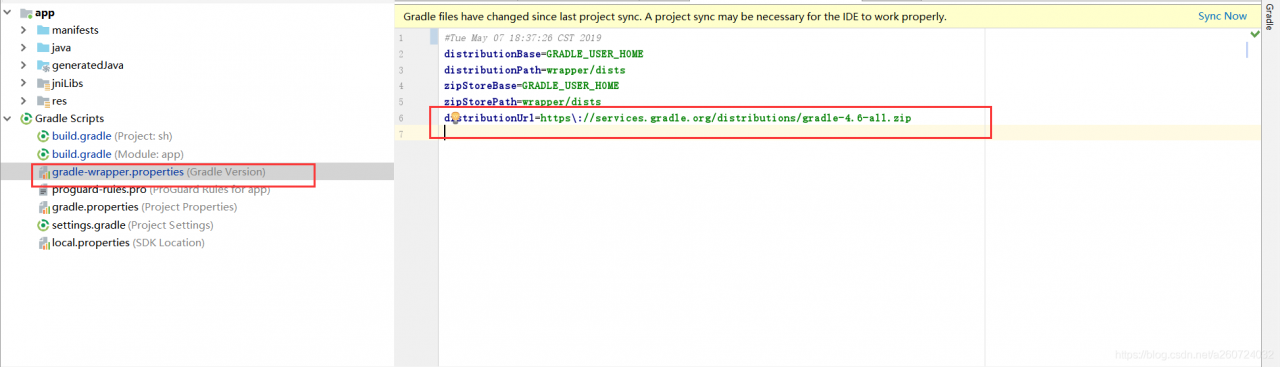
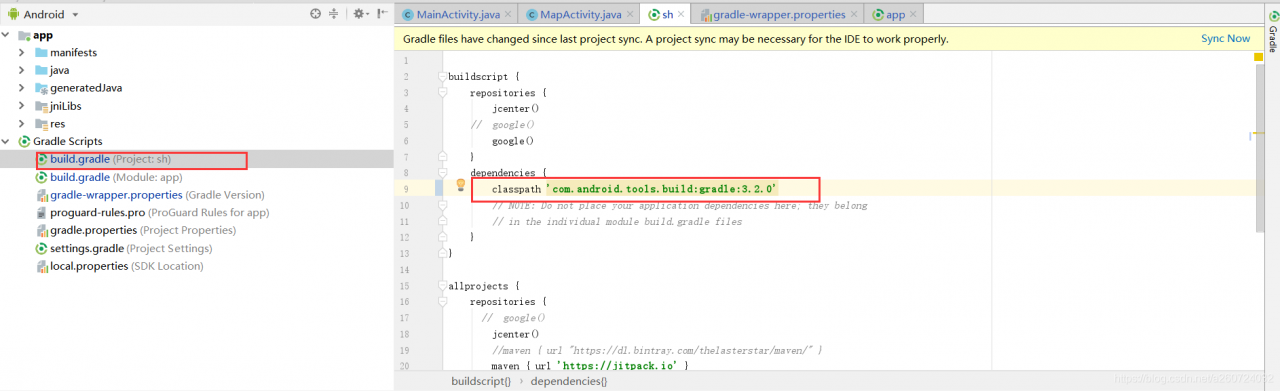
When using spring cloud, we first create a parent project, and then add Eureka server module and SMS module, which run normally. Finally, after adding the payment module (mybatis and MySQL need to be integrated), the Eureka server module and SMS module report an error:
Description:
Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured.
Reason: Failed to determine a suitable driver class
Action:
Consider the following:
If you want an embedded database (H2, HSQL or Derby), please put it on the classpath.
If you have database settings to be loaded from a particular profile you may need to activate it (no profiles are currently active).After investigation, because mybatis jar package is introduced:
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
</dependency>Spring boot will load by default org.springframework.boot . autoconfigure.jdbc.DataSourceAutoConfiguration and the datasourceautoconfiguration class uses the @ configuration annotation to inject datasource into spring Bean, and because there is no configuration information about datasource in the project (Eureka server module and SMS module), when spring creates datasource bean, it will report an error due to lack of relevant information.
terms of settlement:
1. Add exclude to the @ springbootapplication annotation to release the automatic loading of datasourceautoconfiguration.
@EnableEurekaServer
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}2. In the pom.xml The common jar dependencies of all sub modules are stored in the file, and the non common dependencies are stored in the file of each module itself pom.xml It is stated in the document. The advantage of this method is that the dependence of each module will not interfere with each other.