An error is reported related to flick serialization
Problem solving run code error reporting content solution custom implementation serialization re-execute code
The problem goes deep into why the error is thrown, why the source of the error needs to be serialized, and why the closure needs to be cleaned up
Problem-solving
Run code
public class JavaSourceEx {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1)use fromCollection(Collection) to read datas
//ArrayList<String> list = new ArrayList<>();
//list.add("hello");list.add("word");list.add("cctv");
//DataStreamSource<String> stream01 = env.fromCollection(list);
// 2)use fromCollection(Iterator, Class) to read datas
Iterator<String> it = list.iterator();
DataStreamSource<String> stream02 = env.fromCollection(it, TypeInformation.of(String.class));
stream02.print().setParallelism(1);
env.execute();
}
}
Error content
Exception in thread "main" org.apache.flink.api.common.InvalidProgramException: java.util.ArrayList$Itr@a1cdc6d is not serializable. The implementation accesses fields of its enclosing class, which is a common reason for non-serializability. A common solution is to make the function a proper (non-inner) class, or a static inner class.
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:164)
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:132)
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:69)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.clean(StreamExecutionEnvironment.java:2053)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.addSource(StreamExecutionEnvironment.java:1737)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.fromCollection(StreamExecutionEnvironment.java:1147)
at Examples.JavaSourceEx.main(JavaSourceEx.java:30)
Caused by: java.io.NotSerializableException: java.util.ArrayList$Itr
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1184)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at org.apache.flink.util.InstantiationUtil.serializeObject(InstantiationUtil.java:624)
at org.apache.flink.api.java.ClosureCleaner.clean(ClosureCleaner.java:143)
... 6 more
Process finished with exit code 1
Solution
If reading data from an internal container:
1) the official flick also provides the following methods: from collection (Collection) , you can replace the method of reading data from the iterator with this method
2) the reason for the error is that the iterator does not implement the serial machine interface. The container has implemented serialization, but the iterator has not been implemented. Therefore, if you want to use it, you need to customize the iterator and implement the serialization interface. This operation is redundant, so it is recommended to solve it according to the first method
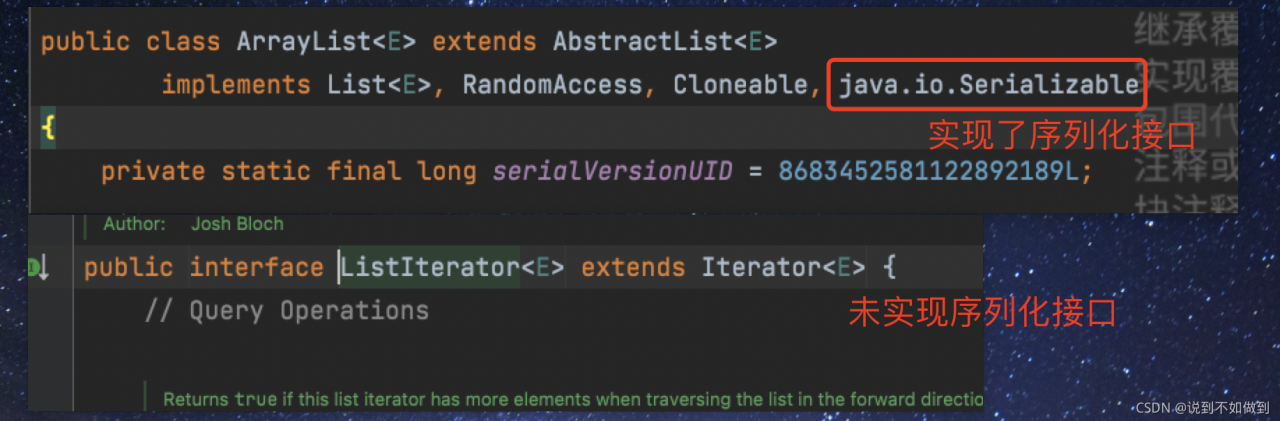
Custom implementation serialization
package Examples.Utils;
import com.sun.org.apache.xpath.internal.functions.WrongNumberArgsException;
import com.sun.tools.jdi.EventSetImpl;
import java.io.Serializable;
import java.util.Arrays;
import java.util.Iterator;
public class MyListItr<T> implements Serializable{
private static int default_capacity = 10;
private int size = 0;
private Object[] elements;
public MyListItr(){
this.elements = new Object[default_capacity];
}
public MyListItr(int capa){
this.default_capacity = capa;
this.elements = new Object[default_capacity];
}
public int size(){
return this.size;
}
public T get(int index) throws MyException {
if(index<0){
throw new MyException("Index given cannot be less than 0");
}
if(index>=size){
throw new MyException("Index given cannot be larger than or equal to the collection size");
}
return (T)elements[index];
}
public T add(T ele){
if(size == default_capacity){
elements = Arrays.copyOf(elements,default_capacity*2);
default_capacity *=2;
elements[size++] = ele;
}else{
elements[size++] = ele;
}
return (T)ele;
}
public Iterator iterator(){
return new Itr();
}
private class Itr implements Iterator<T>, Serializable {
int cursor;
Itr(){}
@Override
public boolean hasNext() {
return cursor!=size();
}
@Override
public T next() {
return (T)elements[cursor++];
}
}
public static void main(String[] args) throws MyException {
MyListItr<Integer> obj = new MyListItr<>();
obj.add(1);
obj.add(2);
System.out.println(obj.get(0));
obj.add(3);
Iterator it = obj.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
class MyException extends Exception implements Serializable{
public MyException(String message) {
super(message);
}
}
Re execute the code
MyListItr<Integer> myList = new MyListItr<>();
myList.add(1);myList.add(2);myList.add(3);
Iterator<Integer> it02 = myList.iterator();
DataStreamSource<Integer> stream02 = env.fromCollection(it02, TypeInformation.of(Integer.class));
stream02.print().setParallelism(1);
env.execute();
Can run:

Problem depth
Why is this error thrown
To put it in-depth, Java needs to run on the JVM platform and be interpreted and run by the JVM in the form of bytecode. Because Flink is a distributed computing, the data in map and other operators will be distributed among various network nodes for computing. In addition, after the source code of Flink is compiled into a bytecode file, you can see from the bytecode file of the operator that the read object enters the operator, and all objects entering the operator must be serialized. If there is no serialization, an error is thrown.
Why serialization
In distributed computing, such as spark, MapReduce, Flink and other computing prerequisites, the serializability of computing objects needs to be realized. Serialization is to reduce the delay, loss and resource consumption caused by data transmission and exchange in network nodes. Objects that are not serialized will not be distributed in network nodes.
The error is thrown from the source
This error is caused by the error when Flink executes closure cleanup logic. The specific logic is in this class: org. Apache. Flink. API. Java. Closurecleaner .
Why clean up closures
Many times, anonymous classes or nested subclasses are used for convenience and quickness. When class a needs to be serialized for transmission, it also needs internal subclasses to be serialized. However, some unnecessary classes or unnecessary variable information may be referenced in general nested classes, so it is necessary to clean up Flink to save the cost of serialization.
Read More:
- How to Solve JAR pack error: Error resolving template [/userInfo], template might not exist or might not be accessib
- How to Solve Mybatis error: invalid bound statement (not found)
- How to Solve Tomcat Error: Could not resolve view with name ‘xxx/xxxxxxx‘ in servlet with
- How to Solve Flynk Task Java verifyerror 209 error
- JAVA: How to Solve Foreach Loop Remove/add Element Error
- How to Solve Error: Invalid bound statement (not found)
- Flink Error: is not serializable. The object probably contains or references non serializable fields.
- How to Solve Error:java.io.InvalidClassException
- How to Solve Springboot Upload Files Error: The field XXX exceeds its maximum permitted size of 1048576 bytes
- [Solved] Jedis connect and operate Redis error: Failed to create socket和connect timed out
- How to Solve JUnit Debugging initializationerror ERROR
- How to Solve JVM Common Errors: outofmemoryerror & stackoverflowerror
- How to Solve classnotfoundexception error in spark without Hadoop runtime
- How to Solve Log4j 2.5 upgrade to 2.15 error
- How to Solve Mockito mockedStatic NotAMockException Error
- How to Solve Swagger error: IllegalStateException
- How to Solve Error: Your ApplicationContext is unlikely to start due to a @ComponentScan of the default package.
- How to Solve shiro Set sessionIdUrlRewritingEnabled Error (jessionid Removed)
- How to Solve ERROR: Java 1.7 or later is required to run Apache Drill
- How to Solve Java Runtime (class file version 53.0)ERROR