The background,
The business needs to aggregate the data by grouping the results within the group by its own defined calculation method
Second, code implementation
 The reference code is as follows:
The reference code is as follows:
The business needs to aggregate the data by grouping the results within the group by its own defined calculation method
Second, code implementation
The reference code is as follows:
# Read source files
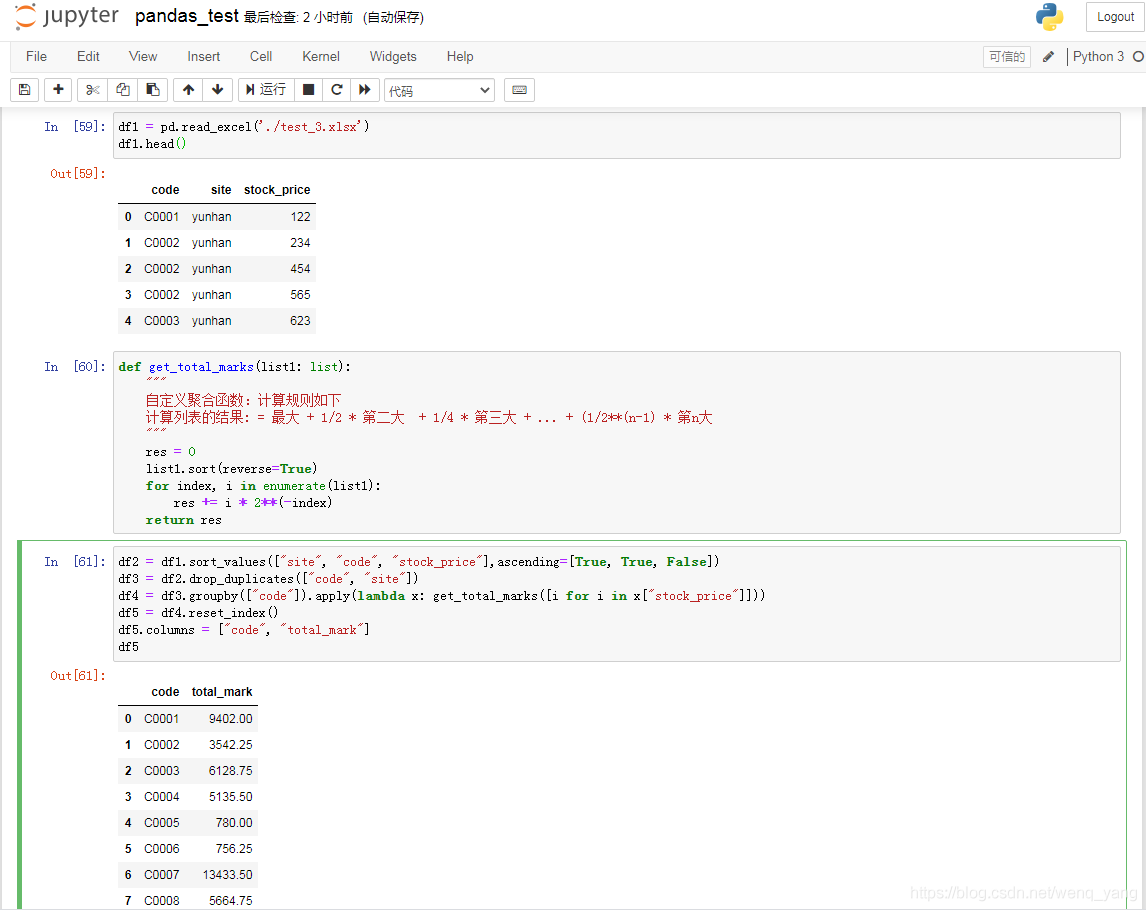
df1 = pd.read_excel('./test_3.xlsx')
df1.head()
# Custom aggregate functions
def get_total_marks(list1: list):
"""
Custom aggregate functions: Calculate the rules as follows
Result of calculating the list: = largest + 1/2 * second largest + 1/4 * third largest + ... + (1/2**(n-1) * nth largest
"""
res = 0
list1.sort(reverse=True)
for index, i in enumerate(list1):
res += i * 2**(-index)
return res
# Using dataframe aggregation
df2 = df1.sort_values(["site", "code", "stock_price"],ascending=[True, True, False])
df3 = df2.drop_duplicates(["code", "site"])
df4 = df3.groupby(["code"]).apply(lambda x: get_total_marks([i for i in x["stock_price"]]))
df5 = df4.reset_index()
df5.columns = ["code", "total_mark"]
df5
After groupBY, you can use the Apply () method, which allows you to pass in a function. If the normal sum(), Max (), and mean() do not satisfy your needs, you can consider custom functions to complete the aggregation.
Read More:
- To customize the aggregate function of Flink (Step-by-Step Tutorial)
- error: aggregate value used where an integer was expected
- Methods of modifying index and columns names by dataframe in pandas
- Three methods of converting dict into dataframe by pandas
- Summary of three methods for pandas to convert dict into dataframe
- Dataframe and np.array The mutual transformation of
- Attributeerror: ‘dataframe’ object has no attribute ‘IX’ error
- In pandas, dataframe and np.array The mutual transformation between the two
- Python data analysis dataframe converts dates to weeks
- Dataframe to numpy.ndarray Related issues of
- Hexo + next add bilibilibili icon through custom style
- Mybatis custom list collection parser
- Python – get the information of calling function from called function
- Golang timer function executes a function every few minutes
- Error handling after mybatis custom paging plug-in
- Deep learning: derivation of sigmoid function and loss function
- Modify the custom keyboard shortcut of visual studio code
- How to Add custom middleware for GRPC server
- Python custom class typeerror: ‘module’ object is not callable
- Ioremap function and iounmap() function