Error: cv2.error: OpenCV(4.5.4) /tmp/pip-req-build-w88qv8vs/opencv/modules/highgui/src/window.cpp:1006: error: (-215:Assertion failed) size.width>0 && size.height>0 in function ‘imshow’
Check if there is a problem with the image path:
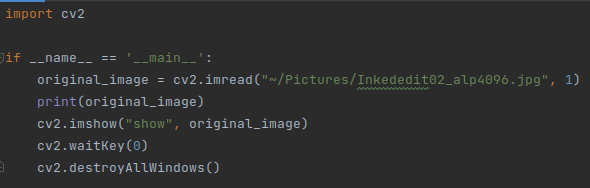
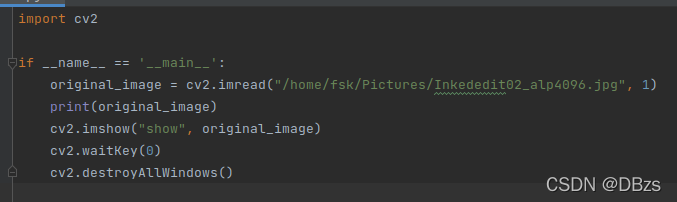
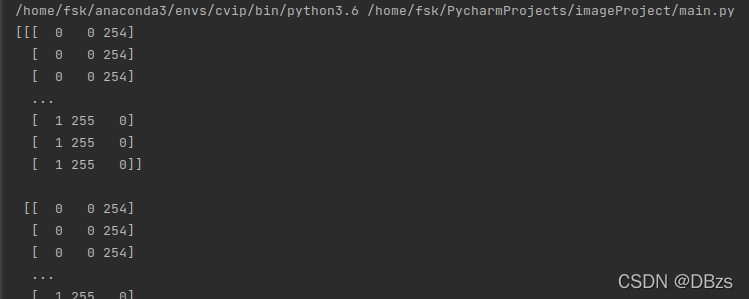
 It is found that None ==> You cannot use “~” to formulate the path, just modify it to the full path:
It is found that None ==> You cannot use “~” to formulate the path, just modify it to the full path:
Category Archives: Python
HDF5 library version mismatched error [How to Solve]
HDF5 library version mismatched error
Error Messages:
Warning! ***HDF5 library version mismatched error***
The HDF5 header files used to compile this application do not match
the version used by the HDF5 library to which this application is linked.
Data corruption or segmentation faults may occur if the application continues.
This can happen when an application was compiled by one version of HDF5 but
linked with a different version of static or shared HDF5 library.
You should recompile the application or check your shared library related
settings such as 'LD_LIBRARY_PATH'.
You can, at your own risk, disable this warning by setting the environment
variable 'HDF5_DISABLE_VERSION_CHECK' to a value of '1'.
Setting it to 2 or higher will suppress the warning messages totally.
Headers are 1.10.2, library is 1.10.5
Solution:
pip uninstall h5py
pip install h5py
visdom Install and Run Error: raise Connectionerror [How to Solve]
Install visdom
Switch to the environment corresponding to CONDA and use CONDA install visdom. An error is reported and the installation cannot be performed. After query, it is found that the installation can be successful using pip. For some reason, the command is as follows:
pip install visdomRun visdom
If you want to use visdom in Python code, you must first start the visdom service in the CONDA environment where visdom is installed:
python -m visdom.serverAfter the service is started, the following prompt will be given:
39: DeprecationWarning: zmq.eventloop.ioloop is deprecated in pyzmq 17. pyzmq now works with default tornado and asyncio eventloops.
ioloop.install() # Needs to happen before any tornado imports!
Checking for scripts.
Downloading scripts, this may take a little while
It's Alive!
INFO:root:Application Started
You can navigate to http://localhost:8097
Then you can open it in the browser http://localhost:8097 Address and access visual content
If you do not run the above command, the following error will be reported:
Traceback (most recent call last):
File "D:\program\conda\envs\python36_gan\lib\site-packages\visdom\__init__.py", line 711, in _send
data=json.dumps(msg),
File "D:\program\conda\envs\python36_gan\lib\site-packages\visdom\__init__.py", line 677, in _handle_post
r = self.session.post(url, data=data)
File "D:\program\conda\envs\python36_gan\lib\site-packages\requests\sessions.py", line 581, in post
return self.request('POST', url, data=data, json=json, **kwargs)
File "D:\program\conda\envs\python36_gan\lib\site-packages\requests\sessions.py", line 533, in request
resp = self.send(prep, **send_kwargs)
File "D:\program\conda\envs\python36_gan\lib\site-packages\requests\sessions.py", line 646, in send
r = adapter.send(request, **kwargs)
File "D:\program\conda\envs\python36_gan\lib\site-packages\requests\adapters.py", line 516, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPConnectionPool(host='localhost', port=8097): Max retries exceeded with url: /env/test1 (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x0000025
321093898>: Failed to establish a new connection: [WinError 10061] Unable to connect because the target computer actively refused.',))
[WinError 10061] Unable to connect because the target computer actively refused.
Exception in user code:
------------------------------------------------------------
Traceback (most recent call last):
File "D:\program\conda\envs\python36_gan\lib\site-packages\urllib3\connection.py", line 157, in _new_conn
(self._dns_host, self.port), self.timeout, **extra_kw
File "D:\program\conda\envs\python36_gan\lib\site-packages\urllib3\util\connection.py", line 84, in create_connection
raise err
File "D:\program\conda\envs\python36_gan\lib\site-packages\urllib3\util\connection.py", line 74, in create_connection
sock.connect(sa)
ConnectionRefusedError: [WinError 10061] Unable to connect because the target computer actively refused.
During handling of the above exception, another exception occurred:
[Solved] DDP/DistributedDataParallel Error: RuntimeError: Address already in use
An error is reported when testing pytorch multi card:
store = tcpstore (master_addr, master_port, world_size, start_daemon, timeout)
runtimeerror: address already in use
After investigation, there is another task running with DDP.
Solution:
manually specify an idle port
python -m torch.distributed.launch --master_port 145622
View port occupancy:
terminal input
netstat - nultp
[Solved] Fatal error C1001 internal error occurred in the compiler openmesh6 three
Internal Compiler Error VS 2015 Update1
VS2015 Update1 An error occurred when compiling the OpenMesh code:
fatal error c1001 An internal error occurred in the compiler OpenMesh6.3
(compiler file ‘f:\dd\vctools\compiler\cxxfe\sl\p1\c\special.c’, line 6211)
1> To work around this problem, try simplifying or changing the program near the locations listed above.
The reason is that codes such as this appear
OpenMesh::Vec3f normal[4];Solution: change this kind of code to the following.
OpenMesh::Vec3f normal[4] = { {},{},{},{} };[Solved] ERROR: THESE PACKAGES DO NOT MATCH THE HASHES FROM THE REQUIREMENTS FILE
pip Install tensorflow Error:
ERROR: THESE PACKAGES DO NOT MATCH THE HASHES FROM THE REQUIREMENTS FILE. If you have updated the package versions, please update the hashes. Otherwise, examine the package contents carefully; someone may have tampered with them. tensorflow<1.14,>=1.13 from https://www.piwheels.org/simple/tensorflow/tensorflow-1.13.1-cp35-none-linux_armv7l.whl#sha256=6c00dd13db0791e83cb08d532f007cc7fd44c8d7b52662a4a0065ac4fe7ca18a (from mycroft-precise==0.3.0): Expected sha256 6c00dd13db0791e83cb08d532f007cc7fd44c8d7b52662a4a0065ac4fe7ca18a Got f679035a7cd96d24f826463bef208cd04f1eee50eb6023a158c05b529e17a71b
The above error shows that the expected hash value when downloading the package is not the real hash, the package is damaged during pip installation, and it may also be caused by its own network problem or the version compatibility of the Python package.
Solution: Add a --no-cahce-dir when installing the pip package to solve the problem as follows:
pip install tensorflow --no-cache-dir
[Solved] AttributeError: ‘DataParallel‘ object has no attribute ‘save‘
Error message:
trainer.model.save(self.dir, epoch, is_best=is_best)
AttributeError: 'DataParallel' object has no attribute 'save'
Source code analysis:
trainer.model.save(self.dir, epoch, is_best=is_best)The above code is the code before using single machine multi card parallel. My parallel code is implemented as follows:
os.environ["CUDA_VISIBLE_DEVICES"] = "3,2,1"
model = torch.nn.DataParallel(model,device_ids=[0,1]).cuda()Cause analysis: attributeerror: ‘dataparallel’ object has no attribute ‘save‘
Under torch multi GPU training, the whole model is stored instead of the model state_Dict(), so we need to use model when calling model Module mode. After using the above modification method, the code is as follows:
trainer.model.module.save(self.dir, epoch, is_best=is_best)[Solved] FLask Error: AttributeError: ‘Blueprint‘ object has no attribute ‘register_blueprint‘
Recently, a flash was deployed on alicloud, and an error was reported during startup
AttributeError: ‘Blueprint’ object has no attribute ‘register_blueprint’
I checked the location. There was an error below!
admin_bp = Blueprint('admin',__name__)
admin_bp.register_blueprint(activity_bp,url_prefix='/activity')First of all, there is no problem running locally. When uploading to the server (CentOS 7, py39), an error is reported. Maybe it is because it is not standardized, but it should also be reported on the window. I don’t understand.
Solution:
Blueprint cannot call Method of register_blueprint(), register_Blueprint() is handed over to the app, and this line is moved to the place where the app is referenced
app.register_blueprint(activity_bp,url_prefix='/activity')This should be no problem!
[Solved] Error c2039: ‘bind2nd’: not a member of ‘STD’
The following error occurred in vs2012:
Error c2039: ‘bind2nd’: not a member of ‘STD’
Add in header file
#include <functional>
[Solved] django AttributeError: ‘UserComment‘ object has no attribute ‘save‘
Change to modelform, and the code in views is as follows:
form.instance.comment_man = request.user form.instance.comment_course_id = couseid form.instance.comment_comment = textcontent form.instance.add_time = timezone.now() form.save()
[Solved] flask db migrate execute error: ERROR [flask_migrate] Error: Can‘t locate revision identified by ‘8d1ad59dc71a‘
Recently, a new table has been added to the flash project, but an error is reported when executing flash DB migrate, as shown in the following figure:

Google around the Internet and finally know the problem:
although the migration directory in the project has been deleted, the version information has been saved in the database. Yes, this is the table – alembic_ version
So all you have to do is delete the version record of this table:
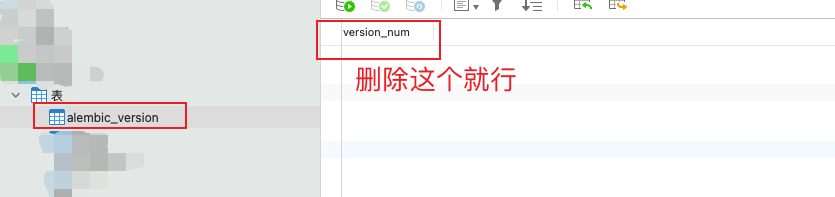
After deletion, execute flash DB migrate again, no error is reported, and the table is generated normally ~

RuntimeError: NCCL Error 2: unhandled system error [How to Solve]
Running yolov5 code reports an error
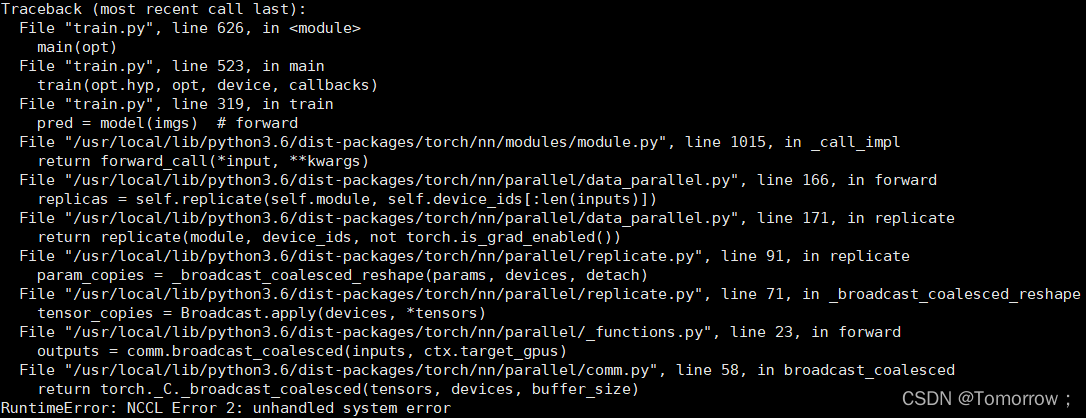
find nccl position according to the error reminder
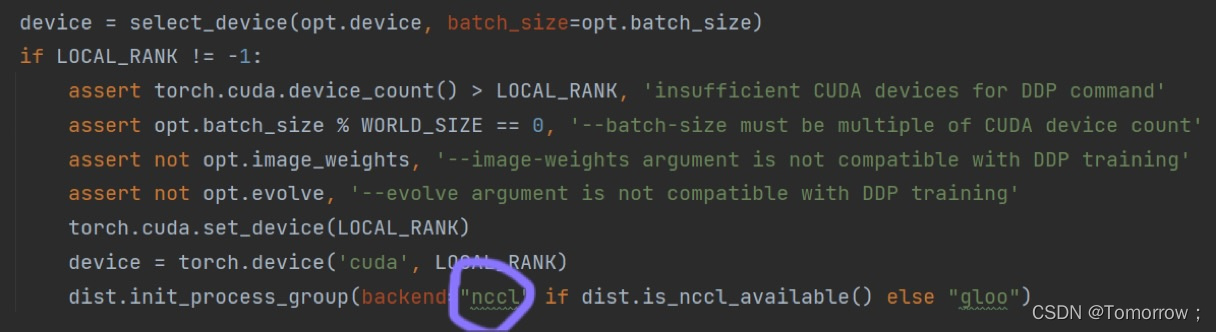
then it reacts that it is a problem of calling GPU, so it is changed to single GPU training

so it can run perfectly.